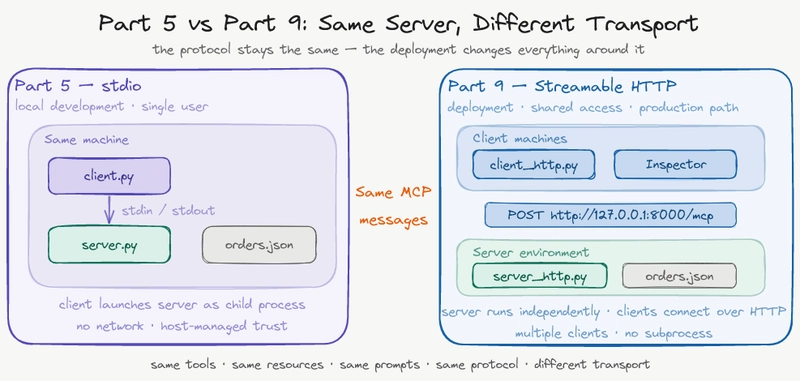
Geçen ay bir toplantıda küçük bir ekip bana şunu sordu: “Biz MCP server’ı ayağa kaldırdık, tool’lar çalışıyor… peki bunu servise çevirince neden her şey biraz karışıyor?” Çok yerinde soru. İşin aslı şu — protokol aynı kalsa da etrafındaki dünya değişiyor. Bir anda süreç yönetimi, ağ katmanı, auth, loglama ve hata senaryoları masaya oturuyor. Yani mesele sadece kodu başka yere taşımak değil; nasıl düşündüğünü de güncellemek.
Bu yazıda o geçişi anlatacağım. İngilizce kaynaktaki örnekten ilham alıyorum. Olayı kendi gözümden yeniden kuruyorum: lokal çalışan bir MCP sunucusunun, Streamable HTTP ile servis gibi davranan bir yapıya dönüşmesi. Aynı araçlar, aynı iş mantığı… ama bambaşka çalışma modeli. Ve evet, bu fark kağıt üstünde küçük görünüyor — pratikte işe bayağı hissediliyorsunuz.
Hmm, bunu nasıl anlatsamdı…
Neden Bu Geçiş Önemli?
MCP serisinin önceki bölümlerini okuyanlar bilir. Lokal makinede stdio üzerinden çalışan model oldukça rahat, hızlı, hatta biraz konforlu bile. Host server’ı child process olarak açıyor, veri stdin/stdout üzerinden akıyor ve güven sınırı kabaca “aynı makine” oluyor. Geliştirme sırasında bu yaklaşım tatlıdır.
Gel gelelim üretime çıkınca işler değişiyor (ciddiyim). Server artık tek bir terminalin içine sıkışmıyor; bağımsız çalışıyor, port dinliyor. Istemciler ona ağ üzerinden bağlanıyor. İşte tam burada transport katmanı devreye giriyor ve önünüze yeni sorular diziliyor: “Bu servisi kim çağıracak?”, “Hangi ortamda koşacak?”, “Bir bağlantı koparsa ne olacak?” Bunlar küçük sorular değil — bunlar mimarının ta kendisi.
Ve işler burada ilginçleşiyor.
Ben buna ilk kez 2024 sonbaharında İstanbul’daki bir müşteri projesinde çarpmıştım. Lokal demo müthişti. Ekip server’ı container’a alınca bazı varsayımlar dağıldı; özellikle yaşam döngüsü yönetimi beklediğimiz kadar pürüzsüz değildi. Küçük detaylar — mesela process’in kim tarafından başlatıldığı — aniden kilit hâle geldi. Küçük detaylar. Ama koça fark.
Aynı Uygulama, Farklı Hayat
Part 5’teki TechNova order assistant örneğini düşünün. Üç tool var: sipariş durumunu sorgulama, sipariş kalemlerini çekme ve sipariş iptali yapma. İki resource, iki prompt. Veri seti bile aynı kalıyor.
Kısa bir not düşeyim buraya.
Şöyle anlatayım: uygulamanın beyni aynı duruyor ama dolaşım sistemi değişiyor. Lokal modda host server’ı yan komşu gibi çağırıyordu; HTTP modunda işe servis bağımsız bir apartman dairesine taşınmış oluyor — biraz kaba benzetme ama iş görüyor. Tool isimleri aynı kaldığı için geliştirici tarafında büyük refactor yok gibi görünüyor. Operasyon tarafında resmen yeni bir kurallar seti geliyor. Tamamen yeni.
