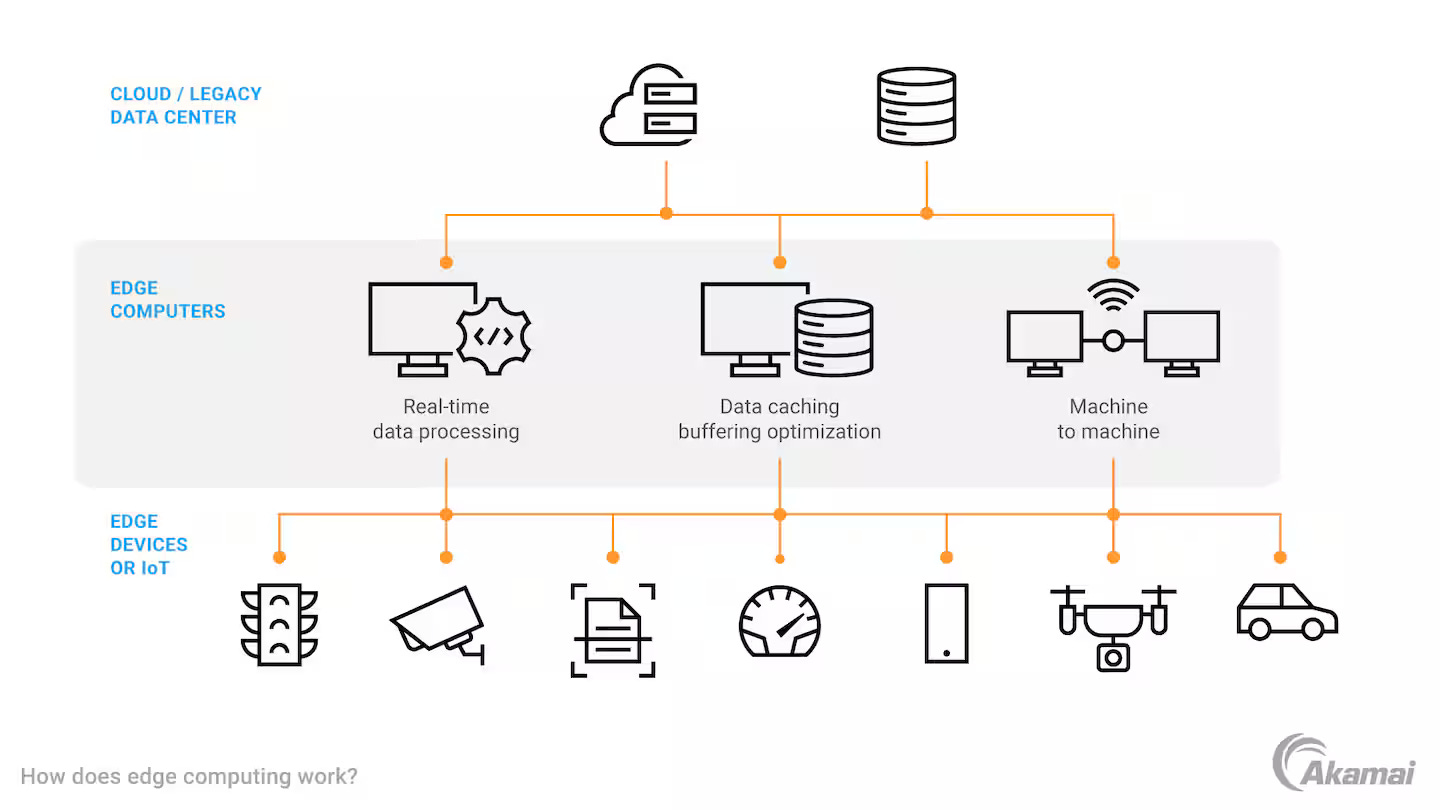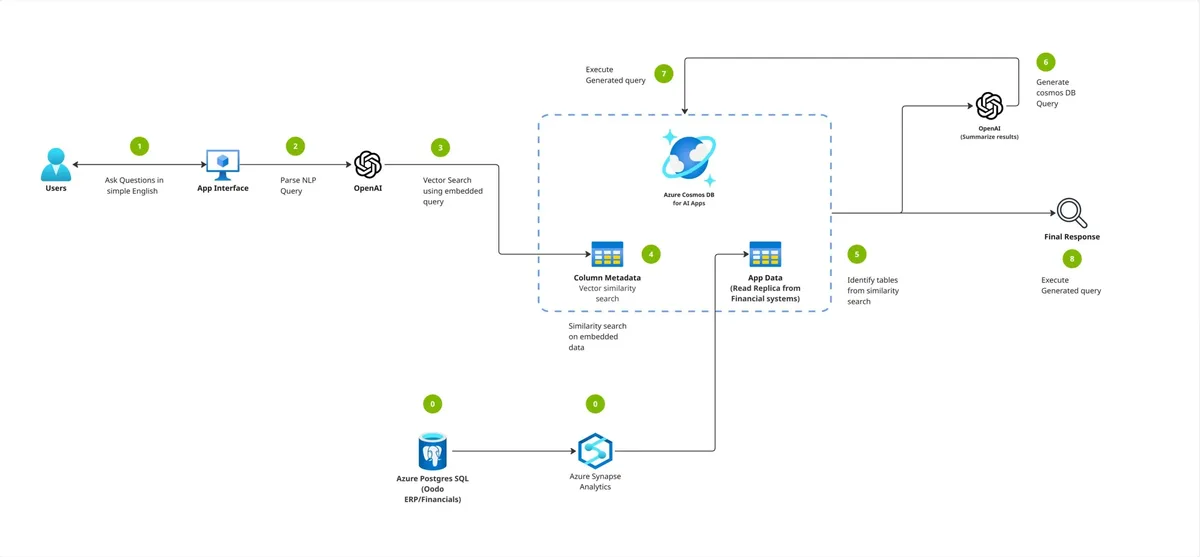
Geçen hafta bir müşteride tam da şu soruyla karşılaştım: “Aşkın bey, biz POC’u geçtik, GenAI çalışıyor, ama 50 kullanıcıya açtığımız anda her şey çatırdamaya başladı. Vector search yavaşladı, latency 8 saniyeye çıktı, maliyet üç katına bindi. Ne yapacağız?” Tanıdık geldi mi? Bana baya tanıdık geldi. Çünkü 2024’ten beri gördüğüm GenAI projelerinin neredeyse yarısı aynı duvara tosluyor.
