Veritabanı neredeyse tamamen çökse keşke. Ciddiyim. En azından alarm çalar, herkes koşar, sorun net ölür (en azından benim deneyimim böyle). Ama veritabanı çökmez de yavaşlarsa… İşte o zaman gerçek kâbus başlıyor. Kullanıcılar “bir şey var ama ne olduğunu anlatamıyorum” demeye başlar. Siz de dashboard’lara bakarsınız, her şey yeşil görünür ama bir şeyler çürüyor içeride.
Geçen ay tam olarak böyle bir durumla karşılaştım (yanlış duymadınız). Bir arkadaşımın projesi — e-ticaret sitesinde Manticore Search kullanıyor — arama sonuçları fark edilir şekilde yavaşlamıştı. Ama ne CPU alarmı geldi, ne de error log’da ciddi bir şey vardı. İki saat boyunca metriklerin arasında kayboldum. Sonunda sorunu bulduk ama o iki saat… Neyse, o hikâyeye geleceğim.
Her Şey Yeşil Ama Bir Şeyler Yanlış
Bir şey dikkatimi çekti: Şimdi bakın, bu senaryoyu hemen herkes yaşamıştır. Arama yavaşlıyor. Crash yok. Hata dönmüyor. Servis ayakta. Dışarıdan bakınca dramatik bir şey göremiyorsunuz — ama kullanıcı hissediyor, çünkü insanlar 200ms’lık farkı bile ayırt eder, bunu artık biliyoruz.
E ne yaparsınız? Monitoring’e bakarsınız: (buna dikkat edin)
- CPU: Normal görünüyor.
- Ortalama latency: Eh, biraz yüksek ama alarm verecek seviyede değil.
- Disk I/O: Sıra dışı bir şey yok.
- Worker’lar: Meşguller ama… hep meşguldüler zaten?
Her metrik tek başına “idare eder” seviyesinde. Ama hepsine birden bakınca sistem açıkça degrade oluyor. İşte sınır bozucu olan tam da bu. Parçalar ayrı ayrı iyi, bütün kötü (ciddiyim)
Ben o gün arkadaşımın projesinde tam olarak bunu yaşadım. İstanbul’da bir kafede laptop başında, Slack’ten (söylemesi ayıp) gelen “arama yine yavaş” mesajlarına bakıyordum — queue’ya baktım, worker kullanımına baktım, log’lara baktım, bir türlü net bir şey çıkmıyordu ortaya. Sonunda, tam iki saat sonra, şu tablo ortaya çıktı: request queue yavaş yavaş büyümüş, worker’lar %100’e yakın çalışıyor, bir ağır sorgu arada execution’ı bloke ediyor, p99 latency ortalamadan çok daha kötü ve bir node yakın zamanda restart olmuş.
Bir dakika — bununla bitmedi.
Sinyaller hep oradaydı. Problem, farklı yerlere dağılmış olmalarıydı.
Manticore Search için Hazır Grafana Dashboard’u
Açık konuşayım, Tamam, sorunu anladık. Peki çözüm?
Bütün bu metrikleri tek bir yerde, anlamlı bir şekilde görmek. Manticore Search ekibi tam da bunu yapmış — tek bir Docker komutuyla çalışan, Grafana + Prometheus + önceden yapılandırılmış data source. Alert’lerle gelen hazır bir dashboard. Dür, bir saniye. Bunu ilk gördüğümde “ya ne kadar hazır olabilir ki” diye düşündüm açıkçası. Sonra denedim. Gerçekten tek komut.
docker run -p 3000:3000 manticoresearch/dashboardBitti. Buyurun. Tarayıcıdan localhost:3000‘e giriyorsunuz ve Grafana dashboard’u karşınıza çıkıyor. Prometheus zaten arka planda çalışıyor, veri topluyor. Siz sadece hangi Manticore instance’larını izlemek istediğinizi söylüyorsunuz.
