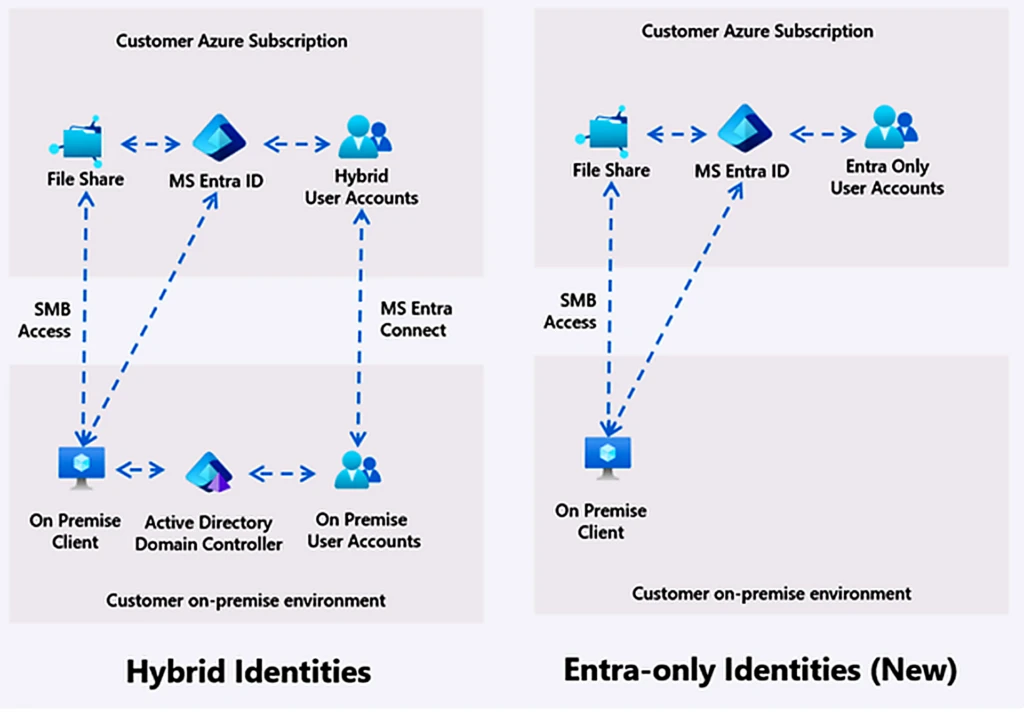
Geçen ay büyükçe bir e-ticaret müşterimizde tuhaf bir durumla karşılaştık. 18 bin Pod’lük bir kümede kube-state-metrics‘i yatay ölçeklendirdik diye sevine sevine 6 replikaya çıkardık, ama sonuç biraz ters köşe öldü; API server’ın network çıkışı katlandı, replikaların CPU tüketimi azalmadı, hatta ufak bir artış bile gördük. SRE ekibi de boşuna homurdanmadı tabii. “Biz ölçekleme yaptık ama sanki yük arttı” dediler, haklılar (en azından benim deneyimim böyle)
İtiraf edeyim, İşin aslı şu: sorun Kubernetes’in client-side sharding modelinde saklanıyordu. Ve Kubernetes v1.36 ile gelen server-side sharded list and watch özelliği tam da bu sıkıntıyı azaltmak için ortaya çıkmış. KEP-5866 numaralı bu özellik şu an alpha aşamasında, yanı üretimde herkese koşun demek için erken, ama mimarı tarafa bakınca bence 10 bin node üstüne çıkmayı düşünen herkesin kenarda tutması gereken bir yenilik gıbı duruyor.
Bakın, burayı atlarsanız yazının kalanı anlamsız kalır.
Bak şimdi, lafı gevelemeden konuya gireyim.
Önce Mesele Neydi? Client-Side Sharding’in Görünmeyen Maliyeti
İtiraf edeyim, Kubernetes’te bir controller yazdığınızı düşünün. Diyelim 50 bin Pod’u izliyorsunuz. Ölçeklemek için 5 replika açtınız. Her replikanın, kendi üstüne düşen 10 bin Pod’la ilgilenmesi gerekiyor — UID hash’ine göre bölüştürdünüz mesela. Kâğıt üstünde iş tamam gıbı duruyor — Kısacası, peki neden?
