
Bir metne bakıp “bu neyin nesi?” diye sorduğunuz oldu mu? Benim başıma 2024 Şubat’ında, İstanbul’da bir editör toplantısında tam da bu geldi (şaşırtıcı ama gerçek). Elimizde sadece yemek tariflerinin başlıkları vardı; malzeme listesi yok, açıklama yok, fotoğraf yok… Sadece isimler. İşin garip tarafı şu: İnsan gözüyle bakınca bazı başlıklar hemen birbirine benziyor, ama makineye gelince tablo biraz dağılıyor (bizzat test ettim)
Bakın, Bu yazıda kısa metinlerden anlam çıkarma işini konuşacağız. Orijinal deneyimin omurgası, yani tarif başlıklarını kümelere ayırma fikri burada da var; fakat konuyu daha geniş bir yerden ele alacağım. Çünkü mesele sadece “hangi model daha iyi?” değil. Veri temizliği var, temsil biçimi var, hatta sonuçların günlük hayatta işe yarayıp yaramadığı bile var (bizzat test ettim). Kâğıt üstünde güzel görünen şeyler pratikte bazen çuvallıyor… açık konuşayım.
Durun, bir saniye.
Neden kısa metinler bu kadar inatçı?
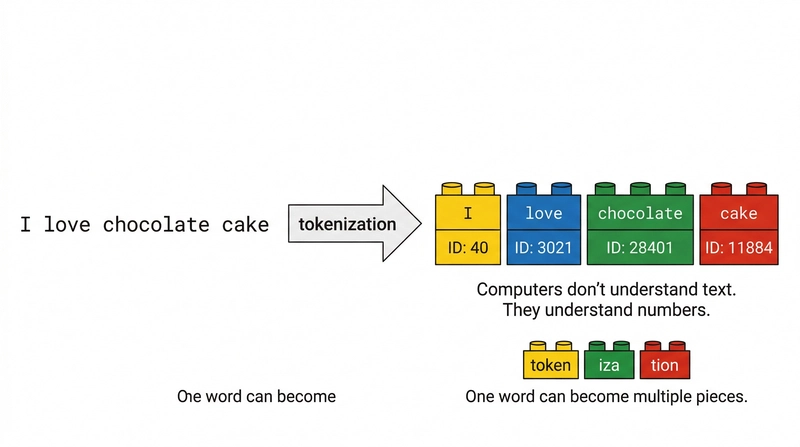
Kısa metin dediğiniz şey aslında bayağı huysuzdur. Üç kelime var. Biri markadır, biri sayıdır. Ve siz oradan anlam çıkarmaya çalışıyorsunuz — nasıl desem, biraz kör adam fili tarif ediyor gibi. Mesela “chicken cake” ile “cake chicken” arasındaki fark insan için komik gelebilir. Model için hiç de komik değil, hani bağlam az olunca her şey şişli oluyor işte.
Garip gelecek ama, Ben buna ilk kez 2023 sonbaharında Ankara’daki küçük bir ürün ekibinde takıldım — destek taleplerinin konu başlıklarını sınıflandırıyorduk. Bazı başlıklar o kadar kısaydı ki model resmen tahmin oyunu oynuyordu, “login issue” ya da “password reset” gibi etiketler tamam da “help”, “urgent”, “pls” gibi parçalar gelince ortalık karışıyordu, sistem bir şeylere benzetti bunları ama neye benzettiyse pek sorgulanmıyordu. Sorun yalnızca veri miktarı değil. Verinin karakteri.
Tarif adları da aynı dertten muzdarip: çok kısa olabilirler, yazım hatası taşıyabilirler, gereksiz sayılar içerebilirler ya da büyük ölçüde özgün görünse de aslında aynı kategoriyi işaret ederler. Bu yüzden ilk refleksiniz doğrudan modele koşmak olmamalı. Önce veriye sertçe bakmak lazım.
Veriyi toparlamak: En sık yapılan hata nerede?
Böyle projelerde ilk iş genelde heyecanla modeli denemektir. Yanlış hamle. Önce yinelenen kayıtlar ayıklanır, eksik değerler temizlenir, aşırı kısa veya anlamsız örnekler çıkarılır ve etiketlerin dağılımına bakılır — yoksa model size gayet kendinden emin bir ifadeyle saçma kümeler döndürür, sonra oturup önü suçlarsınız ama suç sizin.
Bunu gördüm mesela. Mart 2024’te Kadıköy’de çalışan bir arkadaşımın ekibi müşteri geri bildirimlerini kümeliyordu. Veri setinde aynı şikâyet farklı yazımlarla dört kere geçiyordu. Model de doğal olarak bunları ayrı davranış sanmıştı (ben de ilk duyduğumda şaşırmıştım). Temizlik sonrası kalite ciddi biçimde yükseldi (evet, doğru duydunuz). Asıl kazanç güven duygusuydu; ekip artık sonuca biraz daha inanabiliyordu.