Ortam Değişkenleri ile Yapılandırma
Container iki temel environment variable destekliyor:
| Değişken | Açıklama | Varsayılan |
|---|---|---|
MANTICORE_TARGETS |
Virgülle ayrılmış Manticore instance listesi | localhost:9308 |
GF_AUTH_ENABLED |
Grafana login ekranını etkinleştirir | false (anonim admin erişimi) |
Tek bir node izleyecekseniz:
docker run -p 3000:3000 \
-e MANTICORE_TARGETS=your-host:9308 \
manticoresearch/dashboardBirden fazla node? Virgülle ayırıyorsunuz, o kadar:
docker run -p 3000:3000 \
-e MANTICORE_TARGETS=node1:9308,node2:9308,node3:9308 \
manticoresearch/dashboardHmm… Evet, bu kadar basit. Gerçekten bu kadar.
Uzak Sunucuda Manticore Çalışıyorsa Ne Olacak?
Ha, bunu söylemeyi neredeyse unuttum. Dashboard container’ı varsayılan olarak Manticore’un aynı makinede olduğunu varsayıyor — ama pratikte çoğu zaman öyle olmaz, değil mi? Manticore bir yerde, Grafana başka bir yerde. Daha fazla bilgi için Claude, mitmproxy ve Spor Uygulamasının Gizli API’si yazımıza bakabilirsiniz.
Bu durumda yapmanız gereken tek şey MANTICORE_TARGETS değişkenine uzak sunucunun IP’sını veya hostname’ını vermek. Ama dikkat — Manticore’un MySQL protokol portu (varsayılan 9306). HTTP portu (varsayılan 9308) dışarıya açık olmalı, yoksa Prometheus veri çekemez ve dashboard bomboş kalır. Firewall kurallarınızı kontrol edin derim (ben de ilk duyduğumda şaşırmıştım)
Bir de şunu söyleyeyim: eğer Manticore’ünüz Docker içinde çalışıyorsa. Dashboard da Docker içindeyse, host.docker.internal veya Docker network isimlerini kullanmanız gerekebilir. Ben ilk denemede buna takıldım — “neden veri gelmiyor” diye tam 10 dakika uğraştım, sonra network ayarını fark ettim. Klasik. Yapay Zekâ Yığını: Kendi Akıllı Uygulamanı Kur yazımızda bu konuya da değinmiştik.
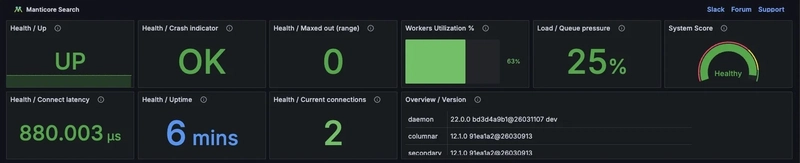
Dashboard’da Ne Görüyorsunuz?
Eh, Şimdi gelelim asıl önemli kısma. Bu dashboard sadece “CPU. RAM gösteriyorum” tarzı sığ bir şey değil — Manticore Search’e özel metrikler içeriyor, yani gerçekten arama motorunuzun ne hâlde olduğunu anlıyorsunuz. Bu konuyla ilgili Python Paketlerinde Gizli Regex Tehlikesi: 20 Kütüphane Ne Gösterdi? yazımıza da göz atmanızı tavsiye ederim.
Temel Metrikler
İlk bakışta göreceğiniz şeyler: sorgu sayısı (queries per second), ortalama. P99 latency, aktif worker sayısı, queue derinliği. Bunlar zaten olmazsa olmaz metrikler, tabi. Ama işin güzel tarafı hepsinin aynı zaman ekseninde yan yana durması — az önce anlattığım “her metrik tek başına iyi ama bütün kötü” durumunu tam da bu şekilde yakalıyorsunuz.
p99 latency meselesi özellikle kritik. Ortalama latency sızı yaniltır — 100 sorgudan 95’i 10ms’de dönüyor olabilir ama kalan 5’i tam 2 saniye sürüyorsa, ortalama hâlâ güzel görünür. Ama o 5 kullanıcı deliriyordur. p99 bunu gösterir. Ortalamaya bakmayın, p99’a bakın. Bu konuyla ilgili PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza da göz atmanızı tavsiye ederim.
Worker Kullanımı ve Queue
Worker’ların ne kadar meşgul olduğunu ve request queue’nün büyüyüp büyümediğini tek bakışta görebilmek… Açık konuşayım, bu benim için en değerli panel. Çünkü queue büyümeye başladığında, henüz kullanıcılar şikayet etmeden müdahale edebiliyorsunuz. Proaktif monitoring işte tam olarak bu.