Bunu geçen yıl Ankara’da yaptığım kısa bir PoC’de birebir gördüm. Aynı JSON-RPC akışıyla çalışan iki kurulum vardı; biri stdio ile uçuşuyor gibiydi, diğeri HTTP üzerinde daha esnek davrandığı için Kubernetes’e taşımak kolaylaştı… ama debug ederken logların iyi düzenlenmemesi yüzünden yarım gün harcadık! Yani avantaj var, bedava değil.
| Konu | Stdio | Streamable HTTP |
|---|---|---|
| Süreç yönetimi | Host başlatır ve kapatır | Server ayrı yaşar |
| İletişim kanalı | stdin / stdout | Ağ üzerinden HTTP |
| Kullanım alanı | Lokal geliştirme | Paylaşımlı servis / üretim yaklaşımı |
| Zorluk seviyesi | Daha sade başlangıç | Daha fazla operasyonel detay |
| Güven varsayımı | Aynı makineye dayanir | Ayrıca auth ve erişim politikası ister |
Neleri Değiştiriyorsunuz?
Protokol sabit kalıyor mu?
Evet. Büyük ölçüde evet. initialize → list → call akışı yine orada duruyor. JSON-RPC mesajları da kafasına göre şekil değiştirmiyor zaten — bu güzel haber,. Mevcut tool ekosistemi boşa gitmiyor. Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik.
Buna rağmen çevresel davranış farklılaşıyor. Mesela client artık server’ı başlatmıyor; sadece bağlanmaya çalışıyor. Ufak görünen bir ayrım bu — ama hata analizi yaparken altın değerinde (buna dikkat edin). Çünkü sorun çıktığında “process niye açılmadı” yerine “servis niye cevap vermedi” diye bakıyorsunuz. İnanın, bu ikisi arasında gece gündüz fark var. Gerçekten.
Lifecycle kontrolü kimin elinde?
Pek çok ekip burada ilk kez tökezliyor. Local modelde her şeyi host biliyordu; servis neredeyse onun gölgesiydi. HTTP modelinde işe server bağımsız davranmalı, kendi health check’ını vermeli, gerektiğinde restart edilebilmeli (ki bu çoğu kişinin gözünden kaçıyor) (eh, fena değil). Kurumsal tarafta bu şart; startup tarafında işe bazen lüks gibi görünür ama aslında erken edinilmesi gereken bir alışkanlık. Daha fazla bilgi için Yapay Influencer Çağı: AI İçerik Neden Yoruyor? yazımıza bakabilirsiniz. Bu konuyla ilgili Veri Mühendisliği Yaşam Döngüsü: Ham Veriden Ürüne yazımıza da göz atmanızı tavsiye ederim. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
{
"transport": "streamable-http",
"endpoint": "http://localhost:3000/mcp",
"auth": {
"mode": "bearer-token"
},
"capabilities": ["tools", "resources", "prompts"]
}Eh, Neyse uzatmayalım… basit config bile size yeni sorumluluklar getiriyor: endpoint yönetimi, TLS, token süresi, reverse proxy ayarı, hatta rate limit bile. Bir de şu var: localhost’ta çalışan şeyin prod’da aynı sakinlikle davranacağını sanmak çoğu zaman hayal kırıklığı yaratır. Ben bunu hem SaaS projelerinde hem de iç ağ uygulamalarında defalarca gördüm. Kağıt üstünde süper, pratikte göreceğiz demek gerekiyor bazen.
Küçük Ekip İçin Başka, Kurumsal İçin Başka — Doğru Okuma Şekli Ne?
Küçük bir startup için Streamable HTTP’nın en büyük artısı hız olabilir. Tek makinede başlayan sisteminizi sonra yavaş yavaş dışarı açarsınız; önce localhost testleri, sonra staging, en sonunda gerçek trafik. Bu sırada MCP sözleşmesini bozmazsınız. Ürün mantığı korunur, dağıtım modeli evrilir. Kulağa sıradan geliyor belki — ama operasyon açısından ciddi rahatlık.
Ha, bu arada küçük ekiplerin yaptığı klasik hata şudur: önce servisi büyütüp sonra güvenliği düşünmek. Bence tam tersi olmalı. Hele bir de müşteri verisine dokunuyorsanız yetkilendirme konusunu sona bırakmak baya riskli — bunu söylemeden geçemezdim.
Küçük bir detay: Kurumsal tarafta tablo farklı. Orada asıl mesele ölçekten çok yönetişimdir. Kim hangi tool’u kullanabilir? Hangi prompt hangi departmana açık? Audit log nereye düşüyor? Bunlar çözümlenmeden “HTTP’ye geçtik” demek biraz eksik kalır (en azından benim deneyimim böyle). Ben geçtiğimiz mart ayında Frankfurt merkezli bir finans ekibiyle yaptığım görüşmede bunu net hissettim; onlarda teknik soru kadar uyum sorusu da vardı, hatta bazen teknik kısım ikinci plana düşüyordu — şaşırtıcı değil aslında.
