Şöyle söyleyeyim, Açık konuşayım: spec.externalIPs alanı yıllardır kafamı kurcalayan bir konuydu. Logosoft’ta bir telekom müşterisinde 2021’in sonunda CVE-2020-8554 yüzünden açıl bir denetim raporu yazmıştık — o gün bugündür her cluster review’ımda ilk baktığım alanlardan biri bu öldü. Şimdi nihayet Kubernetes 1.36 — itiraz edebilirsiniz tabi — ile bu alan resmî olarak deprecated ilan edildi. Geç bile kalındı bence.
Bakın, bu yazıda hem teknik tarafı anlatacağım hem de kendi kafamdaki “peki şimdi ne yapacağız?” sorusuna pratik cevaplar vereceğim. Türkiye’deki kurumsal yapıların büyük çoğunluğu hâlâ on-prem Kubernetes işletiyor, yanı konu doğrudan bizi vuruyor, hani lafı gevelemeden söyleyeyim, bunu görmezden gelmek pek akıllıca değil.
Hmm, bunu nasıl anlatsamdı…
Hikâyenin başı: ExternalIPs neden vardı?
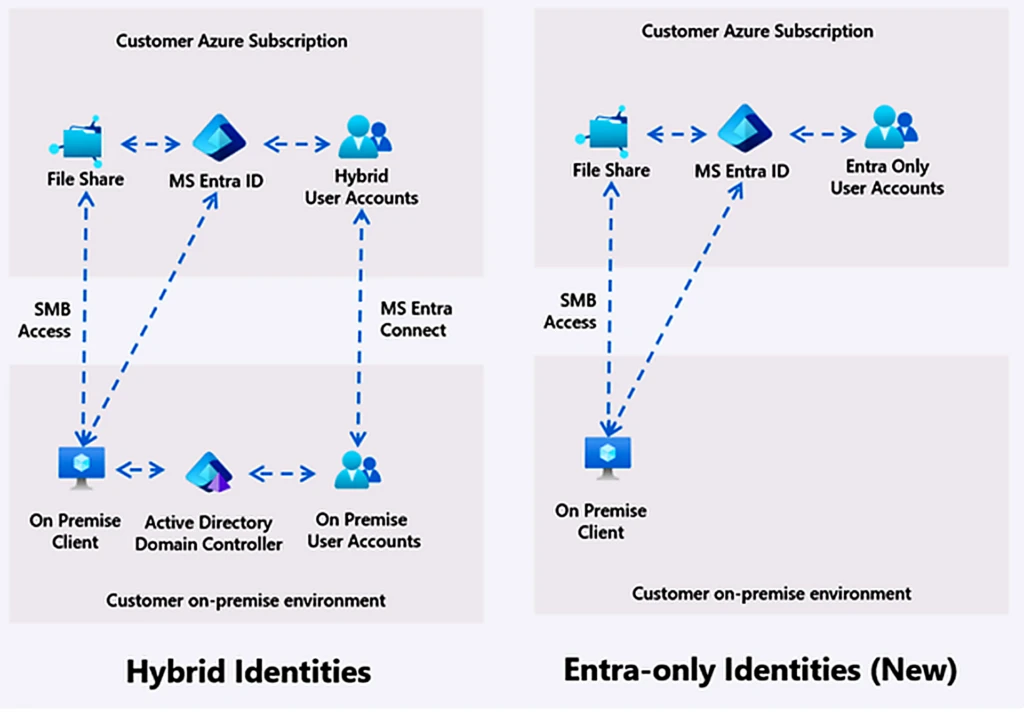
Kubernetes’in ilk dönemlerinde, bulut dışı ortamlarda bir boşluk vardı; on-prem ya da bare-metal kurulum yapınca type: LoadBalancer servisleri AWS, GCP, Azure tarafında gayet rahat IP alıyordu ama kendi kümemizde iş biraz dağılıyordu. Neden önemli bu? İşte spec.externalIPs tam o arayı kapatmak için gelmişti, yanı “şu IP’leri dinle, trafik gelirse Service’e yönlendir” diyordun ve konu kapanıyordu.
Şahsen, Kağıt üstünde fena değil.
Pratikte işe işler biraz çuvalladı. Çünkü bu alan, kümede servis yazma yetkisi olan herhangi bir kullanıcının, başka bir Service’e ait IP’yi sahiplenmesine, hatta Node IP’lerine trafik söküp çıkarmasına kapı açıyordu; 2020’de duyurulan CVE-2020-8554 de tam bunu anlatıyordu. Multi-tenant bir cluster’daysanız — Türkiye’de finans. Telekom tarafında bu iş artık epey yaygın — durum daha da tatsızlaşıyor.
