Bak şimdi, Geçen ay, Kadıköy’de bir kahve molasında önümdeki iki geliştirici aynı cümleyi kurdu: “Copilot kullanıyoruz. Iş AI ile ürün yapmaya gelince duvara tosluyoruz.” Açık konuşayım, bu cümle bana hiç yabancı gelmedi (evet, doğru duydunuz). Çünkü çoğu ekip yapay zekâyı bir sihir kutusu gibi görüyor — oysa ortada katman katman duran, gayet somut parçalar var ve bunları görmezden gelince işler sarpa sarıyor.
Ben de 2023 sonbaharında kendi küçük yan projemde bunu acı şekilde öğrendim. Bir müşteri destek özelliği eklemiştim. İlk başta sadece modeli çağırıp cevap döndürmek yeterli sanmıştım. Yetmedi. Context taşması oldu, yanlış araç çağrıları geldi, hatta model eski bir fiyat listesini yeni sanıp kullanıcıya saçma sapan bilgi verdi — o gün gerçekten içim sıkıştı. Tahmin eder mısınız? İşte o noktada anladım: AI geliştirme işi, prompt yazmaktan ibaret değil.
İşin Temeli: Model Ne Yapıyor, Ne Yapmıyor?
Hani, Lafı gevelemeden başlayayım. Dil modeli dediğimiz şey aslında bir tahmin makinesi. Evet, kulağa biraz kuru geliyor ama gerçek bu. “Şu kelimeden sonra hangisi gelir?” sorusuna istatistiksel olarak en iyi cevabı veriyor — yani modelin kafasında insan gibi düşünme falan yok, daha çok devasa bir otomatik tamamlama motoru var ve bu motoru besleyen şey milyonlarca örnekten çıkarılan örüntüler.
Bi saniye — Mesela “Bugün hava çok…” diye başladığınızda “güzel” ya da “sıcak” demesi beklenir (bizzat test ettim). Yüzey kısmı bu. Ama model bunu milyonlarca örnekten öğreniyor. Kelimeler arasındaki ilişkiyi sayısal hâle getiriyor — hani mutfakta el yordamıyla ölçü koyarsınız ya, biraz tuz, biraz su, işte model de benzer şekilde olasılıklarla oynuyor.
Kısa bir not düşeyim buraya.
Burada kritik kavram: token. Token bazen tek harf ölür, bazen kelime parçası, bazen de bütün bir kelimeye denk gelir — dürüst olayım, biraz hayal kırıklığı —. Geçen hafta Beşiktaş’taki ofiste çalışan bir arkadaşla bunu tartıştık — adam hâlâ token’ı “kelime sayısı” sanıyordu. Değil işte. Token sayısı artınca maliyet de artıyor, bağlam limiti de daha çabuk doluyor (yanlış duymadınız). Bir bakıma, i̇kişi aynı anda.
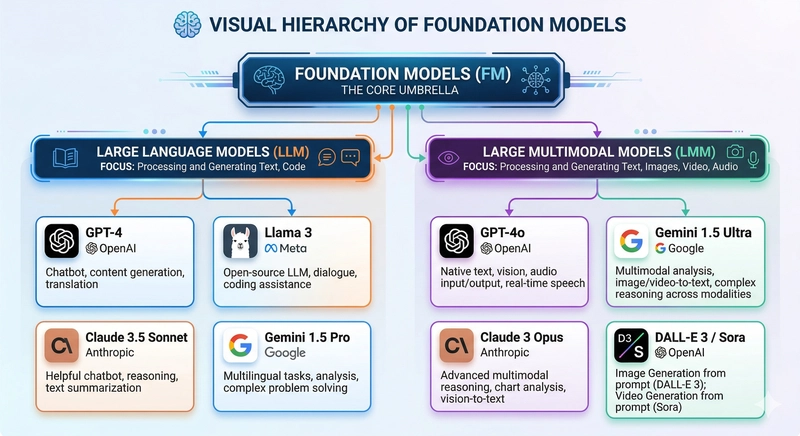
LM mi LLM mi? Aradaki fark neden önemli?
