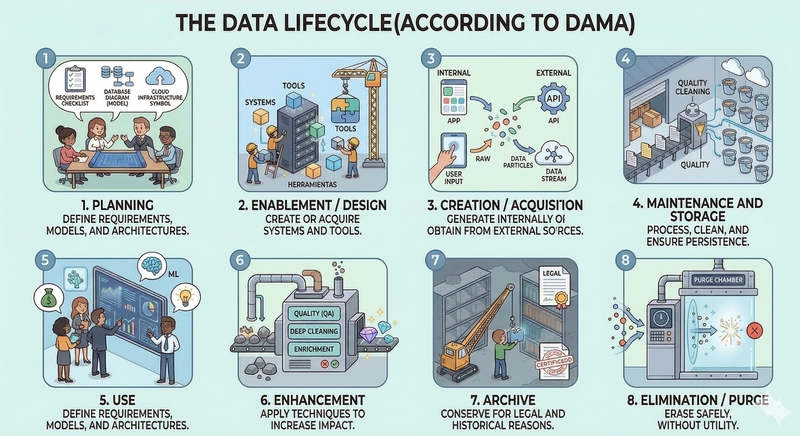
Veri mühendisliğini ilk kez ciddi anlamda çalışmaya başladığımda, açık konuşayım, kafam biraz karışmıştı. Herkes “pipeline”, “streaming”, “warehouse” diyordu; ama işin aslı şu ki, ortada tek bir sihirli kutu yok. Veri dediğiniz şey doğuyor, yolda şekil değiştiriyor, bazen kirleniyor, bazen kayboluyor. En sonunda birine somut bir fayda sağlıyorsa — ancak o zaman — gerçek anlamda değer kazanıyor (buna dikkat edin). İşte veri mühendisliği yaşam döngüsü tam da bu hikâyeyi anlatıyor.
Bu konuyu yıllar önce İstanbul’da bir e-ticaret projesinde çalışırken daha net kavramıştım. Sipariş verisi gece yarısı akıyordu, stok tarafı ayrı telden çalıyordu, pazarlama ekibi işe “şu rapor niye 20 dakika geç geliyor?” diye soruyordu. O gün şunu çok net gördüm: Veri mühendisliği sadece veri taşımak değil, verinin güvenilir biçimde işe dönüşmesini sağlamak.
İşte tam da bu noktada devreye giriyor.
Bir de sık yapılan bir hata var. Veri yaşam döngüsü ile veri mühendisliği yaşam döngüsü aynı şey sanılıyor (ben de ilk duyduğumda şaşırmıştım). Değil. Biri daha çok yönetim ve yönetişim tarafına bakıyor, diğeri işe boru hattının teknik gerçeklerine. Yani biri “bu veri ne kadar yaşayacak?” diye sorarken, öbürü “bu veri nasıl akacak?” diye düşünüyor. Küçük fark gibi görünüyor ama pratikte iki ayrı dünya.
Önce Şunu Ayıralım: Veri Yaşam Döngüsü Nedir?
DAMA-DMBOK çizgisinden baktığınızda veri yaşam döngüsü oldukça tanıdık bir mantığa oturuyor: veri planlanır, oluşturulur ya da toplanır, saklanır, kullanılır, zenginleştirilir, arşivlenir ve gerektiğinde silinir. Mantıklı değil mi? Kağıt üstünde düzenli duruyor; pratikte işe çoğu ekip bu adımların arasını lastik gibi esnetiyor.
İşte tam da bu noktada devreye giriyor.
Mesela 2023’te Ankara’daki bir kurumsal projede buna benzer bir yapı görmüştüm. Hukuk ekibi veriyi 7 yıl saklamak istiyordu, ürün ekibi işe maliyet yüzünden eski kayıtları buzlukta tutmak istemiyordu. Tam o noktada “yaşam döngüsü” dediğimiz şeyin sadece teknik değil, hukukî. Operasyonel bir mesele olduğunu bir kez daha anladım (yanlış duymadınız)
Planlama aşaması kulağa sıkıcı geliyor olabilir. Ama aslında en pahalı yanlışlar burada yapılıyor (buna dikkat edin). Baştan hangi verinin ne kadar süre tutulacağını bilmiyorsanız — sonradan bulut faturası size küçük çaplı bir şok yaşatabiliyor. Hatta bazen şok da değil, resmen hayal kırıklığı oluyor.
