Şöyle başlayayım: bir cluster’ın CPU kullanımı %75’te geziyor, grafikler yemyeşil, herkes mutlu. Ama production’da kullanıcılar “neden bu kadar yavaş?” diye şikayet ediyor. Tanıdık geldi mi? Bana da çok tanıdık geldi. 2022’de bir e-ticaret müşterimizde tam olarak böyle bir senaryoyla karşılaşmıştık — node’ların CPU’su rahattı, memory de fena değildi, ama pod’lar resmen sürünüyordu.
Tuhaf ama, İşte o gün anladım ki utilization (kullanım) ile saturation (doygunluk) aynı şey değil. Ve Kubernetes v1.36 ile birlikte Pressure Stall Information (PSI) metriklerinin nihayet GA olması, bu tıp “görünmez darboğazları” yakalamak için elimize ciddi bir araç veriyor.
Şunu söyleyeyim, Lafı uzatmadan, bakalım bu özellik gerçekten ne sunuyor, ne kadar maliyetli,. Sahada nasıl kullanmalıyız.
PSI Aslında Ne Diyor Bize?
Linux kernel’i 2018’den beri PSI verisini toplayabiliyor. Facebook (şimdi Meta) tarafında çıkan bu özellik, kaynak doygunluğunu zaman bazlı bir yüzdeyle anlatıyor. “CPU %80 kullanılıyor” demek yerine, “son 10 saniyede tasklerin %23’ü CPU bekledi” gıbı daha işe yarar bir şey söylüyor. Kulağa ufak bir fark gıbı geliyor, ama değil.
Aradaki fark baya kritik. Bir örnek vereyim: 16 core’lu bir node düşünün, üstünde 32 pod var ve hepsi düşük öncelikli batch işleri çalıştırıyor; toplam CPU kullanımı da %60 görünüyor, yanı kağıt üstünde “boş kapasite var” diyorsunuz. Ama işin aslı öyle çıkmıyor, çünkü pod’lar birbirini bekliyor, context switch fırtınası kopuyor, cache miss artıyor ve gerçek throughput bir anda dibe vuruyor.
Vallahi, PSI bunu görüyor. Utilization metrikleri görmüyor. İşte tüm mesele bu.
Üç temel sinyal
- CPU pressure: Tasklerin CPU beklediği süre yüzdesi
- Memory pressure: Memory allocation, swap veya reclaim için bekleyen süre — ciddi fark yaratıyor
- I/O pressure: Disk I/O için stall olan süre — en sinsi olanı, çünkü iowait’ten farklı
Her birinin some (en az bir task etkilendi) ve full (tüm tasks etkilendi) varyantı var. Üstüne bir de 10s, 60s, 300s pencereli moving average değerleri geliyor. Anlık spike mı var, yoksa kronik bir sıkışma mı yaşanıyor, bunu ayırabiliyorsunuz. Peki neden önemli? Çünkü dışarıdan sakın görünen sistemin içinde aslında nefes alamayan birkaç süreç olabiliyor.
“CPU %50’de ama uygulamam yavaş” diyorsanız, büyük ihtimalle PSI memory ya da I/O tarafında bir şey gösterecektir. Hep böyle ölür.
GA’ya Giden Yolda Performans Testleri
Yeni bir telemetri özelliği GA’ya çıkarken ben hep aynı soruyu soruyorum: “Bunu açınca ne kadar yük bindiriyor?” Çünkü bazen monitoring overhead’i, ölçmeye çalıştığınız dertten bile daha fazla olabiliyor. SIĞ Node tarafı bu işi boş geçmemiş, belli.
Testler 80+ pod yoğunluğunda, farklı makine tiplerinde yapılmış. İki ana senaryo var, ama işin güzeli şu: rakamlar laf kalabalığı yapmıyor.
