Bak şimdi, Geçen ay İstanbul’daki bir fintech ekibiyle oturmuştum — aynı cümleyi tam üç kere duydum: “Loglarda hiçbir şey yok ama ajan saçmalıyor.” İşin aslı şu ki klasik izleme araçları burada tökezliyor. Çünkü LangChain ajanı sıradan bir API servisi gibi davranmıyor; düşünüyor (ya da düşünüyormuş gibi yapıyor), araç çağırıyor, bazen kendi kendine döngüye giriyor ve ortada patlayan bir hata bırakmadan, sessizce, kaliteyi aşağı çekiyor.
Bilmem anlatabiliyor muyum, Bunu ilk kez 2023 sonbaharında fark ettim — küçük bir müşteri destek botu üzerinde test yapıyordum. Uygulama gayet sağlıklı görünüyordu: CPU normal, yanit süreleri kabul edilebilir, hata oranı düşük… ama kullanıcılar “aynı şeyi tekrar soruyor” diye şikâyet etmeye başladı. Yani sistem çalışıyordu ama iş yapmıyordu. Kulağa tuhaf geliyor, biliyorum. Ama agent dünyasında bu tablo bayağı tanıdık aslında.
Dürüst olmak gerekirse, Bu yazıda lafı gevelemeden şunu anlatacağım: LangChain ajanlarını üretimde izlemek istiyorsanız, gözünüzü sadece altyapı metriklerine değil karar zincirine de çevirmeniz lazım. Hangi araç seçildi? Kaç adım sürdü? Aynı araca kaç kere dönüldü? Token nerede yandı? Bunlar olmadan kör uçuş yapıyorsunuz. Nokta.
Neden Klasik Monitoring Yetmiyor?
Doğrusu, APM araçları güzel şeyler veriyor: latency, statüs code, memory kullanımı… Hepsi iş görüyor, yanlış anlamayın. Ama ajanın içindeki mantık bozulduğunda bunların büyük çoğunluğu size hiçbir şey söylemiyor. Bir ajan 30 saniye boyunca düşünme döngüsünde kalabilir, yanlış aracı defalarca çağırabilir ya da cevap kalitesini yavaş yavaş, fark ettirmeden aşağı çekebilir — yine de dışarıdan bakınca sistem “sağlıklı” görünür.
Bak şimdi, en can sıkıcı taraf tam da bu: bu sorunların çoğu crash değil (ben de ilk duyduğumda şaşırmıştım). Alarm çaldıracak kadar sert değiller. Bir startup’ta başlangıçta fark etmeyebilirsiniz — itiraz edebilirsiniz tabi — çünkü trafik azdır, her şey gözle takıp edilebilir durumdadır; ama enterprise seviyede aynı sorun maliyet şişmesi ve kullanıcı kaybı olarak geri gelir. En çok da de de de token tüketimi artmaya başlarsa fatura da tatlı tatlı büyür… tatsız kısım sonra geliyor tabii.
Bir de şu var. Geleneksel metrikler “ne oldu?”yu söyler ama “neden oldu?”yu pek anlatmaz. Oysa agent’ta asıl mesele neden kısmında saklıdır — hangi prompt neyi tetikledi, hangi tool çağrısı hatalıydı, model neden o kararı verdi. İşte bunlar sizin gerçek denetim yüzeyiniz.
Ajan Odaklı Metrikler Nasıl Kurulur?
Bu haberi hazırlarken önce kendi notlarımı karıştırdım. 2024 başında yaptığım bir PoC’de en çok işime yarayan şey tek tek teknik göstergeler değil, birlikte anlam taşıyan sinyallerdi. Mesela thought chain depth tek başına havalı duruyor olabilir —. Tool success rate ile beraber okuyunca tablo netleşiyor. İkisi birden varsa gerçekten bir şey görüyorsunuz; biri eksikse körün fili tarif etmesine dönüyor iş.