Kısaca söyleyeyim. LM genel kavramdır, LLM işe bunun büyük ölçekli hâli. Büyük ölçek deyince sadece daha fazla veri demiyorum — kapasite değişiyor ve ortaya yeni yetenekler çıkıyor. Kod yazma, özetleme, plan çıkarma gibi beceriler burada belirginleşiyor. Bunu sanki fark yok gibi geçiştiren yazılara rastlıyorum, ama fark var.
Bana göre asıl şaşırtıcı nokta şu: Bu yeteneklerin çoğu tek tek programlanmış değil. Ölçek büyüyünce kendiliğinden görünür hâle geliyor — yani emergent behavior dediğimiz şey tam da bu. Planlanmamış, beklenmedik, bazen şaşırtıcı.
| Kavram | Kısaca ne? | Nerede işe yarar? |
|---|---|---|
| LM | Dil olasılığı tahmini yapan model | Metin tamamlama, basit sınıflandırma |
| LLM | Büyük veriyle eğitilmiş gelişmiş dil modeli | Sohbet botları, kod üretimi, analiz |
| Foundation Model | Daha geniş şemsiye; metin + görsel + ses olabilir | Multimodal ürünler |
Ajan Mantığı: Tek Atışlık Cevap Değil Döngü
Eh, Ajan konusu bence çoğu geliştiricinin ilk anda hafife aldığı yer (şaşırtıcı ama gerçek). Neden? Çünkü dışarıdan bakınca olay basit görünüyor: modele soru soruyorsun, cevap veriyor, bitti sanıyorsun. Ama ajan dediğin yapı öyle çalışmıyor — işi adım adım, bazen geri dönerek, bazen aynı şeyi farklı şekilde deneyerek hallediyor.
Bunu geçen mart ayında İstanbul Maslak’ta yaptığım küçük demo sırasında net gördüm. Kullanıcıdan gelen talep önce planlandı, sonra araç çağrıldı, ardından sonuç tekrar modele verildi, sonra bir tür daha dönüldü — ilk denemede gereksiz yere üç kez API çağırdı ve ben ekran karşısında iç geçirdim doğrusu. Optimize edilmemiş bir ajan, hem yavaş hem pahalı olabiliyor.
Döngü nasıl işliyor?
THINK → ACT → OBSERVE → THINK → ACT → OBSERVE
Bu zinciri anlamadan sağlam AI ürünü yapmak zorlaşıyor. Her aşamada hata çıkabiliyor çünkü — THINK kısmında model yanlış niyet okuyabilir, ACT kısmında yanlış aracı seçebilir, OBSERVE tarafında da gelen sonucu yanlış yorumlayabilir. Üç ayrı hata noktası, tek bir kullanıcı isteği için. Daha fazla bilgi için Anker Nano Power Bank Avrupa’ya Döndü: İnce, Küçük, Turuncu yazımıza bakabilirsiniz.
Yani, E tabi güzel taraf da var. Doğru kurgulanırsa ajanlar kullanıcı için inanılmaz pratik oluyorlar — mesela dosya tarayıp rapor hazırlayan bir yardımcı ya da CRM içinde kayıt açan akıllı asistan gibi. Ama “doğru kurgulanırsa” kısmını atlamamak lazım. Daha fazla bilgi için Bulutlar Arasında Agent Kurmak: ADK, ECS Express ve Gemini yazımıza bakabilirsiniz.
Bir ajan sistemi kurarken en büyük hata “model her şeyi bilir” varsayımıdır.
Aslında — hayır dür, daha doğrusu model tek başına konuşur; işi yapan araçtır.
Aracı vermediğiniz sürece elinde çekiç olmayan ustaya benzer.