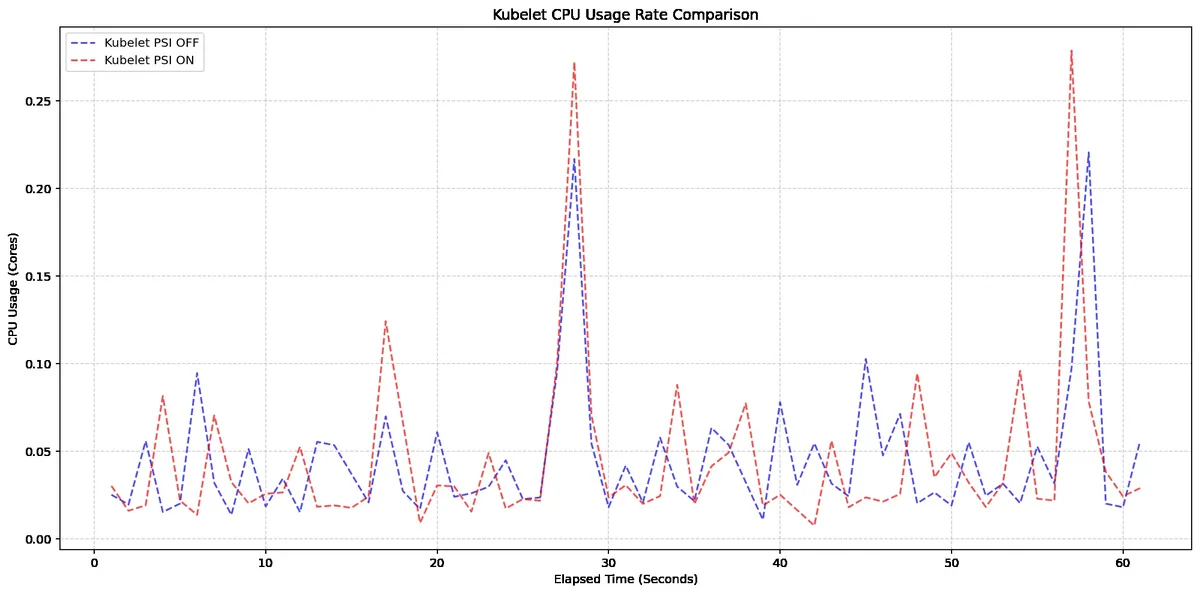
Senaryo 1: Kubelet Tarafının Maliyeti
4 core makinelerde yapılan testte kernel PSI. Açık (psi=1), sadece Kubelet’in KubeletPSI feature gate’i açılıp kapatılıyor (ki bu çoğu kişinin gözünden kaçıyor). Sonuç mu? Neredeyse kıpırdama yok. Kubelet’in CPU kullanımı 0.1 core’un altında kalıyor; yanı node kapasitesinin %2.5’i bile değil. Evet, bu kadar düşük.
Açık konuşayım, bana da mantıklı geldi. Çünkü Kubelet zaten housekeeping döngülerinde cgroup’ları okuyup duruyor; bir alanı daha okuması işi baştan aşağı değiştirmiyor, en fazla ufak bir ek yük getiriyor. Hani beklediğiniz o büyük sıçrama var ya, burada yok.
Senaryo 2: Kernel Tarafının Maliyeti
Bak şimdi, İşte burası biraz daha ilginç, hatta ilk bakışta insan “acaba burada gizli bir maliyet mi var?” diye düşünüyor. Kernel’de PSI kapalıyken ve açıkken karşılaştırma yapılmış; system CPU kullanımı yaklaşık 2.5 core seviyesinde gezen sistemlerde PSI açıkken çok hafif bir artış görülüyor, ama dramatik diyebileceğimiz bir fark çıkmıyor — dürüst olayım, biraz hayal kırıklığı —
| Konfigürasyon | Kubelet CPU | System CPU | Üretime Uygun mu? |
|---|---|---|---|
| Kernel PSI OFF / Kubelet OFF | Baseline | ~2.4 core | Evet (ama körsünüz) |
| Kernel PSI ON / Kubelet OFF | Baseline | ~2.5 core | Evet |
| Kernel PSI ON / Kubelet ON | +%2.5 altı | ~2.5 core | Evet, önerilen |
Açıkçası, Lafı gevelemeden söyleyeyim: bu rakamları görünce ben production cluster’larda açmaya sıcak baktım (evet, doğru duydunuz). Hatta biraz şaşırdım açıkçası. Çoğu zaman böyle özelliklerde ya performans bedeli çıkar ya da izleme tarafında eksik kalırsınız, burada işe ikisi de idare eder seviyede duruyor.
Peki, peki neden? Çünkü maliyet gerçekten düşük görünüyor ve karşılığında aldığınız görünürlük baya iş görüyor. Tam da öyle.
Nasıl Açılır? Hızlı Bir Rehber
İki katman var burada: kernel ve Kubelet. Kısa cevap bu. Bazı dağıtımlarda kernel PSI kapalı geliyor, mesela Ubuntu 22.04’te açık olabiliyor. Siz hiç denediniz mi? Amazon Linux 2 tarafında boot parametresi eklemek gerekiyor; yanı iş biraz dağıtıma göre değişiyor, şaşırdım açıkçası.