Bir de performans meselesi var. Stdio düşük gecikmeli hissettirebilir çünkü yol kısa. HTTP tarafında ekstra katmanlar girdiği için teoride yük artar, ama iyi tasarlanmış cache, keep-alive ve düzgün connection pooling ile bu fark gayet tolere edilebilir. Yani panik yok. Sadece ölçmek lazım. Daha fazla bilgi için tmux ile Claude Code Oturumlarını Kaybetme yazımıza bakabilirsiniz.
“Protokolün kendisi sızı kurtarmaz; önü nasıl taşıdığınız belirler.” Bence MCP’nın en kritik dersi tam olarak bu.
Bana Göre En Pratik Dersler — İşi Kafada Netleştiren Noktalar
Tabi teori güzel ama insan sahada öğreniyor. Mesela ben bir projede sırf transport değişti diye error handling’i yeniden yazmak zorunda kaldığımı hatırlıyorum; ilk bakışta sınır bozucu gelmişti, sonra anladık ki problem kodda değil, varsayımlardaymış. Daha sağlam yapı, daha fazla disiplin istiyor. Bu kadar.
Araya gireyim: Şimdi gelelim hızlı notlara:
- MCP mesajlarını körü; business logic’i tekrar yazma.
- Sadece transport’u değiştirirken auth’u hafife alma.
- Error response formatını standardize et; yoksa debug cehennemi başlıyor.
- Lokal demo ile production deployment’ını birbirine karıştırma.
- Trafik artarsa observability’i erkenden köy; sonradan eklemek can yakar.
- Bazıları için streamable HTTP ara aşamadır, bazıları için final hedef değildir; kullanım senaryosuna göre karar verilir. (bence en önemlisi)
Bence güzel olan nokta şu: bu geçiş geliştiriciyi gereksiz yere sıfırlamıyor. Tam tersine, eldeki sistemi bozmadan büyütmeye izin veriyor. Ama kötü yani da var — “nasıl olsa aynı araçlar” deyip operasyon kısmını küçümseyebilirsiniz. İşte orası tuzak.
Bakın, küçük bir detay: Bir dakika (ki bu çoğu kişinin gözünden kaçıyor). şunu da ekleyeyim: bu tıp mimarı yazılar genelde çok steril ölür. Oysa gerçek hayatta ilk sorun genellikle port çakışması, ikinci sorun sertifika, üçüncü sorun işe logların yanlış yerde toplanmasıdır. Bunları atlayınca hikâye yarım kalıyor.
MCP’nın Gücü Nerede Daha Net Görünüyor?
Lokal deneyden hizmet modeline geçişte ne kazanılıyor?
Bence asıl kazanım tekrar kullanılabilirlikte yatıyor. Aynı order assistant’ı bugün lokal testte, yarın staging’de, öbür gün içeride başka takımların kullandığı ortak hizmette çalıştırabiliyorsunuz. Şimdi, kulağa sıradan geliyor olabilir; ama ürün ekipleri açısından ciddi rahatlık sağlıyor (ben de ilk duyduğumda şaşırmıştım). Gerçekten ciddi.
Ha, unuttum neredeyse: bu tarz geçişlerde UX denetimi yapan ajanlarla entegrasyon kurmak da kolaylaşıyor.
AI Ajanınıza UX Denetimi Süper Gücü CLI + MCP ile Hızlı Başlangıç! yazısındaki yaklaşımı düşündüğünüzde, MCP’nın yalnızca otomasyon değil, denetlenebilirlik tarafına da oynadığını görüyorsunuz.
Bir de observability konusu var. Mesela LangChain Ajanlarını Üretimde İzlemek Gerçek Zamanlı Rehber! türü işler yapan ekipler için taşıma modeli kadar izleme stratejisi de önemli. HTTP tabanlı sunum, trace id taşımayı, request seviyesinde analiz yapmayı, hatta hata sınıflandırmayı kolaylaştırabiliyor (ciddiyim)
Şöyle ki, Ama dürüst olayım: her proje buna uygun değil. Tek kullanıcıya hitap eden dar kapsamlı araçlarda stdio hâlâ fazlasıyla mantıklı olabilir. Basitlik kötü değildir. Bazen en iyi mimarı, en az hareket edenidir.
Sık Yapılan Hatalar — Ve Neden Can Sıkıcı Oldukları
Birinçisi: transport değişince security modelinin otomatik geldiğini sanmak. Hayır, gelmiyor. Auth mekanizmasını siz kuruyorsunuz. Nokta.