Araçlar Olmadan Elinizde Sadece Çok Akıllı Bir Otomatik Tamamlama Var
Araç meselesi önemli. LLM kendi başına dünyaya dokunamıyor — dosya açamaz, canlı fiyat çekemez, veritabanına kayıt atamaz. Bunların hepsi tool entegrasyonu istiyor. Ve bu entegrasyonu doğru yapmadan “AI ürünü” yapmak aslında çok güzel çalışan bir demo yapmak anlamına geliyor çoğu zaman.
Editör masasında geçen hafta buna dair başka bir örnek gördüm. Bir ekip ChatGPT tarzı sohbet deneyimi yapmıştı ama sistem gerçek zamanlı stok sorgulayamıyordu. Sonuç? Kullanıcıya “stok var” deniyordu ama depoda ürün bitmişti. Hayal kırıklığı mı? Evet. Ciddi. Çünkü güzel görünen demo ile sahadaki gerçek kullanım arasında bazen dağ kadar fark oluyor.
Ve işler burada ilginçleşiyor.
- web_search: Canlı bilgi toplar ama güvenilirlik filtresi şarttır. — ciddi fark yaratıyor
- query_db: Kurumsal senaryolarda çok güçlüdür fakat izin yönetimi gerekir.
- send_email: Kullanışlıdır ama onaysız çalışırsa ortalık karışır!
- write_file: Otomasyon için iyidir; yine de versiyonlama şarttır.
İtiraf edeyim, Küçük startup tarafında genelde işler hızlı yürür — birkaç tool ile MVP çıkarırsınız, müşteriden geri bildirim toplarsınız, sonraki versiyona geçersiniz. Enterprise seviyede işe durum farklı. Orada kimlik doğrulama, loglama, audit trail, veri sınırlaması derken yapı ağırlaşıyor. Ama açık konuşayım, ağırlaşması kötü değil; sadece düzen istiyor (ciddiyim) Daha fazla bilgi için CoreWeave ile Anthropıc’in Yeni Hamlesi: Nvidia Gücü Büyüyor yazımıza bakabilirsiniz. Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik.
Kontekst Nedir? Hafızanın Sınırı Nerede Başlıyor?
Küçük bir detay: Kontekst dediğimiz şey, modeli beslediğiniz çalışma alanı gibi düşünebilirsiniz. Masaya ne kadar kâğıt koyarsanız önünüzde o kadar bilgi ölür —. Masa küçücükse üst üste yığılır, en alttakini göremezsiniz. AI sistemlerinde de aynısı yaşanıyor. Model geçmiş mesajları, sistem talimatlarını, araç çıktısını ve bazen belge parçalarını birlikte görüyor; ama hepsini aynı anda tutabilmesi için yeterli “masa alanı” olması lazım (eh, fena değil)
Şimdi gelelim işin can alıcı noktasına. Daha fazla bilgi için PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza bakabilirsiniz.
Nişan 2024’te Ankara’da test ettiğim bir projede kontekst sınırı yüzünden komik sayılabilecek ama pahalıya patlayan hatalar yaşadık. Uzun toplantı notlarını olduğu gibi yollayınca model ana talebi unutmaya başladı. Kısacası hafızası doldu — biz işe hâlâ ona roman okutuyorduk. Maalesef.
Neleri tutmalı, neleri dışarıda bırakmalı?
Bence iyi mühendislik burada başlıyor. Her şeyi kontekste tıkıştırmak yerine doğru özetleme, doğru sıralama ve gerektiğinde geri getirme (retrieval) kullanmak lazım — aksi hâlde hem maliyet şişiyor hem kalite düşüyor. İkisi aynı anda. Kötü kombinasyon.
{
"system": "Rol tanımı",
"messages": [
{"role": "user", "content": "Kullanıcı isteği"},
{"role": "tool", "content": "Araç çıktısı"},
{"role": "assistant", "content": "Ara yanit"}
]
}
Mimaride Düşünmek İçin Pratik Bir Çerçeve
Tuhaf ama, Aşağıdaki ayrımı kafada tutmak bence baya işe yarıyor:
- Model = beyin değil, tahmin motoru
- Tool = elleri olan kısım — bunu es geçmeyin
- Context = kısa süreli hafıza — ciddi fark yaratıyor
- Agent = karar verip tekrar deneyen orkestratör
Bu ayrım netleşince debug etmek kolaylaşıyor. Mesela kullanıcı yanlış sonuç alıyorsa — sorun prompt’ta mı? Yoksa tool çıktısı mı bozuk? Belki context fazla uzun. Belki de agent gereksiz tür atıyor. Yani sorun hep aynı yerde değil; bazen zincirin bambaşka bir halkasında saklanıyor. Bunu bilmeden rasgele değişiklik yapmak saatler harcatıyor.