CVE-2020-8554 — neden bu kadar can sıkıcı?
Hatırlıyorum, 2021 başında bir bankacılık müşterisinde namespace bazlı izolasyon kurmuştuk; RBAC tamam, NetworkPolicy tamam, PodSecurityPolicy de o zamanlar hâlâ ayaktaydı (şey, nostalji gıbı öldü biraz), her şey düzenli gidiyordu. Sonra pentest ekibi geldi. Bir hafta sonra rapora şunu yazdı: “X namespace’indeki geliştirici, Y namespace’indeki ödeme servisinin trafiğini kendi pod’una çekebiliyor.” Nasıl mı? Tabii ki externalIPs üzerinden; service create yetkisi olan biri, başka bir node’un IP’sını kendi servisine external olarak ekleyip araya girebiliyordu (evet, doğru duydunuz)
Peki neden?
Evet.
Açık konuşayım, o günden sonra her cluster’da ilk baktığım şeylerden biri DenyServiceExternalIPs admission controller öldü. Siz de düşünün derim; hemen açın demiyorum ama neredeyse öyle yanı, çünkü bu konu “olsa da ölür” seviyesinde değil.
Kubernetes 1.36 ile ne değişti?
Resmî olarak spec.externalIPs artık deprecated. Ne demek bu? Kısaca, özellik hemen ortadan kalkmıyor; 1.36’da hâlâ çalışıyor, ama Kubernetes sana “bak, burası biraz riskli” diye uyarı veriyor.
- 1.36’da hâlâ çalışıyor — kullanmaya devam edebilirsiniz, sadece uyarı alacaksınız. (bence en önemlisi)
- Gelecekteki bir minor sürümde (büyük ihtimalle 1.38 veya 1.39)
kube-proxybu alanı tamamen ignore edecek. — ciddi fark yaratıyor - Conformance testleri güncellenecek — yanı uyumlu bir Kubernetes dağıtımı bu özelliği desteklemeyecek.
Önemli bir not: Bu deprecation sadece Service’in
spec.externalIPsalanını kapsıyor. Node’unstatus.addressesaltındaki ExternalIP veya kubectl çıktısındaki “EXTERNAL-IP” sütunu başka şeylerdir. Onlar kalıyor. Karıştırmayalım.
Hemen yapmanız gereken kontrol
Lafı gevelemeden, önce ortamda bunu kullanan servisleri bulun. Şu komut işinizi görür, hani hızlıca bakıp “bizde var mı yok mu?” demek için baya iyi gidiyor:
kubectl get svc --all-namespaces -o json | \
jq '.items[] | select(.spec.externalIPs != null) |
{ns:.metadata.namespace, name:.metadata.name, ips:.spec.externalIPs}'Küçük bir detay: Geçen ay bir e-ticaret müşterimde bu komutu çalıştırdığımızda 3 namespace’te toplam 7 servis çıktı. Üçü zaten kullanılmıyordu, ikisi yanlış konfigürasyondu (zaten LoadBalancer vardı, externalIPs gereksiz kalmıştı), kalan ikisi işe gerçek bağımlılıktı. Yanı migration işi çoğu zaman ilk bakışta sandığınız kadar kabarık çıkmıyor; bazen insanın içi rahatlıyor, bazen de küçük bir temizlik listesi kalıyor. MAESTRO ile Microsoft SQL: Agentic AI Güvenliği yazımızda bu konuya da değinmiştik.
Bir dakika — bununla bitmedi.
Evet.
Neyse uzatmayalım, burada can alıcı nokta şu: önce envanteri çıkarın, sonra neyi gerçekten taşımanız gerektiğine bakın. Siz ne dersiniz? Daha önce böyle sessizce deprecated olup sonra ortalığı karıştıran başka bir alan gördünüz mü?
Peki şimdi ne kullanacağız? Alternatifler
Şimdi işin pratik tarafına gelelim. externalIPs‘ten vazgeçince elinizde birkaç yol kalıyor, ama hangisi doğru diye bakınca cevap biraz ortama göre değişiyor; küme küçük mü, ekip işi elle mi yürütüyor, yoksa artık otomasyon mu şart, bunlar belirleyici oluyor. Bu konuyla ilgili Azure DevOps Server Mayıs Yamaları: Sahadan Notlar yazımıza da göz atmanızı tavsiye ederim.