Eh, İkincisi: server’ı stateless zannetmek. Bazı implementasyonlarda session ya da context bilgileri önem kazanabiliyor, hele uzun yaşayan bağlantılarda.
Üçüncüsü: loglama standartlarını ertelemek. Sonra biri gelip “neden tool çağrısı başarısız oldu?” dediğinde elinizde düzgün kayıt olmuyor. O an çok sınır bozucu.
Dördüncüsü: lokalde çalışan endpoint’i prod’a olduğu gibi taşımak. IP, domain, TLS, timeout… bunların hepsi ayrı dünya.
Beşincisi… test etmeyi sadece happy path sanmak! Sipariş bulunamadığında ne oluyor? İptal edilmiş siparişte cancel_order nasıl dönüyor? Yetkisiz istek geldiğinde hangi hata veriliyor? Buralar genelde sonradan patlıyor.
Vallahi, Benzer hataları geçen sene Berlin’deki küçük bir fintech demosunda gördüm; ekip tool seviyesinde mükemmel ilerlemişti. Resource erişimleri sınanmamıştı. Demo günü küçük çaplı panik çıktı (kendi tecrübem). neyse ki production değildi.
- MCP sözleşmesini körü; (bu kritik)
- transport’u değiştirirken auth’u, loglama’yı ve hata yönetimini birlikte planla;
- lokal ile production arasındaki farkı küçümseme;
- observability’i sonraya bırakma — sonra dediğin gelmez.
Sıkça Sorulan Sorular
MCP’de stdio’dan HTTP’ye geçince protokol değişiyor mu?
Çoğu senaryoda MCP mesaj formatı/protokol mantığı aynı kalır; değişen asıl şey “taşıma” katmanıdır. Stdio’da süreç yönetimi ve bağlantı kontrolü daha çok host tarafında olurken, HTTP’de server bağımsız bir servis gibi davranır. Bu yüzden mimarı kararlar ve operasyon tarafı yeniden şekillenir.
HTTP’ye geçince neden hata senaryoları daha sık karışık geliyor?
Stdio akışında hata çoğu zaman aynı proses sınırında hızlıca “görünür” ölür. HTTP’de işe ağ gecikmesi, zaman aşımı, bağlantı kopması ve yeniden deneme gibi durumlar devreye girer. Benim pratikte en çok zorlayan kısım loglama ve korelasyon (istek–cevap takibi) oldu; doğru trace olmadan “neden oldu?” sorusu uzuyor.
Auth (kimlik doğrulama) ve güvenlik ayarlarını HTTP’de nasıl ele almak gerekir?
HTTP ile birlikte kim çağırıyor sorusu netleştiği için auth gündeme gelir: token doğrulama, mTLS, IP kısıtları ya da gateway üzerinden kontrol gibi seçenekler düşünülür. Stdio’da “aynı makine/aynı ortam” varsayımı daha rahat olduğu için güven sınırı daha farklı kurgulanabiliyor. Üretimde genelde API gateway veya servis ağı (service mesh) üzerinden standartlaştırmak işinizi kolaylaştırır.
Container’a alınca “her şey çalışıyor” ama niye yaşam döngüsü beklediğim gibi olmuyor?
Çünkü stdio yaklaşımı child process başlatma/yaşam döngüsü varsayımlarına dayanir. Container’da işe process’in başlatılması, health check’ler, port binding ve graceful shutdown gibi konular kritik hâle gelir. Geçen projede “tool’lar çalışıyor” ama kapanışta takılıyor ve yeniden ayağa kalkışta gecikiyor gibi durumlar görmüştüm; çözüm çoğunlukla doğru lifecycle hook ve zaman aşımı ayarlarını yapmak oldu.
HTTP’ye geçiş performansı etkiler mi?
Etkileyebilir; özellikle eklenen ağ katmanı ve JSON/HTTP overhead’i latency’yi artırabilir. Ama çoğu uygulamada asıl farkı yaratan şey, concurrency ve zaman aşımı stratejin nasıl kurduğun oluyor. Benim gözlemim, doğru timeout/retry ve iyi bir observability (log/trace metriği) kurulduğunda performans sorunlarının “gizli” kalmadığı yönünde.
Kaynaklar ve İleri Okuma
Azure Architecture Center: API tasarımında en iyi pratikler
Azure Architecture Center: Güvenli entegrasyon (auth/kimlik doğrulama odaklı)
Azure Monitör: İstekler (request telemetry ve teşhis)
GitHub: Model Context Protocol (MCP) resmî repo

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar

Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