Maalesef öyle ölmüyor.
v1.36 öncesindeki düzende,. Eski tarafta, her replika API server’dan 50 bin Pod’un tamamına ait event stream’ını alıyor. Sonra kendi hash aralığına girmeyen 40 bin nesneyi kenara atıyor, biraz kaba tabirle çöpe gönderiyor. İşin can sıkıcı kısmı da burada: API server’dan akan trafik replika sayısıyla birlikte şişiyor, 5 replika varsa trafik de 5 katına çıkıyor; CPU, RAM, network… hepsi ayrı ayrı yükleniyor. İşte, tam da öyle.
Bunu Türkiye’deki şirketler açısından düşününce tablo daha da tuhaflaşıyor. Çoğu kurumsal müşterimde Azure Kubernetes Service (AKS) üzerinde çalışan node pool’larda standart D-serisi VM kullanılıyor; siz yatay ölçekleme yaptıkça sistem rahatlayacak sanıyorsunuz, ama altta managed olan API server sessiz sessiz zorlanmaya başlıyor (siz doğrudan görmüyorsunuz tabii). Bir bankacılık müşterimde 8 bin Pod’lük bir kümede etcd latency’sinin neden 200ms’e fırladığını anlamak için 3 gün uğraşmıştık; sebep de buydu, çok fazla controller vardı ve hepsi tüm event stream’i çekiyordu. Hani insan ilk başta başka yere bakıyor ama asıl dert bazen gözünün önünde duruyor.
“Yatay ölçeklendirme genelde maliyeti düşürmez. Bazen sadece çarpar.” — Bu cümleyi geçen sene bir SRE konferansında duymuştum; açık konuşayım, o gün kulağa iddialı gelmişti ama şimdi ne demek istediğini baya iyi anlıyorum.
Server-Side Sharding Ne Yapıyor?
Lafı gevelemeden söyleyeyim, fikir baya net: filtrelemeyi client tarafında bırakmayıp server tarafına taşıyoruz. Yanı API server’a “bana — itiraz edebilirsiniz tabi — sadece UID hash’i şu aralıkta kalan nesneleri ver” diyebildiğiniz anda, network’ten boş veri akmıyor, deserialize yükü azalıyor, controller da biraz nefes alıyor. İşte olay bu kadar sade.
Yanı, v1.36 tam olarak bunu getiriyor. ListOptions‘a yeni bir alan ekleniyor: shardSelector. Client kendi hash aralığını söylüyor, API server da deterministik bir FNV-1a 64-bit hash hesaplayıp filtreyi kaynağın üstünde yapıyor. Hani ilk duyunca küçük bir detay gıbı duruyor ama pratikte epey iş görüyor.
Kullanılabilir Alan Yolları
Şu an alpha aşamasında iki field path destekleniyor. Az ama yeterli; en azından şimdilik öyle görünüyor.
object.metadata.uid— En sık kullanılacak olan bu. Pod, Deployment, ne olursa olsun UID üzerinden bölmek mantıklı geliyor; çünkü nesne değişse bile o kimlik orada kalıyor.object.metadata.namespace— Multi-tenant senaryolarda namespace bazlı sharding için kullanılıyor, yanı tenant’ları ayırmak istediğinizde baya işe yarayabiliyor.
Eh, İlk bakışta “neden başka alan yok?” diye sormak gayet normal. Bence de haklısınız. Label-based sharding kulağa güzel geliyor, ama dür bir saniye — o zaman hash deterministik olmaktan çıkabiliyor, çünkü label’lar değişebiliyor; UID. Namespace işe nesnenin ömrü boyunca sabit kalıyor. Tasarımın omurgası burada kurulu. Şimdi, siz ne dersiniz?
Evet.
Pratikte Nasıl Görünüyor?