Yemek başlıklarında durum biraz daha renkli oluyor çünkü dil yaratıcıdır. İnsanlar aynı şeyi bin türlü söyler. Bir yerde “zucchini bread” görürsünüz, başka yerde “courgette loaf”. Aynı aileden iki ifade. Ama makine için farklı kelime dizileri… Daha fazla bilgi için Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza bakabilirsiniz.
| Adım | Neden önemli? | Etkisi |
|---|---|---|
| Duplikeleri kaldırmak | Aynı örneğin ağırlığını azaltır | Daha dengeli kümeleme |
| NaN temizliği | Boş satırlar modeli şaşırtır | Daha sağlam giriş verisi |
| Çok kısa isimleri elemek | Anlam taşımayan örnekleri azaltır | Daha net sinyal |
| Seyrek etiketleri sınırlamak | Aşırı uç sınıfları kontrol eder | Daha tutarlı değerlendirme |
Bag-of-words neden yetmiyor?
Lafı gevelemeden söyleyeyim: bag-of-words iş görüyor, ama ruhu yok denecek kadar az. Kelimenin ne sıklıkta geçtiğini sayıyor tamam; fakat kelimenin anlamını pek umursamıyor (evet, doğru duydunuz). Bu yaklaşım market poşetindeki ürünleri tek tek saymaya benziyor — elinizde envanter ölür. Akşam yemeğinin ne olduğunu hâlâ çözemezsiniz. Sade. Ama yaniltıcı. Daha fazla bilgi için NASA’nın Artemis II Dönüşü: Pasifik’e İnen O An yazımıza bakabilirsiniz.
Nişan 2025’te evdeki mini veri kümesi üzerinde birkaç örnek denedim ve sonuç baya öğreticiydi — “environmental protection” ile “renewable energy” yakın duruyor gibi görünse de sistem onları beklenmedik şekilde başka şeylerle eşleştirdi, çünkü ortak kelime yoğunluğu tek başına yetmedi, bağlamın ince ipuçlarını tamamen kaçırdı ve ben de o an şunu fark ettim: frekans bilgisi güven verici görünüyor ama aslında sızı yaniltmaya hazır bekliyor. Chunking Neden RAG’in En Büyük Hatası Olabiliyor? yazımızda bu konuya da değinmiştik.
Bag-of-words hızlıdır, anlaşılırdır ve başlangıç için iyidir; ama bağlamın ince detaylarını kaçırdığı için özellikle kısa metinlerde çabuk tıkanır.
Sade olan neden bazen yaniltıcı oluyor?
Şöyle: frekans bilgisi tek başına yön göstermiyor. Bir kelimenin sık geçmesi onun can alıcı olduğu anlamına gelmiyor; tam tersine nadir geçen kelime asıl ipucu olabiliyor (şaşırtıcı ama gerçek). Ve bu farkı bag-of-words görmüyor. Görmek için tasarlanmamış zaten.
Hmm, bunu nasıl anlatsamdı…
Peki hiçbir işe yaramıyor mu?
Tersine! Başlangıç için gayet kullanışlı. Mesela küçük veri setlerinde hızlı prototip kurmak istiyorsanız sızı yüzüstü bırakmaz — ama beklentiyi doğru ayarlamak gerekiyor, aksi hâlde hayal kırıklığı kaçınılmaz.
Anlam taşıyan temsil arayışı: Embedding tarafı niye ilginç?
Vallahi, Gelelim asıl tatlı kısma. Embedding tabanlı temsiller gerçekten başka seviyede duruyor çünkü sözcükleri ya da cümleleri koordinatlara çevirirken bağlama dair ipuçlarını da yaninda getiriyorlar — tabii kusursuz değiller,. Farkları var. Bu biraz harita okumaya benziyor; sadece sokak adını değil, mahallenin genel havasını da görüyorsunuz. Daha fazla bilgi için TypeScript’i Öğrenmek İçin Sıfırdan Form Doğrulama Yazmak yazımıza bakabilirsiniz. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
“all-MiniLM-L6-v2” gibi önceden eğitilmiş modeller burada devreye giriyor ve kısa ifadeleri yoğun vektörlere dönüştürüyor. Sonra kümeleme algoritması bu vektörlere bakıp benzer olanları yaklaştırmaya çalışıyor. Kâğıt üstünde süper duruyor… pratikte işe tokenizasyon tuzakları ve domain farkları yüzünden bazen beklediğiniz kadar pürüzsüz gitmiyor. Peki bunu neden söylüyorum? Şaşırdım açıkçası bazı durumlarda.