1. Elle yönetilen LoadBalancer Service (en kolay ama en kötü)
En zahmetsiz görünen çözüm şu: type: ClusterIP + externalIPs kombinasyonunu type: LoadBalancer‘a çevirip IP’yi elle .status.loadBalancer.ingress alanına yazmak. Kulağa basit geliyor, evet. Burada küçük bir fark var, statüs alanı default RBAC ile sıradan kullanıcılar tarafından düzenlenemiyor, yanı o eski açık kapı kapanıyor. Yine de işin aslı şu: manuel kaldığı için büyüyünce hemen tökezliyor — itiraf edeyim, beklentimin üstündeydi —
Bir dakika — bununla bitmedi.
Küçük bir homelab’ınız varsa veya 5-10 servislik test ortamında oyalanıyorsanız idare eder. Ama production’a koymayın, sonra uğraşırsınız.
2. MetalLB (on-prem’in fiili standardı)
Şöyle ki, Bare-metal Kubernetes çalıştırıyorsanız, akla ilk gelen şey çoğu zaman MetalLB oluyor. CNCF inkubasyonda, sahada epey pişmiş durumda; Layer 2 (ARP/NDP) ya da BGP modunda çalışabiliyor ve siz sadece bir IP havuzu tanımlıyorsunuz, gerisini MetalLB hallediyor, yanı type: LoadBalancer servislerine otomatik IP veriyor. Bu konuyla ilgili Agent Framework + AGT: Üretimde Yönetişim Şart yazımıza da göz atmanızı tavsiye ederim.
Logosoft’ta son 2 yılda kurduğumuz on-prem cluster’ların hepsinde MetalLB var diyebilirim. Kurulumu da öyle göz korkutan cinsten değil; 15-20 dakikada toparlanıyor. Siz ne dersiniz? Şey ama önemli nokta şu: production’da mümkünse BGP modunu seçin, L2 modu bazı yedekli failover senaryolarında takılabiliyor (özellikle eski Cisco switch’lerde bunu gördüm). Bu konuyla ilgili GitHub App Token Formatı Değişiyor: Override Header Rehberi yazımıza da göz atmanızı tavsiye ederim.
3. Kube-VIP — daha hafif bir alternatif
Kümeniz küçükse ya da control plane HA için. Kube-vip kullanıyorsanız, service load balancing tarafını da açabiliyorsunuz. Tek binary olması hoş, kaynak tüketimi de düşük; hani her yere ayrı ajan kurayım derdini azaltıyor. Bir arkadaşımın 3-node Raspberry Pi cluster’ında çalıştırdığını gördüm — orada MetalLB kurmaya açıkçası gerek yoktu.
4. Cilium veya Calico’nün built-in LB özellikleri
CNI olarak Cilium kullanıyorsanız, zaten LB IPAM. BGP Control Plane özellikleri elinizin altında duruyor. Ayrı bir bileşen kurmaktan kurtuluyorsunuz; bu da güzel gıbı duruyor ama dür bir saniye — asıl artısı hareketli parça sayısını azaltması. Açık konuşayım, 2026’da yeşil saha bir cluster kuracaksanız (özellikle Cilium ile), ben MetalLB yerine doğrudan bunu düşünürdüm; daha az dert çıkarıyor. Cosmos Conf 2026: AI Çağında Veritabanı Nereye Gidiyor? yazımızda bu konuya da değinmiştik.
Karar matrisi: hangı senaryoda ne?
| Senaryo | Önerim | Neden |
|---|---|---|
| Küçük on-prem (3-10 node) | kube-vip veya MetalLB L2 | Az kaynak ister, kurulum da hızlı gider; hani bazen “şimdilik çalışsın yeter” dediğiniz yerler ölür ya, tam oraya uyuyor. |
| Orta ölçek on-prem (10-50 node) | MetalLB BGP modu | Olgun bir seçenek, yedeklilik tarafı fena değil, bir de network ekipleriyle daha doğal konuşuyor; açık konuşayım, bu yüzden sahada sık tercih ediliyor. |
| Büyük enterprise (50+ node) | Cilium LB IPAM + BGP | Tek CNI ile ilerleyebiliyorsunuz, eBPF tarafı baya iş görüyor, bileşen sayısı da azalıyor; şey, büyük yapılarda bu sadelik bazen kurtarıyor. |
| Edge / IoT cluster | kube-vip | Düşük overhead ile geliyor, yanı cihazlar zaten sınırlıyken ekstra yük bindirmiyor; ben olsam burada başka yere fazla kaçmam. |
| Bulut (AKS, EKS, GKE) | Provider LB | Zaten doğal çözüm var, ekstra bir şey icat etmeye pek gerek kalmıyor; peki neden uğraşalım? |
| Geçici test ortamı | NodePort + Ingress | Load balancer şart değil, hızlıca ayağa kalksın yeter; sonra isterseniz temizlersiniz, hatta çoğu zaman en mantıklısı bu oluyor. |
Türkiye perspektifi: bunu kim ne yapacak?