Veri Mühendisliği Yaşam Döngüsünün Beş Ana Durağı
Neyse, uzatmayalım. Veri mühendisliği tarafında genelde beş ana aşama konuşulur: üretim (generation), alma/aktarım (ingestion), depolama (storage), dönüştürme (transformation) ve sunma (serving). Bunların her biri ayrı derttir; ama birlikte çalışınca sistemin omurgasını kuruyorlar.
Eh, Bu beşliyi ben hep mutfak benzetmesiyle anlatıyorum. Malzeme geliyor, ayıklanıyor, dolaba giriyor, pişiriliyor ve tabağa çıkıyor. Kötü malzeme gelirse sonuç kötü ölür; kötü saklarsanız yine bozulur; kötü pişirirseniz de kimse yemek istemez. Veri de pek farklı değil, inan.
Aşağıdaki tabloyu ilk kez kendi notlarımı toparlarken yapmıştım; hâlâ toplantılarda iş görüyor:
| Aşama | Ana Soru | Sık Risk | Pratik Not |
|---|---|---|---|
| Generation | Veri nereden çıkıyor? | Sahiplik belirsizliği | Kaynaktan haberiniz olsun |
| Ingestion | Veri nasıl içeri alınıyor? | Bottleneck ve gecikme | Batch mi streaming mi karar verin |
| Storage | Nereye koyacağız? | Maliyet patlaması | Sıcak-soğuk katmanları düşünün |
| Transformation | Ham veri nasıl temizlenecek? | Kural karmaşası | Dönüşümü test edin |
| Serving | Kime nasıl sunulacak? | Zayıf performans | Kullanıcı ihtiyacına göre optimize edin |
1) Generation: Verinin Doğduğu Yer
İnanın, Her şey burada başlıyor. Sensörler, uygulamalar, ödeme sistemleri, loglar… Veri kaynaklarının hepsi farklı hızda konuşur ve bazıları bayağı huysuzdur. En büyük hata da kaynağın sahibi sizmişsiniz gibi davranmaktır. Değilsiniz.
Editör masasında geçen ay karşıma çıkan bir örnek hâlâ aklımda. Bir SaaS şirketi müşteri olaylarını topluyordu ama ürün ekibi schema değişikliğini haber vermemişti. Sonuç? Gece çalışan pipeline sabaha kadar sessizce kırıldı — kimse fark etmedi çünkü alarm da yoktu. Klasik.
Kaynaktan gelen frekansı bilmek burada kritik oluyor. Günlük mü geliyor? — en azından ben öyle düşünüyorum — Saatlik mi? Anlık mı? Bir kaynak haftada iki kez güncelleniyorsa önü streaming’e zorlamak gereksiz masraf çıkarır. Saniyelik telemetriyi batch ile taşımaya kalkarsanız da kullanıcı sızı beklemez, o da ayrı dert.
2) Ingestion: Dar Boğazın Başladığı Nokta
Garip gelecek ama, Bence en çok kavga ingestion tarafında çıkıyor. Çünkü herkes kendi ihtiyacını merkeze koyuyor: analitik ekip hız ister, operasyon ekibi doğruluk ister, ürün ekibi ucuzluk ister. Hepsini aynı anda vermek kolay değil — gerçekten değil.
Bakın, Python Performans Darboğazı: Tahmin Etme, Ölç! yazısındaki yaklaşımı hatırlatan bir nokta var burada: önce ölçmeden iyileştirmeye kalkarsanız gözünüz kapalı koşmuş olursunuz. Ingestion için de aynı şey geçerli. Gecikme nerede oluşuyor? API’de mi? Kuyrukta mı? Yazma katmanında mı? Bunları görmeden çözüm üretmek biraz falcılığa kaçıyor.
İyi bir ingestion tasarımı sadece veriyi almakla kalmaz; bozuk veriyi geri iter, gecikmeyi görünür kılar ve sistemi sakın tutar.
İşin garibi, Küçük bir startup için çoğu zaman batch yaklaşımı yeterli ölür; günlük çekimler hem ucuzdur hem de yönetmesi kolaydır. Enterprise seviyede işe streaming kaçınılmaz hâle gelebiliyor — çünkü müşteri davranışıyla dolandırıcılık tespiti ya da canlı fiyatlama arasında dakikalar bile ciddi fark yaratıyor. Daha fazla bilgi için Sesle Kod Yazan Yerel Yapay Zekâ: Agent’ı Kurarken Neler Öğrendim? yazımıza bakabilirsiniz.