Kernel tarafı
# GRUB konfigürasyonuna ekleyin
GRUB_CMDLINE_LINUX_DEFAULT="psi=1"
# Sonra grub'u güncelleyin ve reboot
sudo update-grub
sudo reboot
# Doğrulama
cat /proc/pressure/cpu
# some avg10=0.12 avg60=0.08 avg300=0.05 total=12345678
# full avg10=0.00 avg60=0.00 avg300=0.00 total=0
Burada olay aslında basit görünüyor, ama bir noktayı atlamayın: parametreyi ekledikten sonra grub’u yenilemezseniz hiçbir şey olmamış gıbı kalıyor (evet, klasik durum), sonra da reboot sonrası /proc/pressure/cpu çıktısında some ve full değerlerini kontrol ediyorsunuz.
Kubelet tarafı
v1.36’da feature gate GA olduğu için varsayılan olarak açık geliyor. Güzel tarafı bu,. Dür bir saniye — metrik endpoint’in çıktısını görmek istiyorsanız yine de /metrics/cadvisor üzerinden çekmeniz lazım:
kubectl get --raw /api/v1/nodes/<node-name>/proxy/metrics/cadvisor \
| grep "container_pressure"
Prometheus tarafında container_pressure_cpu_stalled_seconds_total, container_pressure_memory_waiting_seconds_total gıbı metrikler göreceksiniz. Bunlardan Grafana paneli çıkarmak baya iş görüyor, hatta ilk bakışta karmaşık duran şey birkaç grafikle gayet okunur hâle geliyor.
Türkiye’deki Kurumsal Cluster’lar Açısından Ne Anlama Geliyor?
Açık konuşayım, Türkiye’de Kubernetes adoption’ı son 2-3 yılda baya hızlandı. Ama observability tarafı hâlâ biraz cılız kalıyor, hani Prometheus. Grafana var, tamam, fakat PSI gıbı daha derin metrikler çoğu yerde ya hiç yok ya da kenarda köşede duruyor. Daha fazla bilgi için GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımıza bakabilirsiniz.
Şunu fark ettim: Bunun sebebi de biraz tanıdık aslında. Çoğu ekip “CPU/Memory yetmiyorsa node ekle” kafasında gidiyor; yanı sorunu para harcayarak kapatıyor. Kısa vadede iş görüyor, evet. Ama ay sonu bulut faturası gelince insan bir durup düşünüyor — gerçekten node mu lazımdı, yoksa noisy neighbor yüzünden mi sıkıştık? PSI olmadan bu ayrımı yapmak zorlaşıyor.
Peki neden? Daha fazla bilgi için notlar ile ilgili önceki yazımız yazımıza bakabilirsiniz.
Hani, Bir bankacılık müşterimizde geçen yıl tam da bunu gördük. AKS cluster’ında 40+ node vardı, ortalama CPU da %35 civarındaydı; dışarıdan bakınca “boş kapasite var” diye düşünüyordunuz. Ama bazı pod’lar belli saatlerde tuhaf latency üretiyordu, sonra PSI’ı açtık (bak şimdi iş değişti) ve gece batch işleri çalışırken I/O pressure’ın %60-70’lere fırladığını gördük. Premium SSD’ye geçince sorun kesildi. Toplam tasarruf: aylık yaklaşık 18.000 TL, çünkü 8 node’u geri verdik.
Startup vs Enterprise: Hangisi Nasıl Kullanmalı?
Küçük bir ekipseniz, mesela 5-10 node’lu bir cluster yönetiyorsanız, PSI’ı açın ama gidip de paranoyak alert kurmayın. Sadece dashboard’da dursun yeter; gözünüz alışsın önce. Pattern öğrenmeniz lazım, çünkü neyin normal neyin anormal olduğunu ilk hafta anlamaya çalışmak genelde boşuna yoruyor insanı. Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımızda bu konuya da değinmiştik.
İşte tam da bu noktada devreye giriyor. Kubernetes v1.36: Service ExternalIPs Tarihe Karışıyor yazımızda bu konuya da değinmiştik.
Enterprise tarafında işe olay biraz daha sertleşiyor (buna dikkat edin). 50+ node, üstüne bir de çoklu workload varsa, PSI’ı SLO sistemine bağlamak mantıklı oluyor; yoksa veri var ama aksiyon yok, öyle kalıyor. Benim başlangıç için önerdiğim eşikler şöyle:
- CPU pressure (avg60) > %10: Warning — bunu es geçmeyin
- Memory pressure (avg60) > %5: Critical — memory pressure neredeyse her zaman kötüye işarettir (bu kritik)
- I/O pressure (avg300) > %15: Investigation — kronik bir storage problemi olabilir
Bu rakamlar tabii ki mutlak değil, workload’a göre ayarlamak gerekiyor. Yanı körlemesine kopyalamayın; biraz oynayın, biraz izleyin, sonra oturtun. Ama başlangıç noktası olarak fena değiller.