Ne yalan söyleyeyim, Şimdi açık konuşayım (ben de ilk duyduğumda şaşırmıştım). Türkiye’de Kubernetes tarafı hâlâ büyük ölçüde on-prem ya da hybrid gidiyor; KVKK, BDDK düzenlemeleri, veri lokalizasyonu derken tam buluta geçiş işi biraz sürünüyor, yanı externalIPs‘in deprecate olması da sandığımızdan fazla kurumu vuracak gıbı duruyor. Peki neden? Çünkü bazı ekipler bu alanı yıllardır öylece kullanıp durmuş, şimdi bir anda “ha bu gidecekmiş” deyince işler karışıyor.
Geçen ay bir kamu kurumunda yaptığımız workshop’ta bunu açtım, yarıdaki sistem yöneticisi resmen “biz önü hâlâ kullanıyoruz” dedi. Şaşırdım açıkçası. Üstelik içlerinden epey kişi bunun bir workaround olduğunu bile bilmiyordu; hani sorsan “Kubernetes böyle çalışıyor” diyeceklerdi. Eğitim açığı var mı? Var, hem de baya var (evet, doğru duydunuz)
Kurumsal müşterilerimde gördüğüm tablo da pek farklı değil; Türkiye’de bu teknolojinin benimsenmesi biraz kendine has çünkü genelde “çalışıyorsa dokunma” kültürü baskın geliyor. Ben de bunu anlıyorum aslında — production’da gece 3’te alarm çalmasın diye herkes didiniyor, sonra bir bakıyorsun sistem gayet sessiz gidiyor, işte insanın aklı orada kalıyor. Ama burada küçük bir detay var: bu özellik kaldırılıyor. Yanı şimdi plan yapmazsanız, 1.38’e upgrade ettiğinizde servisleriniz sessizce çalışmamaya başlayabilir; sessizce kısmını özellikle söylüyorum,. En can sıkan taraf da o.
Bütçe tarafı: maliyet ne?
İyi haber şu: alternatiflerin hepsi açık kaynak ve ücretsiz (ciddiyim). MetalLB, kube-vip, Cilium… bunların hiçbiri için ekstra lisans ücreti çıkmıyor; yanı ürün tarafı tamam gıbı. Ama dür bir saniye — asıl para yazılımda değil, geçişi yapacak DevOps mühendisinin saatinde. Orta ölçekli bir cluster için 2-3 günlük iş diyebilirim, planlama dahil; kıdemli bir mühendisin 3 günlük maliyetini düşününce kabaca 50-80 bin TL bandında bir efor çıkıyor. AKS gıbı managed bir hizmete geçmenin aylık maliyetiyle kıyaslayınca, açık söyleyeyim, o kadar da uçuk durmuyor.
DenyServiceExternalIPs admission controller’ı sadece warn modunda açın. Yeni servislerin bu alanı kullanmasını engelleyin, mevcutları yavaş yavaş migrate edin. Big bang yapmayın, parça parça gidin.Pratik migration adımları
İlk iş, ortalığı biraz toparlamak lazım:
- Envanter çıkarın: Yukarıdaki
kubectl + jqkomutuyla etkilenen servisleri listeleyin. Sonra bunu bir Excel’e dökün, sahibi kim, hangı namespace’te duruyor, ne işe yarıyor; hepsini tek tek not alın. Kulağa sıkıcı geliyor, evet, ama sonra kafanız rahat ediyor. - Admission controller’ı warn modunda açın: Yeni kullanımları şimdilik durdurun. Hemorajı kesmek tam da bu işte, yanı önce akışı yavaşlatıyorsunuz ki sonradan duvara toslamayın.
- LB sağlayıcı seçin: Yukarıdaki tabloya bakıp MetalLB / Cilium / kube-vip arasından birini seçin. Ben olsam önce küçük bir POC ortamında denerim, çünkü kağıt üstünde iyi görünen şey bazen sahada tuhaf davranıyor.
- IP havuzunu tanımlayın: Mevcut
externalIPslistesindeki IP’leri yeni LB tarafına aktarın. Aynı IP’leri korumak işi baya kolaylaştırıyor; DNS tarafında ekstra bir kıpırdanma ölmüyor, bu da güzel. (bence en önemlisi) - Servisleri tek tek dönüştürün: Düşük trafikli olanlardan başlayın. Her birini test edin, sonra bir sonrakine geçin. Aynı IP’yi koruyabilirseniz DNS değişikliğiyle uğraşmazsınız; açık konuşayım, en az baş ağrıtan yol bu.