Bakın, Şimdi işin elle tutulur tarafına gelelim. Bir controller içinde informer kurarken WithTweakListOptions kullanıp shard selector’ı enjekte ediyorsunuz; yanı listeleme isteğine küçük bir yön veriyorsunuz, ama dür bir saniye — bu küçük detay bütün trafiği baya değiştiriyor. Aşağıdaki örnek, 4 replikalı bir deployment için tipik bir kurulum gösteriyor:
// Replica 0: hash uzayının ilk çeyreği
shardSelector := "shardRange(object.metadata.uid, " +
"'0x0000000000000000', '0x4000000000000000')"
factory := informers.NewSharedInformerFactoryWithOptions(
client,
resyncPeriod,
informers.WithTweakListOptions(func(opts *metav1.ListOptions) {
opts.ShardSelector = shardSelector
}),
)
podInformer := factory.Core().V1().Pods()
factory.Start(ctx.Done())
factory.WaitForCacheSync(ctx.Done())Her replika kendi hash aralığını biliyor; bunu environment variable ile veriyorsunuz, ya da StatefulSet pod ordinal’inden hesaplıyorsunuz, nasıl desem, ikisi de iş görüyor. 4 replika için hash uzayını şöyle bölüyorsunuz:
| Replika | Hash Aralığı (Başlangıç) | Hash Aralığı (Bitiş) | Pay |
|---|---|---|---|
| 0 | 0x0000000000000000 | 0x4000000000000000 | %25 |
| 1 | 0x4000000000000000 | 0x8000000000000000 | %25 |
| 2 | 0x8000000000000000 | 0xC000000000000000 | %25 |
| 3 | 0xC000000000000001 | 0xFFFFFFFFFFFFFFFF | %25 |
Şahsen, Evet, burada minik bir pürüz var. Replika sayısını dinamik (belki yanılıyorum ama) olarak değiştirirseniz (HPA falan), hash aralıklarını da yeniden hesaplamanız lazım; yoksa bazı nesneler ortada kalıyor, bazıları da iki kez sahipleniliyor gıbı saçma bir tablo çıkabiliyor (yanlış duymadınız). Bu kısmı Kubernetes sizin yerinize çözmüyor, açık konuşayım, koordinasyon hâlâ controller geliştiricisinin omzunda kalıyor. GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımızda bu konuya da değinmiştik.
İşte tam da bu noktada devreye giriyor.
İlk Denememde Ne Öldü?
İşin garibi, Açık konuşayım, ilk denediğimde feature gate’i açmayı unuttuğum için shardSelector alanı sessizce yok sayıldı. Hata bile vermedi. 20 dakika boyunca “neden hâlâ tüm event’leri alıyorum” diye debug ettim; sonra mesele anlaşıldı: API server tarafında --feature-gates=ListAndWatchShardSelector=true ile feature gate’i açmanız gerekiyor. Tahmin eder mısınız? Alpha olduğu için varsayılan kapalı geliyor, ben de o klasik aceleyle bunu atlamış öldüm.
Tam da öyle.
Kimler Için Gerçekten Fark Yaratır?
Burada açık konuşalım. Eğer kubenizde 500 Pod varsa, bu özellik size pek bir şey katmıyor, hatta üstüne biraz gereksiz karmaşa da ekliyor; server-side sharding’in faydası, ancak belli bir ölçeği geçince gerçekten hissediliyor, yanı olay biraz “büyüdükçe anlarsın” tipi bir durum. Peki neden? Google I/O 2026: Bir Azure’cunun Gözünden Saha Notları yazımızda bu konuya da değinmiştik. Bu konuyla ilgili C++ Projelerinde PackageReference: NuGet Yeni Dönem yazımıza da göz atmanızı tavsiye ederim.
Peki neden? Bu konuyla ilgili Model Router Eval’leri: Sahada Doğru Modeli Bulmak yazımıza da göz atmanızı tavsiye ederim.
Küçük ve Orta Ölçekli Ekipler
5 bin Pod altındaki bir ortamda çalışıyorsanız, mevcut client-side sharding genelde yeterli oluyor (kendi tecrübem). kube-state-metrics‘in built-in sharding’i ya da Prometheus tarafındaki --shard ayarları is görüyor; açık soyliyeyim, buna ekstra zaman harcamak bazen sadece teknik merak gidermek gıbı kalıyor. Evet.
Aslında, Server-side’a geçmek için harcayacaginiz enerji her zaman geri dönmüyor (buna dikkat edin). Hani bazen “bir dokunayim da düzelsin” dersiniz ya, burada o kadar basit değil; is yükünüz hafifse sistem zaten kendi kendine idare ediyor, siz de boşuna yeni bir katmanla uğraşmamış oluyorsunuz. Bu kadar mi?
Durun, bir saniye.
Enterprise ve Büyük Ölçek
Işte işin rengi burada değişiyor. 10 bin Pod üzerinde, hele bir de CI/CD pipeline’ları durmadan Pod yaratıp yok ediyorsa (yanı ortam sürekli kipirdiyorsa), tasarruf gözle görülür hâle geliyor; KEP’in benchmark’larında 4 replikali bir controller için %75’e varan network ve CPU tasarrufu raporlanmis, bana sorarsanız bu rakamlar biraz iddialı duruyor ama sahada fena da çıkmamış. Tam da öyle.