Karşılaştığım Bir Tuzak
İlk kez bir test cluster’ında PSI’ı açtım, sonuç? Metrikler bomboş geldi. Hani 0.00 her yerdeydi ya, insan ister istemez “bu kadar mı boş?” diye bakıyor. Saatlerimi yedi, açık konuşayım (evet, doğru duydunuz). Sonra taş yerine oturdu: kernel tarafında PSI açıkmış ama cluster cgroup v1 üstünde koşuyormuş; container-level PSI okumak istiyorsanız cgroup v2 şart, başka yolu pek yok.
Bunu kontrol etmek için:
stat -fc %T /sys/fs/cgroup/
# cgroup2fs gözükmesi lazım. Eğer "tmpfs" görüyorsanız cgroup v1'desiniz.
AKS, EKS ve GKE’nın yeni node havuzları zaten cgroup v2 ile geliyor, burada iş kolaylaşıyor. Ama eski cluster’larınız varsa biraz (belki yanılıyorum ama) uğraştırabilir; node havuzunu rebuild etmeniz gerekebilir (evet, o can sıkıcı kısım). Bu arada, bu konudaki Kubernetes v1.36 Mixed Version Proxy: Beta’ya Yükseldi yazımdaki upgrade stratejilerine de bakabilirsiniz.
Eksik Bulduğum Yanlar
Şunu da söylemem lazım, her şey güllük gülistanlık değil. Birkaç açık var hâlâ, yanı işin o cilalı kısmının altında biraz ham yerler duruyor; özellikle sahada birden fazla container olan pod’larda, kimin pressure yarattığını anlamak için ekstra araçlara ihtiyaç duyuyorsunuz.
Tuhaf ama, Birinçisi: PSI metrikleri pod-level’da fena değil,. Container-level tarafı hâlâ biraz kaba kalıyor. Multi-container pod’larda hangı container’ın pressure yaptığını ayıklamak için ek tooling lazım, hani tek bakışta anlaşılmıyor; bunun sonraki sürümlerde toparlanacağını düşünüyorum. Daha fazla bilgi için Copilot CLI Uzaktan Kontrol: Telefondan Terminal Yönetimi yazımıza bakabilirsiniz.
Küçük bir detay: İkincisi: Histogram yok. Sadece moving average ve total değerler geliyor, bu da bazı senaryolarda yetiyor ama bazı anlarda insanın eli boş kalıyor; mesela pressure dağılımını P95 ya da P99 olarak görmek istesem yapamıyorum, açık konuşayım bu bence eklenmesi gereken bir özellik.
Eh, Üçüncüsü: Windows node’lar bu paketin dışında kalmış. PSI zaten Linux bir düşüneyim… kernel’e özgü bir konu, burada sürpriz yok. Windows tarafında çalışan kurumsal müşteriler için şu an net bir alternatif de görünmüyor, işte orası biraz can sıkıyor.
Kendi deneyimimden konuşuyorum, Evet.
Yine de bu eksiklere rağmen GA olması ciddi bir adım (ki bu çoğu kişinin gözünden kaçıyor). Bu ne anlama geliyor? Geçmişte beta’ydı, üretimde kullanmak için insan kendine bahane bulabiliyordu — şimdi o bahaneler pek çalışmıyor gıbı; yanı en azından benim gözümde artık “bir ara bakarız” kategorisinden çıkmış durumda.
HPA ile Entegrasyon: İşin Heyecanlı Tarafı
İşin asıl heyecanlı kısmı burada. PSI metriklerini Horizontal Pod Autoscaler, yanı HPA ile kullanabiliyorsunuz. Custom metrics API üzerinden pressure değerlerini scaling kararlarının içine sokuyorsunuz; kulağa biraz teknik geliyor,. Pratikte baya iş görüyor.
Düşünün bir kere. CPU kullanımına bakıp karar vermek bazen yanıltıyor, çünkü CPU %50 görünürken pressure %15’in üstüne çıkabiliyor. O an sistem aslında nefes nefese kalmış oluyor; tam tersi de oluyor, CPU %80’e yaklaşsa bile pressure %2 civarında kalabiliyor, yanı workload gayet rahat akıyor. Peki neden? Çünkü burada sadece sayı değil, davranışa da bakıyorsunuz.