İtiraf edeyim, Aşağıdaki metrik seti benim gözümde sağlam bir başlangıç noktası veriyor:
| Metrik | Ne Ölçer? | Neden Önemli? |
|---|---|---|
| thought_chain_depth | Araç seçimine kadar kaç düşünme adımı geçtiği | Döngüye giren ajanları yakalar |
| tool_success_rate | Araç çağrılarının başarı oranı | Yanlış tool seçimini gösterir |
| token_efficiency | Girdi/çıktı token dengesi | Maliyet ve verimlilik için hayatı sinyal verir |
| decision_time | İlk karar için geçen süre | Ajanın ne kadar hızlı yön aldığını gösterir |
Her biri size farklı bir açıdan sağlık raporu veriyor. Mesela decision_time yükseliyorsa model “karar veremiyor” olabilir. Tool_success_rate düşüyorsa doğru aracı bulamıyordur. Token_efficiency bozulduysa prompt tasarımınızda gereksiz şişkinlik var demektir — ve bu şişkinlik faturaya yansır, inan.
Ajan izleme işi sadece log toplamak değil; karar ağacını görünür yapmak demek.
Küçük startup ile kurumsal yapı aynı değil
Küçük ekiplerde fazla metrik sızı yorar. Ben olsam önce üç şeye odaklanırım: toplam adım sayısı, araç başarısı ve token maliyeti. Bu kadar yeterli olabilir — ekip zaten her an müdahale edebilir durumdadır, her şeyi görebiliyordur. Daha fazla bilgi için Python Performans Darboğazı: Tahmin Etme, Ölç yazımıza bakabilirsiniz. Bu konuyla ilgili Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza da göz atmanızı tavsiye ederim.
Şunu fark ettim: Kurumsal tarafta işe olay başka yere gidiyor. Orada çoklu takım çalışması var; güvenlik ekibi ayrı bakıyor, ürün ekibi ayrı bakıyor, finans ekibi bile token faturasıyla ilgileniyor. O yüzden metriği böl tutmak mantıklı — tabi gereksiz gürültü üretmeden. Bu dengeyi kurmak bazen asıl meydan okuma oluyor.
Şimdi gelelim işin can alıcı noktasına. FERPA Uyumlu RAG: Kurumsal Sistemler Nerede Çuvallıyor? yazımızda bu konuya da değinmiştik.
Callback Handler ile İçgörü Toplamak
Bence bu konunun en pratik tarafı custom callback handler yazmak. Yani ajanın her adımında küçük notlar toplayıp dışarı göndermek… basit gibi duruyor. Ama etkisi büyük, çünkü olayın tam içine giriyorsunuz — artık dışarıdan tahmin etmiyorsunuz, içeriden bakıyorsunuz.
from langchain.callbacks.base import BaseCallbackHandler
from datetime import datetime
class AgentMetricsHandler(BaseCallbackHandler):
def __init__(self):
self.thought_count = 0
self.tools_used = []
self.start_time = None
def on_agent_action(self, action, kwargs):
self.thought_count += 1
self.tools_used.append(action.tool)
payload = {
"metric": "agent_action",
"step": self.thought_count,
"tool": action.tool,
"timestamp": datetime.utcnow().isoformat(),
"reasoning": action.tool_input,
}
self._send_metric(payload)
def on_agent_finish(self, finish, kwargs):
elapsed = datetime.utcnow() — self.start_time
payload = {
"metric": "agent_finish",
"total_steps": self.thought_count,
"tools_used": list(set(self.tools_used)),
"execution_ms": elapsed.total_seconds() * 1000,
}
self._send_metric(payload)Bunu ilk gördüğümde şöyle düşündüm: “Hepsi bu mu?” Evet. Aslında çoğu zaman hepsi bu kadar basit başlıyor. Zor olan kodu yazmak değil — doğru anlarda doğru sinyali almak ve bunu panoya anlamlı şekilde taşımak. O kısım emek istiyor. Next.js ve PostgreSQL ile Ölçeklenen SaaS Kurmak yazımızda bu konuya da değinmiştik.
Dikkat etmeniz gereken şu: callback yalnızca sayısal veri üretmemeli, bağlam da taşımalı. Hangi prompt varyantıyla geldiğini bilmiyorsanız metrik tek başına yarım kalır. Hangi kullanıcı segmentinin daha çok döngü ürettiğini görmezseniz iyileştirme kör ölür. Veri toplamak kolay… anlam çıkarmak işe esas iş.
Sessiz Arızaları Yakalamanın En İyi Yolu Ne?
