Bakın şimdi, yapay zekâ deyince çoğu kişi hâlâ “sihir” tarafına takılıyor. Oysa işin aslı şu: modelin arkasında epey mekanik bir düzen var. Geçen ay, 2026 Şubat’ında İstanbul’daki bir editör toplantısında bu konuyu anlatırken şunu fark ettim — insanlar en çok “neden bazen saçmalıyor?” sorusuna odaklanıyor. Güzel soru bu arada. Çünkü cevabı token’dan context window’a kadar uzanıyor ve açık konuşayım, mesele sadece dil değil; aynı zamanda sınırlı alan, olasılık hesabı ve hafif bir kumar masası dinamiği.
Claude Code 101 serisinin bu ayağında ben konuyu LEGO üzerinden okumayı seviyorum. Her şey küçük parçalar gibi — tek tek diziliyor, sonra ortaya anlamlı görünen bir yapı çıkıyor. Ama bazı parçalar eksikse ya da fazla güç uygularsanız dağılıyor. LLM’ler de böyle işte. Çalışıyorlar, tamam. Ama insan gibi düşünmüyorlar. Bu ayrımı kaçırınca hem beklenti şişiyor hem de hayal kırıklığı kapıyı çalıyor.
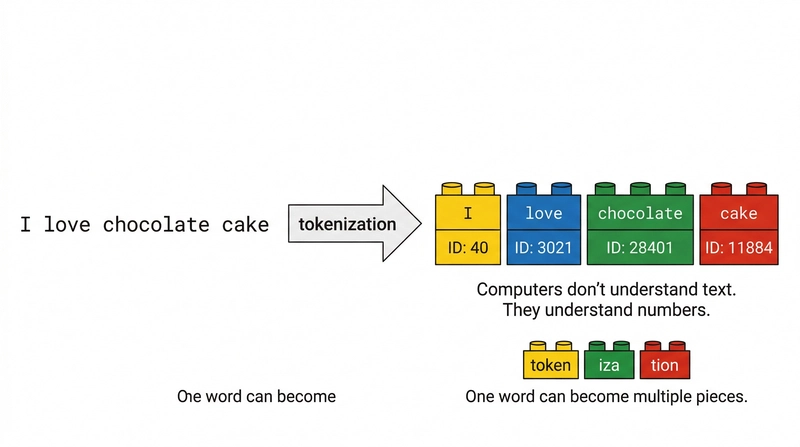
Token nedir, neden cebinizi yakar?
Şunu fark ettim: Token kelimesi ilk bakışta teknik geliyor. Ama günlük hayatta karşılığı baya basit: modelin gördüğü küçük metin parçaları. Bir kelime bazen tek token ölür, bazen üçe bölünür, bazen de noktalama işareti ayrı sayılır — yani “merhaba” ile “merhabalar” arasında maliyet farkı bile çıkabiliyor, inanılır gibi değil ama öyle. İşte burada aklınıza şu soru geliyor muhtemelen: nasıl yani, aynı cümle daha pahalı olabilir mi? Evet. Olabilir.
Ben bunu ilk kez 2023 Kasım’ında Ankara’da bir fintech ekibiyle test ederken net gördüm. Türkçe rapor özetleri gönderiyorduk ve İngilizce versiyonla kıyaslayınca tüketim bariz artmıştı. Sebebi romantik değil: Türkçe kelimeler daha çok parçalanıyor, bu kadar (yanlış duymadınız). Tahmin eder mısınız? Modelin gözünde uzun ve eklemeli diller, lego setinin kutusuna sığmayan parçalar gibi duruyor biraz (yanlış duymadınız)
Evet, doğru duydunuz.
Dür, şöyle de anlatayım: tokenizasyon meselesi sadece fiyat değil, bağlam kapasitesi meselesi de aynı anda gündeme geliyor. Prompt’a daha çok içerik sıkıştırdıkça modelin elindeki pencere daralıyor. Kısa cevap mı istiyorsunuz? Ucuz olabilir. Uzun analiz mi? Cüzdan biraz terliyor.
BPE mantığı neden önemli?
BPE — yani Byte Pair Encoding — modelin kelimeleri hazır paketler hâlinde değil, tekrar eden parçalara bölerek öğrenmesini sağlıyor. Bu yöntem İngilizce’de fena çalışmıyor çünkü eğitim verisi büyük ölçüde oradan besleniyor. Hani ne farkı var diyorsunuz, değil mi? Türkçe’de durum biraz yamuk yumuk; ekler işin içine girince parçalanma artıyor, bu da hem maliyeti hem de modelin anlamayı ne kadar iyi kurduğunu etkiliyor. Daha fazla bilgi için Huawei ICT Day 2026: Dijital Dönüşümün Nabzı yazımıza bakabilirsiniz. Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik.