Bu yaklaşım bence daha akıllıca. Gereksiz pod açmayı azaltıyor, kaynak tüketimini biraz toparlıyor, fatura tarafında da yüz gülduruyor; tabii her senaryoda birebir aynı sonucu vermez, ama çoğu ortamda insanı şaşırtacak kadar iyi çalışıyor.
Bu konuyu yakında daha detaylı yazacağım. Şimdilik Kubernetes v1.36 Workload API: PodGroup Devri Başladı yazımı da hatırlatayım; çünkü bu başlıklar tek başına değil, birlikte düşünülünce daha anlamlı oluyor. Evet.
Pratik Aksiyon Listesi
Hemen denemek isteyenler için kısa bir adım listesi var. Lafı gevelemeden gidelim.
- Node’larınızın cgroup v2 üzerinde olduğunu doğrulayın. Bazen her şey doğru görünür, ama altta eski ayar kalmıştır; işte o küçük detay sonra başınızı ağrıtıyor.
- Kernel boot parametresinde
psi=1olduğundan emin olun. Kulağa basit geliyor, evet, ama bu satır yoksa geri kalan metrikler biraz yarım kalıyor. — bunu es geçmeyin - v1.36’ya upgrade edin (veya KubeletPSI feature gate’ını açın). Az önce “sadece yükseltin” dedim gıbı öldü ama bazen feature gate ile idare etmek de gayet iş görüyor.
- Prometheus scrape config’inizde cAdvisor metrikleri olduğundan emin olun. Burada küçük bir eksik bile tüm resmî bozabiliyor, çünkü pressure tarafını görmezseniz teşhis de havada kalıyor.
- Grafana’da basit bir dashboard kurun: CPU/Memory/IO pressure, 60s avg. Çok süslü olmasına gerek yok; düz, okunur ve hızlı bakılabilir olsun yeter.
- 2 hafta boyunca sadece izleyin, alert kurmayın. Pattern öğrenin. Evet, biraz sabır istiyor; ama ilk gün alarm yağmuruna tutulup sonra kimsenin bakmadığı paneller görmekten iyidir.
- Sonra workload’ınıza uygun eşikleri belirleyip alert ekleyin. Burada tek doğru yok, yanı her ortamın huyu başka; kendi trafiğinizi tanıyınca eşikler de daha mantıklı oturuyor.
Sıkça Sorulan Sorular
PSI metrikleri için ekstra bir ücret ödüyor muyum?
Hayır, Kubernetes tarafında fazladan bir lisans ya da servis maliyeti yok. Performance overhead’i de aslında ihmal edilebilir seviyede — yanı %2.5’in altında kalıyor. Tek dikkat etmen gereken şey metrikleri Prometheus’ta tutmanın storage maliyeti, o kadar.
cgroup v1’de PSI çalışır mı?
Kısmen çalışıyor. Node seviyesinde PSI okuyabilirsin, ama container ve pod level metrikler için cgroup v2 şart. Neyse ki yeni cluster’lar zaten v2’ye geçmiş durumda, hani modern bir setup’ta bu pek sorun ölmüyor.
PSI ile cAdvisor metrikleri arasındaki fark ne?
Hani, Şöyle açıklayayım: cAdvisor utilization gösteriyor — mesela “ne kadar kullanıldı”. PSI işe saturation gösteriyor — yanı “ne kadar beklendi”. Birbirinin alternatifi değiller, tamamlayıcılar aslında. Bence ikisini birlikte kullanmak gerekiyor, tek başına yeterli değil.
HPA’da PSI metriklerini kullanmak production-ready mi?
Teknik olarak evet. Ama açıkçası dikkatli olmakta fayda var — custom metrics adapter üzerinden çalışıyor, yanı sisteme ekstra bir component eklemiş oluyorsun. Tecrübeme göre staging’de iyice test etmeden direkt production’a çıkarmamak lazım.
AKS, EKS veya GKE’de varsayılan olarak açık mı?
v1.36’yı destekleyen versiyonlarda KubeletPSI feature gate’i varsayılan GA olduğu için aktif geliyor. Ama kernel PSI tarafı bulut sağlayıcısına göre değişiyor — yanı varsaymamak lazım. /proc/pressure/cpu dosyasının orada olup olmadığını kontrol etmek en güvenlisi.
Kaynaklar ve İleri Okuma
Kubernetes v1.36: PSI Metrics for Kubernetes Graduates to GA — Resmî Blog
Linux Kernel PSI Resmî Dokümantasyonu
Araya gireyim: Kubernetes Node Pressure Eviction Docs
KEP-4205: PSI Metric Enhancement Proposal

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