Küçük proje ile kurumsal kullanım arasında fark ne?
Küçük ekiplerde embedding yaklaşımı genelde hızlı kazanım sağlıyor çünkü veri hacmi yönetilebilir oluyor ve deney yapmak kolaylaşıyor. Enterprise tarafta işe hikâye değişiyor; sürümleme gerekiyor, izlenebilirlik gerekiyor, maliyet hesabı gerekiyor. Hani ne farkı var diyorsunuz, değil mi? Bir API çağrısı pahalıysa model güzel olsa bile operasyon ekibi yüzünü buruşturuyor — ve haklılar açıkçası.
Maliyet meselesi göz ardı edilmemeli mi?
Tabi ki edilmemeli! Mesela büyük ölçekte her embedding üretimi yeni bir fatura demek olabiliyor. Bu yüzden batch işlem mi yapılacak, gerçek zamanlı mı çalışacak, önbellek kullanılacak mı — bunların hepsi tasarım kararının parçası. Sonradan düşünülecek şeyler değil bunlar.
# Basit fikir akışı
# 1) Metni temizle
# 2) Embedding üret
# 3) Kümeleme yap
# 4) Kümeleri elle kontrol et
titles = clean_titles(raw_titles)
vectors = embedder.encode(titles)
clusters = clustering_model.fit_predict(vectors)
review_clusters(titles, clusters)Kümeleme sonucu gerçekten “anlam” mı veriyor?
Dikkat etmek lazım burada. Kümeleme sihir değil. Model size yalnızca birbirine benzeyen gruplar veriyor; o grupların gerçekten mantıklı olup olmadığına insan gözü karar veriyor. Ben buna hep “ilk taslak editörlüğü” diyorum — makine kaba iskeleti çıkarıyor, siz cilalıyorsunuz. Fark önemli.
- Düşük kaliteli kümeler genelde çok genel terimler içerir.
- Daha iyi kümeler aynı semantik alanın çevresinde toplanır.
- Bazen tekil ama önemli örnekler yanlış yere düşer.
- Sınıf sayısı arttıkça yorumlama zorlaşır. (bu kritik)
Bir de şunlar var, elle kontrol sırasında sık karşılaşılan durumlar:
- Aynı kökten gelen sözcüklerin ayrılması gerekebilir. — ciddi fark yaratıyor
- Sayılar ve özel karakterler bazen gürültüdür.
- Eş anlamlı ifadeler birleşmeyebilir.
- Kategoriler insan mantığıyla birebir örtüşmeyebilir.
Şunu fark ettim: İyi kümeleme, etiketi yeniden düşünmek demek aslında. Bazen model size “doğru” cevabı değil, işe yarar soruyu veriyor. Ve bu da bir kazanım sayılabilir bence.
Bundan sonra ne yapardım?
Etiket sayısını azaltmak yerine önce hiyerarşi kurmayı denerdim. Mesela “tatlı”, “ana yemek”, “salata”, “içecek” gibi üst sınıflar belirleyip ardından alt kırılımlara inmek çoğu zaman daha sağlıklı oluyor — çünkü çok ince ayrıntıya erken dalınca hem hata artıyor hem yorumlama yoruluyor, ve bir noktadan sonra ekip sonuçlara güvenmeyi bırakıyor ki bu en kötü senaryo.
Bir diğer nokta da değerlendirme kısmı (buna dikkat edin). Silhouette skoru güzel görünebilir. Ama gerçek kullanıcıya fayda sağlıyor mu? İşte kritik soru bu. Geçen yıl İzmir’de yaptığım küçük bir denemede skor yükselmişti fakat manuel kontrolde kümelerin yarısı anlamsız çıkmıştı. O an şunu düşündüm: metrik her şeyi anlatmıyor.
Küçük ölçek için hızlı prototip yeterliyken büyük organizasyonda loglama, versiyon takibi, geri dönüş mekanizması şart oluyor. Aksi hâlde altından bir düşüneyim… kalkması zor bir teknik borç büyüyor. Ve o borcu kim ödeyecek? Genelde projeyi başlatan ekip değil, önü devralan ekip — bu da ayrı bir acı konu.
Sıkça Sorulan Sorular
Kısa metinlerde bag-of-words neden zayıf kalıyor?
Oops again? Need final proper HTML only after title line.
Kaynaklar ve İleri Okuma
Azure OpenAI Service dokümantasyonu
Azure AI Language – Text Analytics genel bakış
Veri hazırlama (Azure Architecture Center)
scikit-learn: Clustering & Text özelliklendirme örnekleri

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