2024 başında kendi projemde — küçük bir doküman arama servisi — benzer bir queue problemiyle karşılaşmıştım. O zaman Grafana’yı elle kurmuştum, custom dashboard yapmıştım, Prometheus exporter ayarlamıştım; toplamda yarım gün gitti. Bu hazır çözüm o zamanlar olsaydı keşke, valla. Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik.
Yerleşik Alert’ler
Dashboard ile birlikte önceden tanımlanmış alert kuralları da geliyor. Queue belirli bir eşiği aştığında, worker utilization sürekli yüksek kaldığında veya bir node yanit vermemeye başladığında bildirim alabiliyorsunuz. Tabi Grafana’nın alert kanallarını — Slack, email, PagerDuty vs. — yapılandırmanız gerekiyor ama kuralların kendisi hazır geliyor. Bu bile başlı başına bir zaman tasarrufu.
Monitoring’in amacı sorun çıktığında haber vermek değil — sorun çıkmadan önce sinyalleri yakalamak. Bu dashboard tam da bunu yapıyor: trendleri görüyorsunuz, anı değişiklikleri fark ediyorsunuz.
Küçük Proje mi, Büyük Küme mi?
Peki, bir şey dikkatimi çekti: Şimdi şunu sormak lazım: bu çözüm kimin işine yarar?
İşte tam da bu noktada devreye giriyor.
Eğer tek bir Manticore node’u çalıştıran küçük bir startup’sanız, bu dashboard fazlasıyla yeterli — hatta belki de monitoring için ayıracağınız zamanın tamamını kurtarır. Tek komutla çalışıyor, bakım istemiyor, kaynak tüketimi minimal. Gel gelelim enterprise seviyede, diyelim 10-15 node’lük bir Manticore kümesi, durum biraz farklılaşıyor. Dashboard yine işe yarar ama muhtemelen ek metrikler, custom panel’ler ve belki de ayrı bir Prometheus instance’ı isteyeceksiniz. Hazır dashboard’u başlangıç noktası alıp üstüne ekleme yapmak bence en mantıklı yaklaşım.
Dürüst olmak gerekirse, Ha bu arada, bir de güvenlik meselesi var (buna dikkat edin). Varsayılan olarak anonim admin erişimi açık geliyor. Geliştirme ortamı için sorun değil. Production’da büyük ihtimalle GF_AUTH_ENABLED=true yapın — yoksa dashboard’unuza herkes erişebilir, bu da tüm metriklerinizin açık olması demek. Ciddi söylüyorum.
Size bir şey söyleyeyim, Monitoring konusunda gürültülü alert’lerden bıkmış olanlar için daha önce yazdığımız Aşırı Gürültülü Uyarıları Susturmanın Akıllı Yolu: Pratik Rehber yazısına da göz atmanızı öneririm — Grafana alert’lerini anlamlı hâle getirmek için faydalı ipuçları var orada.
Pratik İpuçları ve Dikkat Edilecekler
Bu dashboard’u kullanırken birkaç şeyi aklınızda tutun:
- Veri saklama süresi: Container içindeki Prometheus varsayılan retention ile çalışıyor. Uzun vadeli veri istiyorsanız volume mount yapmanız gerekiyor, yoksa container durduğunda veriler uçar.
- Port çakışması: Zaten 3000 portunda bir servis çalışıyorsa — mesela başka bir Grafana instance’ı —
-p 3001:3000gibi farklı bir port mapping yapın. (bu kritik) - Kaynak tüketimi: Prometheus + Grafana birlikte çalıştığı için container’ın bellek kullanımı yükselebilir. Mesela de çok sayıda node izliyorsanız en az 512MB RAM ayırmanızı tavsiye ederim.
- Güncellemeler:
manticoresearch/dashboardimage’ı güncellendiğindedocker pullyapmayı unutmayın. Yeni metrikler ve alert kuralları eklenebilir. (bence en önemlisi)
İşte, bir de şunu ekleyeyim — dür, bu önemli — Manticore Search’ün kendisi de gelişiyor. Zaman zaman yeni metrikler ekleniyor. Dashboard’un bunları desteklemesi için image’ı güncel tutmak şart. Ben bir keresinde eski image ile yeni Manticore sürümünü izlemeye çalıştım, bazı paneller bomboş kaldı. Sebebini anlamam 15 dakikamı aldı. Version uyumu dediğin şey, küçük ama canı sıkan bir detay.