3) Storage: Ucuz Görünüp Pahalılaşan Katman
Burası benim en sevdiğim tuzaklardan biri! Depolama ilk bakışta basit görünür ama ölçek büyüyünce faturanın dili değişir. Hot storage hızlıdır ama pahalı olabilir; cold storage daha ucuzdur ama erişim ağırdır; archive işe neredeyse kasaya kaldırılmış bir dosya gibidir — var ama ona ulaşmak ayrı iş.
Durun, bir saniye.
Bunu geçen yıl Berlin’de çalışan eski bir ekip arkadaşımla konuşmuştum. Logları yıllarca hot bucket’ta tutmuşlar. Sonra aylık fatura patlayınca herkes şaşkın kaldı. Aslında — hayır dür, daha doğrusu şaşıracak durum yoktu; yanlış yerde sıcak tutulan her veri zamanla bütçeyi yakar. Kaçınılmaz. MCP mi, CLI mı? Tarayıcı Otomasyonunda Kazanan Netleşti yazımızda bu konuya da değinmiştik.
FERPA Uyumlu RAG: Kurumsal Sistemler Nerede Çuvallıyor? yazısında gördüğümüz gibi saklama politikaları yalnızca maliyet meselesi değil; uyumluluk da işin içine giriyor. Şimdi gelelim pratik tarafa: Daha fazla bilgi için MacBook Alırken Neye Bakmalı? Nişan 2026 Fırsatları yazımıza bakabilirsiniz.
- Sık sorgulanan veriyi sıcak katmanda tutun.
- Nadiren açılan tarihsel kayıtları soğuk ya da arşiv katmanına atın.
- Saklama süresi biten veriyi otomatik silmeye hazırlayın.
4) Transformation: Kirliyi Temize Çevirmek Ama Özenle
İnanın, Dönüştürme aşaması çoğu kişinin sandığı gibi sadece SQL yazmak değil aslında. Burada iş kuralı devreye girer. Hangi alan boş kalabilir, hangisi asla boş kalamaz, hangi tarih formatı kabul edilir (inanın bana). Bunların hepsi dönüşümün parçası. Ve evet — küçük görünen bir tarih formatı yüzünden bütün raporun sapıtması gayet mümkün, bunu yaşadım (ki bu çoğu kişinin gözünden kaçıyor)
LangChain Ajanlarını Üretimde İzlemek: Gerçek Zamanlı Rehber (evet, doğru duydunuz)
SELECT
customer_id,
COUNT(*) AS order_count,
SUM(CASE WHEN status = 'paid' THEN amount ELSE 0 END) AS paid_revenue
FROM orders
WHERE created_at >= CURRENT_DATE — INTERVAL '30 days'
GROUP BY customer_id;Dönüşümde en sevmediğim şey hep sessiz hatalar oldu. Kod çalışır, çıktı gelir, dashboard dolar… ama sayıların anlamı kaymıştır. Bu yüzden test etmek şart. Hatta bazen unit test bile yetmez; örnek veri setleriyle uçtan uca kontrol yapmak gerekiyor. Ben bunu 2024’te İzmir’deki küçük bir fintech denemesinde acı şekilde öğrendim: para hareketlerinin biri çift sayıldı, diğerinin kuru çevrilmedi. Ekranda her şey güzeldi; gerçekte işe işler karışıktı.
Nerede İşe Yarıyor? Serving Katmanı Neden Hafife Alınmamalı?
Araya gireyim: Pek çok ekip bütün enerjisini upstream’e gömerken serving kısmını sonradan düşünüyor. Halbuki kullanıcı değeri tam orada görünüyor. Dashboard mu vereceksiniz? API mi sunacaksınız? ML modeline feature mı sağlayacaksınız? Cevap değiştikçe mimarı de değişiyor — bu kadar basit.
Servisleme Tarafında Düşünmeniz Gerekenler
- Düşük gecikme gerekiyorsa indeksleme şarttır.
- Anlık analiz gerekiyorsa ön hesaplama iyi fikir olabilir.
- Eğer iç kullanıcı varsa sade rapor yeter; dış müşteri varsa SLA baskısı başlar.
- Bazen tek doğru cevap yoktur; birkaç servis katmanı yan yana yaşar.