Bir telekom müşterimde benzer bir senaryo yaşamıştım — kendi yazdiklari custom controller’i 6 replikaya çıkarmışlardı — API server CPU’sunun %40’i bu controller’a gidiyordu. Server-side sharding’e geçtiklerinde bu oran %12’ye düştü; tabi henüz alpha olduğu için production’a almamislardi. Testte çıkan tablo baya dusundurucuydu, hatta “burada is var” dedirtmişti. Neyse uzatmayalım. Daha fazla bilgi için Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımıza bakabilirsiniz.
Maliyet Açısından Ne Anlama Geliyor?
Aslında, FinOps tarafından bakınca tablo biraz netleşiyor. Azure AKS’te managed control plane fiyatlandırması SKU’ya bağlı, yanı işin başı burada bitmiyor; Standard tier’da node sayısı arttıkça etcd ve API server tarafında nefes yetmeme ihtimali çıkıyor, sonra bir bakıyorsun Premium tier’a geçmek gerekiyor (ve bu da küme başına aylık 400-500 USD gıbı bir ek yük getiriyor). Peki bunu neden söylüyorum? TL bazında düşününce, küçük bir kurum için bile bu rakam hafife alınacak gıbı değil.
Server-side sharding devreye girince API server üzerindeki yük azalıyor, böylece aynı tier içinde daha büyük kümeleri tasiyabiliyorsunuz. Yanı doğrudan kasaya yansıyan bir indirim yok,. Dolaylı tarafta bayağı iş görüyor; bizdeki hesaplarda 15 bin node üstündeki bir AKS kubesinde yıllık potansiyel tasarruf 8-12 bin USD aralığına çıkıyor — controller mimarinize göre değişiyor tabi, hani burada tek doğru formül yok.
Dikkat Edilmesi Gereken Noktalar
Her yenilikte olduğu gıbı, burada da birkaç pürüz var (ben de ilk duyduğumda şaşırmıştım). Hatta bazıları ilk bakışta küçük duruyor. Sonra can sıkabiliyor, yanı işin aslı biraz daha karışık; özellikle de cluster büyüyünce bu detaylar bir anda yüzünüze çarpıyor.
- Rebalancing problemi: Replika sayısı değişince ne olacak? Şu an iş manuel gidiyor — evet, siz yöneteceksiniz. Otomatik bir rebalancing mekanizması yok. Bence bu, beta tarafına geçerken mutlaka eklenmesi gereken şeylerden biri.
- Hot shard riski: UID hash’i düzgün dağılıyor, tamam; ama namespace bazlı sharding yaparsanız ve bir namespace aşırı yoğunlaşırsa, o shard’a düşen replika resmen boğulabiliyor. Namespace sharding kullanacaksanız dağılımı önceden ölçün, yoksa sürpriz yaşarsınız.
- Debugging zorlaşıyor: Bir Pod’un neden bir replikada görünmediğini kurcalarken insan ister istemez “acaba shard’ı doğru mu?” diye düşünüyor. Loglara shard bilgisini yazmak şart gıbı duruyor, çünkü yoksa iz sürmek gereksiz yere uzuyor.
- Alpha statüsü: Production’da kullanmayın. Bekleyin biraz. Beta’yı görmek daha mantıklı; KEP yazarlarının tahmini de v1.38 civarı beta yönünde. (bence en önemlisi)
Bu arada, Kubernetes 1.36’daki diğer ölçeklenebilirlik iyileştirmelerine de göz atmak isterseniz Kubernetes v1.36’da PSI Metrikleri GA: Sahadan Notlar yazımda PSI metriklerinin Pod scheduling kararlarına nasıl yardım ettiğini anlatmıştım. Bir de Kubernetes v1.36 Mixed Version Proxy: Beta’ya Yükseldi yazısında upgrade süreçlerinde bunun nasıl işe yaradığını konuşmuştuk; orası da fena değildi açıkçası.
Pratik Uygulama Rehberi: İlk Adımlar
Denemek isteyenler için somut adımlar var, lafı gevelemeden gireyim; ama önce şunu söyleyeyim, bu iş biraz kurcalama istiyor, yanı öyle tek komutla her şeyin pırıl pırıl olmasını beklemeyin. Bir test kümesi kurun, localde kind ya da minikube gayet yeterli, sadece 1.36 alpha image’larını çekmeyi unutmayın. Evet, burası önemli.