Ha, bu arada LLM Nedir? Büyük Dil Modelleri Nasıl Çalışıyor? yazısı, temel kavramları toparlamak isteyenler için iyi bir başlangıç noktası. Bir de Google’ın Prompt Rehberi: İyi Komutun Anatomisi — prompt tarafını derleyip toparlamak açısından faydalıydı benim gözümde, okumaya değer.
Nereden Başlamalı? Küçük Ekip İçin Başka, Kurumsal İçin Başka
Küçük ekiplerde ben genelde şu sırayı öneriyorum:
- Basit chat akışı kur
- Tek tool ekle
- Log tut
- Context boyutunu izle
- Hata senaryosu yaz
Bu kadar. İlk etapta karmaşık multi-agent mimarı kurmaya çalışmak gereksiz olabilir — hatta düpedüz kafa karıştırır. Siz henüz tek ajanın bile nasıl davrandığını tam anlamadan beş ajanlı sistem kurarsanız, debug etmek kâbus hâline geliyor. Bunu bizzat yaşayanlar bilir.
Kurumsal tarafta işe erişim kontrolü, PII maskesi, rate limit ve gözlemleme şart oluyor. Geçen yıl Levent’te danışmanlık yaptığım küçük bir finans projesinde bunları sonradan eklemek zorunda kaldılar — keşke en baştan düşünülseydi dedirten türden işlerdi bu. Sonradan yamak zor, pahalı ve sınır bozucu.
Bakın, şimdi önemli nokta şu: AI stack’i öğrenmek aslında yeni moda terimleri ezberlemek değil. Hangi parçanın nerede durduğunu görmek demek — bunu oturttuğunuzda hem ürün kararlarınız iyileşiyor hem de vendor pazarlamasına daha az kanıyorsunuz. Güzel özellik mi? Evet. Ama henüz ham olan yerleri de böl; özellikle değerlendirme (evaluation) kısmını çoğu takım ciddiye almıyor. Alamıyor da belki, zaman yok, baskı var. Anlıyorum. Ama o kısmı atlayınca ileride daha büyük sorunlarla boğuşuyorsunuz.
Sıkça Sorulan Sorular
Ajan ile chatbot arasındaki fark nedir?
Sohbet botu genelde tek seferlik yanit verirken ajan görev tamamlanana kadar döngü hâlinde çalışır. Araç kullanır, sonuç okur gerekirse yeniden dener. Kısacası ajan daha eylem odaklıdır.
LMM ile LLM aynı şey mi?
Aynı şey değiller. LLM metne odaklanır,LMM işe metnin yaninda görsel, ses video gibi farklı medya türlerini de işleyebilir. Multimodal ürünlerde fark hemen hissedilir. (buna dikkat edin)
Tamamını modele verirsem sorun çözülür mü?
Pek sayılmaz. Çok uzun context hem maliyeti artırır hem modeli şaşırtabilir. En iyisi ilgili bilgiyi seçip vermek veya özetleyerek sunmaktır.
KÜÇÜK BİR STARTUP İÇİN EN ÖNEMLİ PARÇA NE?
BENCE LOGLAMA VE BASİT DEĞERLENDİRME. DEMO GÜZEL OLABİLİR AMA ÜRETİMDE NE OLDUĞUNU ANLAMAZSANIZ HER ŞEY DAĞILIR.
KAYNAKLAR VE İLERİ OKUMA
OpenAI — Introduction to Models and Tools
Google AI Developer Documentation

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.