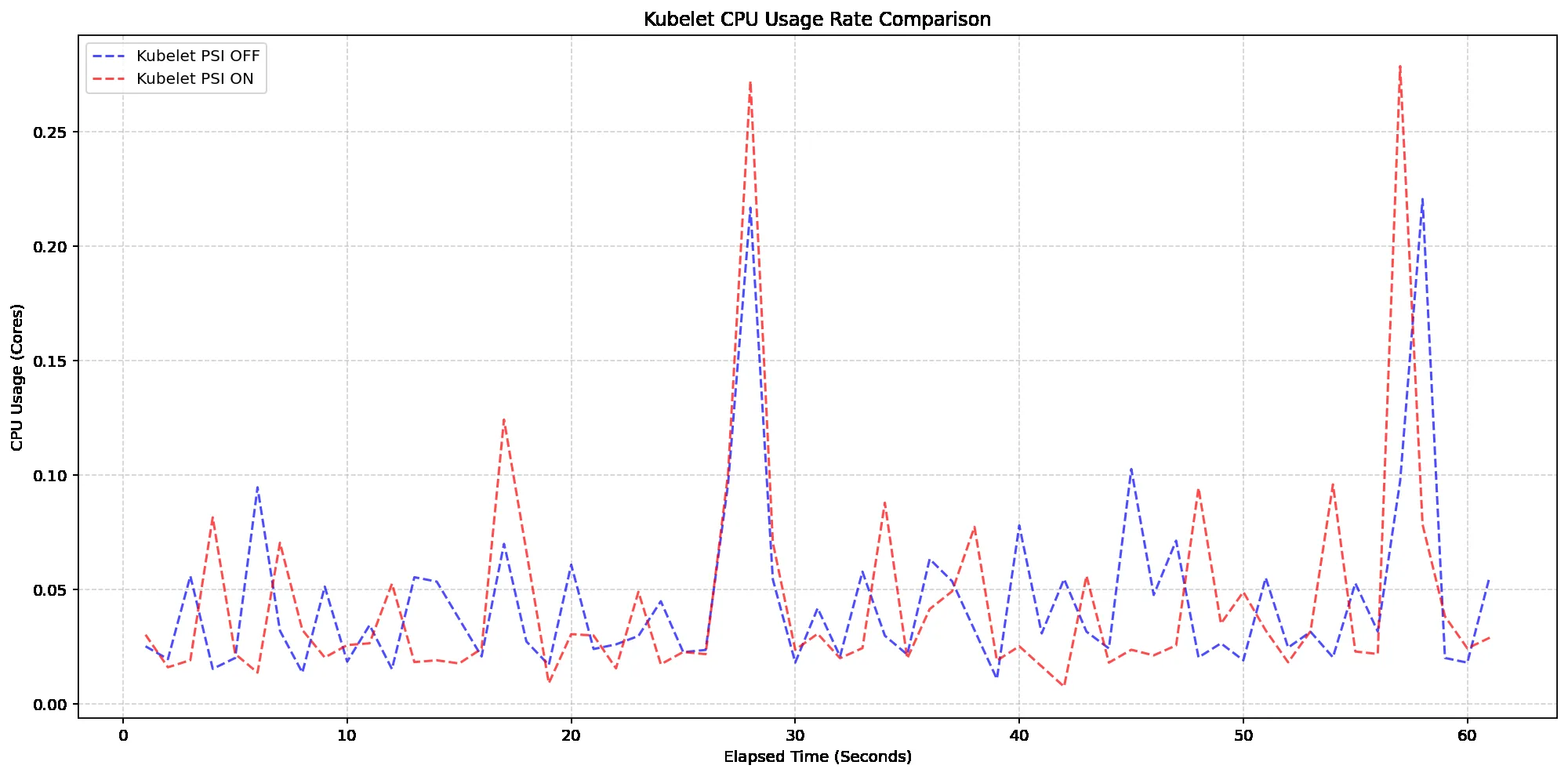
Sessiz arızalar beni hep uğraştırdı doğrusu. Londra’da çalışan bir SaaS ürünü üzerinde çalışan bir arkadaşım bunu bizzat yaşadı. Sistem hata vermiyordu ama satış destek botu yanlış bilgi dağıtıyordu. Üstelik tam üç hafta kimse fark etmedi. Üç hafta.