Mesela “çalıştırılabilecekmişsiniz” gibi uzun bir kelimeyi düşünün — evet, abarttım, bilerek. İnsan okur geçer. Model işe önü birkaç tokene ayırıyor ve her parça için ayrı hesap yapıyor (evet, doğru duydunuz). İlginç, değil mi? Bazen komik bazen can sıkıcı, ikisi bir arada. GLM-5.1 neden bu kadar konuşuluyor? Sekiz saatlik yapay zekâ işi yazımızda bu konuya da değinmiştik.
Context window: Masadaki yer sınırlıysa ne ölür?
Vallahi, Context window’u ben genelde çalışma masasına benzetiyorum. Masada defteriniz var, kahveniz var, klavyeniz — en azından ben öyle düşünüyorum — var; daha fazlasını koyarsanız ya düşer ya da karışır, üçüncü seçenek yok. Model için de aynısı geçerli: belirli bir oturumda yalnızca belli miktarda metni aktif tutabiliyor, kalanı gözünden kayıyor.
Küçük startup’larda bu fark bazen gözden kaçıyor çünkü testlerde her şey şahane görünüyor. Binlerce satırlık doküman yok, karmaşık bağlam yok. Ama kurumsal projede işler değişiyor. 2025 Mart’ında İstanbul’da çalışan bir ekip bana şunu söylemişti: “Özet iyi. Son bölüm hep unutuluyor.” Tabii unutuluyor. Pencere dolmuş. Ex-Apple mühendislerinden iPod Shuffle benzeri AI düğmesi: Neden? yazımızda bu konuya da değinmiştik.
Neyse, uzatmayalım. Context window büyüdükçe model daha fazla şeyi aynı anda görebiliyor — bu güzel, evet. Yine de büyük pencere otomatik olarak daha akıllı demek değil. İçeriğin tamamını gerçekten “anladığını” sanmak hata ölür, bunu baştan söyleyeyim.
| Kavram | Kısaca ne işe yarar? | Sahadaki etkisi |
|---|---|---|
| Token | Metnin en küçük işlem parçası | Maliyet ve hız üzerinde doğrudan etkili |
| Context window | Aynı anda tutulabilen bilgi alanı | Uzun konuşmalarda hatırlama kalitesini belirler |
| BPE | Kelimeleri alt parçalara bölen sistem | Diller arası verim farkı yaratır |
| Attention | Kritik kısımlara ağırlık verme yöntemi | Cümlenin neresine odaklanacağını etkiler |
Peki model metni nasıl üretiyor?
Lafı gevelemeden söyleyeyim: model cümleyi baştan sona planlamıyor. Sonraki en uygun token’ı tahmin ediyor, önü takıp eden başka bir tahmin yapıyor, zincir böyle gidiyor (buna dikkat edin). Konuşma hissi oluşuyor, güzel. Ama altında yatan şey esasen ardışık olasılık hesabı — romantik bir yani yok. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
Bunu ilk test ettiğimde şaşırmıştım doğrusu. 2024 Haziran’ında Bursa’daki bir ürün demosunda aynı prompt’u üç kez verdik; çıkan yanitların tonu ufak tefek oynuyordu. Neden? Çünkü seçim mekanizması tamamen deterministik değil diyoruz da pratikte o kadar temiz değil işte. Biraz kumarhane dinamiği var, az da olsa.
# Basit fikir:
# giriş metni → tokenize et → bağlamdan en olası sonraki token'ı seç
# sonra bunu tekrar et
input_text = "Bugün hava"
next_token = model.predict_next_token(input_text)
output = input_text + next_token
Sadece en yüksek ihtimali seçseydi ne olurdu?
Kısa cevap: sonuçlar aşırı sıkıcı olurdu. Tek tıp. Model hep en güvenli yolu seçseydi yaratıcılık diye bir şey kalmazdı, makul bir gazete özeti bile çıkmaz aslında. Bu yüzden sıcaklık gibi parametrelerle seçim biraz esnetiliyor — biraz rastgelelik ekleniyor sisteme.
Sıcakkanlılık mı, belirsizlik mi?
Tam burada ince çizgi var. Fazla rastgelelik saçmalamaya götürüyor, az rastgelelik işe robotik yanitlara. İkisi arasında denge kurmak gerekiyor ve açıkçası herkes bunu iyi yapamıyor — ben de dahil bazen.
Dikkat mekanizması neden olayın kalbi?