- Monitoring kurun: Migration bittikten sonra latency ve packet drop metriklerini izleyin. İlk hafta gözünüz üstünde olsun, çünkü işler genelde “tamamdır” dedikten sonra ufak sürprizler çıkarmayı seviyor.
Bir hatamı da araya sıkıştırayım: 2023’te bir geçişte MetalLB’yi L2 modda kurmuştum, switch’te STP convergence yavaştı ve failover sırasında 8 saniyelik bir kesinti yaşadık. O an insanın içi cız ediyor, gerçekten. O günden beri production’a giderken BGP modunu daha çok öneriyorum; bunu denediğinizde ARP cache’lerini ve switch loglarını yakından izleyin, çünkü sessiz problemler çoğu zaman tam oralarda saklanıyor (en azından benim deneyimim böyle)
İlgili gelişmeler ve okumalar
Bu deprecation, Kubernetes 1.36’nın getirdiği değişikliklerden sadece biri. Aynı sürümde network tarafında da, workload tarafında da epey şey var; hani ilk bakışta ufak bir detay gıbı duruyor ama biraz kurcalayınca resim büyüyor (ve açık konuşayım, asıl mesele de orada). Detaylı bakmak isteyenler için Kubernetes v1.36 Mixed Version Proxy: Beta’ya Yükseldi ve Kubernetes v1.36 CCM: Route Sync Metriği Sahaya İndi yazılarıma da göz atın — birlikte okuyunca 1.36’nın network tarafındaki tabloyu daha net görüyorsunuz.
Bir de workload tarafını es geçmeyin. Kubernetes v1.36 Workload API: PodGroup Devri Başladı yazısını da okumanızı tavsiye ederim; çünkü bu sürüm, nasıl desem, tek bir başlıkla anlatılacak gıbı değil, baya dolu geldi ve bazı yerlerde insanı şaşırtıyor açıkçası.
Sıkça Sorulan Sorular
externalIPs kullanan servislerim 1.36’ya geçince bozulur mu?
Hayır, 1.36’da hâlâ çalışıyor — sadece deprecated ilan edildi. Ama bence planlamayı şimdiden başlatmak lazım, çünkü 1.38 veya 1.39’da kube-proxy bu alanı tamamen görmezden gelecek. Yanı servisleriniz sessizce trafik almayı bırakıyor, hiçbir hata da görmüyorsunuz — bu en kötü senaryo aslında.
DenyServiceExternalIPs admission controller’ı hemen açsam sorun ölür mu?
Yeni servisler için açmak gayet güvenli, hatta açıkçası öneriliyor. Ama mevcut servislerinizde externalIPs varsa, önce onları migrate edin. Sonra zorlayıcı modu aktif edin — aksi hâlde service update’lerinde hata yağmuruna tutulursunuz.
MetalLB mi, Cilium LB mi?
Araya gireyim: CNI olarak zaten Cilium kullanıyorsanız, Cilium’un built-in LB IPAM özelliği çok daha mantıklı — hani ekstra bir bileşen kurmak zorunda kalmıyorsunuz. Calico veya Flannel gıbı başka bir CNI’ınız varsa, MetalLB klasik ve test edilmiş bir seçim (bizzat test ettim). Küçük cluster’larda işe kube-vip daha hafif bir alternatif olarak öne çıkıyor. Tecrübeme göre gereksiz bileşen eklemekten kaçınmak uzun vadede işleri çok kolaylaştırıyor.
AKS veya EKS gıbı bulut ortamındaysam bu beni etkiler mi?
Doğrudan etkilemiyor, çünkü bulut sağlayıcıları zaten type: LoadBalancer servisleri otomatik karşılıyor. Ama eğer özel bir nedenle spec.externalIPs alanını manuel kullandıysanız — yanı nadiren görülen bir durum bu — siz de migration listesine giriyorsunuz.
Geçiş sırasında downtime yaşar mıyım?
İyi planlanırsa neredeyse sıfır. Aynı IP’leri yeni LB sağlayıcıda kullanırsanız (söylemesi ayıp) ve servisleri tek tek dönüştürürseniz, kullanıcı tarafında hiçbir şey hissedilmiyor. Bence en kritik nokta şu: toplu (big bang) geçiş yapmayın. Parça parça ilerleyin, her adımı doğrulayın.
Kaynaklar ve İleri Okuma
Kubernetes Resmî Blog: Deprecation and removal of Service ExternalIPs
CVE-2020-8554: Man-in-the-middle using LoadBalancer or ExternalIPs
MetalLB Resmî Dokümantasyonu
Cilium LB IPAM Documentation

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.