İşte böyle durumlarda alarm yerine davranış analizi gerekiyor. Aynı soru geldiğinde farklı cevap üretiyor mu? Aynı görevde step sayısı sapıyor mu? Aynı tool’a geri dönüp duruyor mu? Bu soruların cevabı varsa problemin omurgasını buluyorsunuz demektir. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
- Döngü tespiti için step sayısına üst sınır koyun.
- Aynı tool’un peş peşe kullanımını ayrı uyarıya bağlayın.
- Cevap uzunluğu veya içerik benzerliği üzerinden kalite sapmasını ölçün. — bunu es geçmeyin
- Baz hat örneklerini elle etiketleyip geriye dönük analiz yapın.
- Maliyeti unutmayın; bazı sessiz arızalar doğrudan para yakar.
Neyse, uzatmayayım. Burada amaç modeli cezalandırmak değil. Ama siz ölçmezseniz modelin ne zaman yavaşladığını ya da kafayı hafifçe karıştırdığını anlayamazsınız. Benim deneyimimde en işe yarayan yöntemlerden biri haftalık trace incelemesi oldu — özellikle pazar akşamları gelen uzun oturumlara baktığınızda garip örüntüler hemen göze çarpıyor (buna dikkat edin)
Peki Üretimde Nasıl Bir İzleme Stratejisi Kurmalı?
Düzgün çalışan strateji üç katmanlı oluyor bana göre. Birinci katman altyapı sağlığı: API erişimi var mı, queue dolmuş mu, DB cevap veriyor mu? İkinci katman ajan sağlığı: hangi tool çağrıldı, kaç step sürdü, hangi input dönüşe sebep oldu? Üçüncü katman işe iş etkisi — kullanıcı üstlendiği işi tamamladı mı, destek talebi açtı mı, maliyet nerede arttı?
Editör olarak kendi projelerimde şu ayrımı seviyorum: “servis çalışıyor” ile “ürün fayda üretiyor” arasındaki fark açık kalsın. Çünkü bazı panolar size pembe tablo çizdirir… gerçek hayatta işe müşteri hâlâ memnun değildir. Bu küçük ayrıntıyı atlayan ekipler sonra neden churn arttığını anlamakta zorlanır — ben de buna birkaç kez şahsen takıldım, özellikle Ankara’da yürüttüğüm bir kurumsal demo sırasında. Acı ama öğretici.
Hızlı kontrol listesi
- Ajan adımlarını trace edin.
- Araç başarı oranını çıkarın.
- Lokal eşikler belirleyin.
- Toksik prompt örneklerini saklayın.
- Maliyet/başarı dengesini haftalık kıyaslayın.
Sıkça Sorulan Sorular
LangChain ajanlarında en önemli metrik hangisi?>
En kritik metrik kullanım senaryosuna göre değişir ama çoğu ekip için thought chain depth ve tool success rate ilk sırada gelir. Çünkü ikisi birlikte ajanın gereksiz dolaşıma girip girmediğini gösterir.
Sadece latency takibi yeterli mi?
Hayır,tek başına yeterli değil. Ajan hızlı olup yanlış sonuç üretebilir ya da yavaş olup yine doğru işi yapabilir. Karar sürecini görmeden sağlıklı yorum yapmak zor ölür.
Küçük ekipler nasıl başlamalı?
Önce üç temel sinyal toplayın:adım sayısı,tool başarısı ve token maliyeti. Sonra trace örneklerini elle inceleyin. Fazla karmaşık dashboard ile başlamayın,sonra boğuyor.
Sessiz hata nasıl anlaşılır?
Aynı sorguda kalite düşüşünü,tekrar eden araç çağrılarını ve beklenmedik uzun oturumları izleyin. Bunlar çoğu sessiz hatanın ilk işaretidir. Kullanıcı şikâyeti gelmeden yakalarsanız iyi etmişsiniz demektir.
Kai nak and Ileri Okuma》
LangChain Resmî Dokümantasyonua href=”https://github.com/langchain-ai/langchain” target=”_blank” rel=”noopener”>LangChain GitHub SayfasıYapay Zekâ Ajaný Ne Yaptı?: Kanıtlayabiliyor musun?
Kaynaklar ve İleri Okuma
Azure’da İzleme ve Gözlemlenebilirlik Rehberi (Monitoring)
Application Insights Genel Bakış
Azure AI Foundry / OpenAI ile Nasıl Yapılır Dokümantasyonu

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.