Tabi, API yük testi yapıyorsanız. Manticore Search’ün performansını stres altında ölçmek istiyorsanız, Tarayıcıda Çalışan Sıfır Kurulumlu API Yük Testi yazımız da işinize yarayabilir.
Eksik Bulduğum Taraflar
Her şey güllük gülistanlık mı? Hayır. Birkaç eksik var, bunları da söylemek lazım.
Şunu söyleyeyim, Baştan başlayalım: dashboard’un kişiselleştirme imkânı sınırlı. Yani Grafana’yı biliyorsanız her şeyi değiştirebilirsiniz tabi ama “hazır” dashboard üzerinde yapacağınız değişiklikler container yeniden başlatıldığında kaybolabiliyor. Persistent storage konusunda dokümantasyon biraz yetersiz kalmış — bence en can sıkıcı nokta bu.
İkincisi — ve bu beni biraz hayal kırıklığına uğrattı açıkçası — log aggregation yok. Metrikler güzel ama bazen log’lara da bakmak gerekiyor. Loki entegrasyonu veya en azından Manticore log’larını Grafana’da görebilme özelliği olsaydı çok daha etraflı bir çözüm olurdu. Tahmin eder mısınız? Belki ileriki sürümlerde gelir, kim bilir.
Üçüncüsü, multi-tenancy desteği yok. Yani birden fazla takimin farklı izinlerle aynı dashboard’u kullanması gibi bir senaryo için ek yapılandırma gerekiyor. Kurumsal ortamlarda bu bazen sorun çıkarabiliyor.
Küçük bir detay: Güzel özellik ama henüz tam olgunlaşmamış. Biraz daha pişmesi lazım. Yine de şu anki hâliyle bile, hiç monitoring olmayan bir Manticore kurulumuna kıyasla devasa bir fark var — bunu teslim etmek lazım.
Sıkça Sorulan Sorular
Manticore Search dashboard’u için Docker dışında bir kurulum yöntemi var mı?
Şu an için resmî desteklenen yöntem Docker ile kurulum. Ama container içindeki Grafana dashboard JSON’larını export edip kendi Grafana + Prometheus kurulumunuza import edebilirsiniz. Biraz manuel iş gerektirir ama mümkün.
Dashboard ne kadar kaynak tüketiyor?
Tek node izliyorsanız yaklaşık 256-512MB RAM yeterli oluyor. Çok sayıda node izlediğinizde Prometheus’un bellek kullanımı artacaktır. 10+ node için en az 1GB RAM ayırmanızı öneriyorum. CPU tarafında ciddi bir yük yok.
Grafana’daki alert’leri Slack veya email ile alabilir mıyım?
Evet, Grafana’nın kendi notification channel özelliğini kullanarak Slack, email, PagerDuty, Telegram gibi kanallara bildirim gönderebilirsiniz. Dashboard’daki alert kuralları hazır geliyor, siz sadece bildirim kanalını tanımlıyorsunuz.
Mevcut Grafana kurulumuma bu dashboard’u ekleyebilir mıyım?
Evet. Dashboard JSON dosyasını Manticore’un GitHub reposundan alıp mevcut Grafana’nıza import edebilirsiniz. Ancak Prometheus tarafında Manticore exporter’ını ayrıca yapılandırmanız gerekecektir. Hazır container tüm bunları otomatik yapıyor, ayrı kurulumda bu adımları siz hallediyorsunuz.
Dashboard container’ı durdurursam metrik verileri kaybolur mu?
Evet, varsayılan kurulumda container durdurulduğunda Prometheus verileri kaybolur. Verileri kalıcı yapmak için Docker volume mount kullanmanız gerekiyor. Örneğin -v prometheus-data:/prometheus gibi bir volume tanımlayabilirsiniz.
Kaynaklar ve İleri Okuma
İlginç olan şu ki, Manticore Search GitHub Deposu
Manticore Search Resmî Dokümantasyonu
Manticore Dashboard Docker Hub Sayfası (bizzat test ettim)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar
Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.