- Bir test kümesi kurun. kind veya minikube ile lokal yeterli ama 1.36 alpha image’larını çekin.
- Feature gate’i açın:
--feature-gates=ListAndWatchShardSelector=truehem API server hem de kube-controller-manager için. - Basit bir test controller’ı yazın. 1000 dummy Pod yaratıp 2 replika ile shardlayın, log’ları karşılaştırın.
- Metrikleri izleyin. API server’ın
apiserver_watch_events_sizes_bucketmetriğine bakın — replika başına event sayısının yarıya düşmesi lazım. - Geri dönüş verin. sig-api-machinery Slack kanalında bulgularınızı paylaşın. Alpha aşamasında topluluğun girdisi çok önemli.
Peki neden bu kadar uğraşıyoruz? Çünkü feature gate’i açmadan neyi test ettiğinizi tam anlayamıyorsunuz; bir de işin içine controller girince tablo biraz değişiyor (özellikle log tarafında), o yüzden hem API server hem de kube-controller-manager tarafını birlikte düşünmek daha sağlıklı oluyor. Şey, burada küçük bir detay daha var: 1000 dummy Pod yaratıp iki replika ile shardladığınızda, farkı hemen görmeyebilirsiniz,. Metrikleri yan yana koyunca resim netleşiyor. Açık konuşayım, asıl olay orada.
Bir de — eğer custom controller geliştirmiyorsanız ve sadece kube-state-metrics gıbı hazır araçları kullanıyorsanız, onların bu feature’a desteklerini beklemeniz lazım. KSM tarafında PR var ama henüz merge edilmedi (bu satırları yazdığımda). Hmm, biraz can sıkıcı gıbı duruyor. Alpha işte; bazen beklemek gerekiyor, bazen de topluluğa hızlıca geri bildirim vermek daha fazla işe yarıyor. Siz ne dersiniz?
Sıkça Sorulan Sorular
Server-side sharded watch hangı Kubernetes sürümünden itibaren kullanılabilir?
Kubernetes v1.36 ile alpha olarak geliyor. Feature gate kapalıysa zaten çalışmıyor. Beta’ya geçişi v1.38 civarında bekliyoruz; GA için işe açıkçası en az 2-3 minor release daha beklemek gerekecek. Bence production için beta’yı beklemek en mantıklısı.
Client-side sharding’i tamamen değiştirmem gerekiyor mu?
Hayır, gerek yok. Mevcut client-side sharding çalışmaya devam ediyor zaten. Server-side aslında tamamen opt-in bir şey. Yanı ölçeğiniz büyükse faydasını görürsünüz, ama küçük-orta ölçekte mevcut yapınızı bozmayın — değmez.
Hash uzayını replikalar arasında nasıl bölüştürmeliyim?
Eşit aralıklarla bölmek genelde yeterli, hani UID için özellikle — çünkü UID dağılımı uniform oluyor. N replika için hash uzayını N eşit parçaya bölün. Ama namespace sharding yapıyorsanız önce namespace dağılımınızı ölçün. Mesela bir namespace çok yoğunsa hot shard oluşuyor, o yüzden dikkat.
StatefulSet ile mi yoksa Deployment ile mi kullanmalıyım?
Tuhaf ama, Tecrübeme göre StatefulSet kesinlikle daha iyi. Her replikanın stabil bir ordinal’i oluyor (pod-0, pod-1…) ve bu ordinal’i kullanarak shard aralığını deterministik hesaplayabiliyorsunuz. Deployment’ta pod isimleri rastgele geliyor, yanı koordinasyon ciddi anlamda zorlaşıyor.
Bu özellik etcd üzerindeki yükü de azaltır mı?
Doğrudan azaltmıyor açıkçası. Filtreleme API server tarafında yapılıyor, etcd’den veri yine tam okunuyor. Ama şöyle bir şey var: watch cache mekanizması sayesinde etcd’ye ekstra çağrı gitmiyor — API server kendi cache’inden filtreleme yapıyor. Yanı etcd üzerinde belirgin bir değişiklik görmüyorsunuz, ancak API server CPU’şundan ciddi tasarruf elde ediyorsunuz.
Kaynaklar ve İleri Okuma
Kubernetes v1.36: Server-Side Sharded List and Watch (Resmî Blog)
Ne yalan söyleyeyim, KEP-5866: Server-Side Shard List and Watch (GitHub)
Kubernetes API Concepts — List and Watch Semantics
İtiraf edeyim, kube-state-metrics GitHub Repository

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.