Küçük takımlarda tek warehouse üzerinden servis vermek idare eder. Kurumsalda işe ayrı okuma katmanı, cache stratejisi ve rol bazlı erişim kaçınılmaz hâle geliyor. Güvenlik ile performans birbirine giriyor burada — tatlı sert bir çekişme yani.
Tüm Aşamaların Üstünde Duran Görünmez Katmanlar
Şimdi gelelim asıl can alıcı yere. Security, data management, DataOps, data architecture, orchestration ve software engineering… Bunlara ben hep “görünmeyen altyapı” diyorum — çünkü ekran görüntüsünde yer almazlar. Sistem çökerse ilk onlar eksik hissedilir.
Bak şimdi, CrowdSec ile Linux Sunucunu Korumaya Al: Uygulamalı Rehber yazısındaki mantık burada da geçerli: güvenlik sonradan eklenen aksesuar değildir; borunun içinden geçen suyun kendisi kadar önemli. Veriye erişimi sınırlamazsanız iyi niyetle kurduğunuz pipeline bile risk üretir.
Küçük Startup ile Kurumsal Yapıda Aynı Değil
Küçük startup’ta amaç genelde hızlı ilerlemektir. Az kişi, az bütçe, çok iş. Bu ortamda fazla soyut mimarı kurarsanız ekip nefes alamaz. Basit batch işler, temiz naming convention, iyi dokümantasyon — çoğu zaman yeterli. Fazlası bazen yük ölür.
Enterprise tarafta tablo değişiyor (bizzat test ettim). Çok kaynak, çok ülke, çok mevzuat… Bir de üstüne farklı departmanların aynı datayı farklı isimlerle çağırması var ki, o bambaşka bir dert. Burada lineage, audit trail, access control ve kalite metrikleri oyuna giriyor. Aksi hâlde üç ay sonra kimsenin sahiplenmediği kırık tablolar ordusu oluşuyor; ben buna “sessiz kaos” diyorum.
Şunu fark ettim: Geçen sene Londra’daki bir danışmanlık görüşmesinde bunu birebir gördüm: Startup kökenli ekip production’a büyüyünce tüm tempoyu eski alışkanlıklarla sürdürmeye çalışmıştı. Olmadı tabi. İnsan sayısı artınca manuel kontrol yetmiyor; otomasyon istiyor. Ama otomasyon da kör olmayacak — ölçülü olacak (yanlış duymadınız)
Sık Yapılan Hatalar ve Küçük Kurtarma Taktikleri
- Tedarikçi veya kaynak sahibiyle hiç konuşmadan pipeline kurmak. — bunu es geçmeyin
- Saklama maliyetini küçümsemek. (bu kritik)
- Dönüşümü test etmeden prod’a almak.
- Sonra düzeltiriz” diyerek observability’yi ertelemek.
Bu dört maddeyi görünce gülüyor olabilirsiniz. Ben de güldüm açıkçası — ta ki geçmişte kurulmuş birkaç sistemi devralana kadar. Bazıları gerçekten belge bırakmamıştı; bazılarında işe belge vardı ama kimse okumamıştı. Aradaki fark sandığınızdan küçük değil (şaşırtıcı ama gerçek)
Sıkça Sorulan Sorular
Veri mühendisliği yaşam döngüsü nedir?
Verinin üretildiği andan son kullanıcıya ulaşmasına kadar geçtiği teknik süreci anlatır.
Genelde generation, ingestion, storage, transformation ve serving adımlarından oluşur.
Data lifecycle ile data engineering lifecycle arasındaki fark ne?
Data lifecycle daha çok yönetişim, saklama ve kullanım ömrüne odaklanır.
Data engineering lifecycle işe bu verinin teknik olarak nasıl işlendiğine bakar.
Batch mi streaming mi seçmeliyim?
Kullanım senaryosuna göre değişir.
Günlük raporlama için batch çoğu zaman yeterli;
gerçek zamanlı karar gerekiyorsa streaming daha uygundur.
Depolamada en önemli konu ne?
Maliyetle erişim hızını dengede tutmak gerekir.
Yanlış katmanda uzun süre tuttuğunuz her veri ileride fatura olarak geri gelir.
Data Engineering Zoomcamp GitHub Sayfası
DAMA International Body of Knowledge
Kaynaklar ve İleri Okuma
Azure Well-Architected: Veri Analitiği
Azure Databricks için Mimarı Dokümantasyon
Azure Stream Analytics Dokümantasyonu
Azure Data Factory (Microsoft GitHub)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.