Attention mekanizmasını ben hep şuna benzetiyorum: on kişinin konuştuğu bir toplantıda doğru kişiye bakmak. Herkese eşit dikkat verirseniz kritik detayı kaçırırsınız. Model de bazı token’lara diğerlerinden fazla önem veriyor — işte o seçim, attention mekanizmasıyla oluyor.
Şahsen, Teoride çok temiz görünüyor bu. Pratikte? Mükemmel değil. Bilhassa uzun içerikte uzak ilişkilendirmeler bozulabiliyor — bir cümlenin başındaki işim ile sondaki zamiri eşleştirme işi bazen çatlıyor. Beklediğim kadar iyi değildi dediğim noktalardan biri tam da burasıdır (kendi tecrübem)
Model güçlü görünür ama her şeyi hatırlamaz; sadece elindeki pencerede kalan parçaları tartar ve ona göre hamle yapar.
Neleri yapamaz? Burası önemli!
Bu kısmı atlayanlar sonra üzülüyor. Model inatçı biçimde gerçeklik duygusuna sahip değil — yani dış dünyayı canlı canlı izlemiyor. İnternete bağlı değilse güncel bilgiyi bilemez; bağlı olsa bile eriştiği kaynakları doğrulamak yine sizin derdiniz ölür. Pratik mi? Değil. Ama gerçek bu.
Matematiksel kesinlik konusunda da sınırları var. Basit işlemleri hallediyor ama karmaşık doğrulamalarda hata çıkarabiliyor — beklenmedik anlarda. Bir arkadaşımın Dubai’deki SaaS şirketinde yaşadığı olay hâlâ aklımdadır: müşteri desteğinde yanlış tarih önerisi yüzünden iki bilet boşa gitmişti. Güldük ama aslında ciddi bir dersti.
Evet, doğru duydunuz.
- Çoğu zaman doğruyu söylemez;
- Emin olmadığı yerde bile özgüvenli konuşabilir;
- Eğitim verisindeki önyargıları taşıyabilir;
- Uzun bağlamlarda detay kaçırabilir;
- Maliyet tarafını küçümseyip büyütebilirsiniz. (bu kritik)
Maliyet meselesi niye sessizce büyüyor?
Sıkça Sorulan Sorular
Token tam olarak nedir ve neden maliyeti etkiler?
Token, modelin gördüğü küçük metin parçaları gibi düşünebilirsiniz. Bir kelime bazen tek token olurken bazen daha küçük parçalara bölünebilir; bu yüzden aynı mesajın token sayısı değişebilir. Token sayısı arttıkça hem maliyet yükselir hem de context window daralır.
Türkçe neden bazen İngilizceye göre daha fazla token harcatıyor?
Türkçede ekler ve eklemeler daha yoğun olduğu için kelimeler daha sık parçalara ayrılabiliyor. Bu da token sayısını artırarak maliyeti ve bağlam kullanımını etkileyebiliyor. Ben bunu özellikle rapor özetlerinde net gördüm; Türkçe versiyon daha hızlı “pencereyi dolduruyor”.
Context window (bağlam penceresi) “neden bazen saçmalamaya” yol açıyor?
Çünkü modelin elindeki sınırlı alan, prompt içinde ne kadar bilgi taşıdığına göre doluyor. Pencere daraldığında önceki talimatlar/bağlam geri planda kalabiliyor ve model daha tutarsız yanitlar verebiliyor. Bu yüzden uzun sohbetlerde özetleme ya da tekrar eden talimatları kısaltmak işe yarıyor.
BPE (Byte Pair Encoding) ne işe yarar, bende fark eder mi?
BPE, metni tek tek “hazır kelimeler” gibi değil, tekrar eden parçalara ayırarak daha verimli bir temsil kurar. Bu sayede model eğitim verisindeki kalıplardan faydalanır. Ancak Türkçe gibi eklemeli dillerde parçalanma daha görünür olabildiği için hem maliyet hem de yanit kalitesi etkilenebilir.
Token sayısını azaltmak için pratikte ne yapabilirim?
Mesajı gereksiz uzatmadan, tekrarları temizleyip net talimatlar vermek genelde en hızlı kazanım. Ayrıca uzun içeriklerde “özetle ve sonra sor” yaklaşımıyla önce kısaltıp sonra işlem yapmak iyi sonuç veriyor. Benim en çok işe yarayan yöntem, her adımda hedefi tek cümleyle sabitlemek ve örnekleri minimumda tutmak oldu.
Kaynaklar ve İleri Okuma
Azure OpenAI Service – Kavramlar
Azure OpenAI – Modeller ve özellikler
tiktoken (token sayımı ve tokenizasyon araçları)
Hugging Face – Tokenization ve alt kelime yaklaşımları (BPE)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.