Bunu yaşayan biri olarak söyleyeyim, İşin aslı şu: demo yapmak kolay. Production’a almak işe başka hikâye. Microsoft’un Scalable AI in Action with Azure Cosmos DB serisinin Nişan ayındaki AVASOFT oturumunu izleyince — açık konuşayım, ben de canlı bağlandım — bu duvarı aşmak için Cosmos DB’nın neden kritik bir rol oynadığını bir kez daha gördüm. Bugün hem o oturumdan çıkardıklarımı hem de sahada biriktirdiğim notları paylaşacağım.
Önce Sorunu Doğru Koyalım: Kurumsal GenAI Neden Tıkanıyor?
Bak şimdi. Bir kurumsal müşteri düşünün; mesela orta ölçekli bir sigorta şirketi. Aylık binlerce poliçe, ekspertiz raporu, hasar dosyası ve regülasyon dökümanı işliyorlar. Bunların çoğu PDF, bir kısmı taranmış görsel, bir kısmı Word, bir kısmı da SAP’den çıkmış yapısal veri. GenAI çağına girince herkes haklı olarak şunu soruyor: “Bu içeriği Copilot’a verip soru cevap yapsak, çalışan verimini iki katına çıkarmaz mıyız?”
Çok konuştum, örnekle göstereyim.
Aslında, Cevap evet. Ama nasıl yaptığınız çok önemli.
Sairam Srinivasan (AVASOFT CTO’su) oturumda güzel bir şey söyledi; özeti şu gibiydi: “Kurumsal müşterilerin yaşadığı esas sorun model değil, mimarı.” Ben de yıllardır bunu söylüyorum aslında. Açık konuşayım, GPT-4 mü yoksa Claude mu kullanacağınız meselesi toplam başarının küçük bir parçası kalıyor. Geri kalan tarafta veri yapısı, indexleme stratejisi, retrieval kalitesi. Latency bütçesi var; işte orada kazanıyorsunuz ya da kaybediyorsunuz.
“GenAI’ın production’a geçişini engelleyen şey modelin yetenekleri değil, çoğu zaman altındaki veri katmanının ölçeklenememesi. Bunu görmezden gelirseniz, POC’ünüz hep güzeldir, production’ünüz hep sorunlu ölür.” — kendi gözlemim, son 18 ayda en az 10 müşteride.
AVASOFT Nexus: Mimarı Olarak Ne Yapıyor?
Sarvesh ve Balamurugan’ın oturumda yaptığı walkthrough’u izlerken en hoşuma giden şey slide’lar değil, doğrudan kod ve config göstermeleriydi. Bu seride sevdiğim taraf da bu zaten; pazarlama balonu yok, mühendislik var.
Bir dakika — bununla bitmedi.
Nexus’un kabaca yaptığı şey şu: Kurumsal içeriği (sözleşmeler, raporlar, sahadan gelen dökümanlar ve görseller) Azure Cosmos DB’de hem operasyonel veri hem de vektör olarak tutmak. Üzerine retrieval-augmented generation (RAG) pipeline’ı kurmak. Sonra Copilot benzeri bir kullanıcı arayüzünden erişilebilir hâle getirmek.
Neden Cosmos DB? Diğer Vector Store’lar Ne Olacak?
İşte burası biraz tartışmalı. Pinecone var, Weaviate var, Qdrant var; hatta Postgres pgvector bile var. Bunların hepsini denedim, birkaçını production’da da çalıştırdım. Şimdi dürüst değerlendirmemi söyleyeyim:
| Kriter | Cosmos DB (NoSQL + Vector) | Dedicated Vector DB | pgvector |
|---|---|---|---|
| Operasyonel + vektör tek yerde | Evet | Hayır (ayrı sync gerekir) | Evet |
| Global dağıtım | Multi-region native | Genelde sınırlı | Manuel kurulum |
| Latency (p99) | 10-50ms aralığı | Değişken | Yük altında düşer |
| SLA | %99.999 | Provider’a göre | Kendi sorumluluğunuz |
| Maliyet (RU model) | Workload’a göre | Genelde sabit + storage | VM maliyeti |
Cosmos DB’nın güçlü olduğu yer şu: operasyonel veriyle vektör verisini aynı yerde tutuyorsunuz. Yanı bir sözleşmenin metadata’sı (taraflar, tarih, durum) ile o sözleşmenin embedding’leri yan yana duruyor. Sorgu yazarken JOIN derdi yok gıbı hissediyorsunuz; eventual consistency derdi azalıyor; iki ayrı sistem arasında sync kovalamıyorsunuz. Bu dertleri ben bizzat yaşadım — 2024’te bir telekom projesinde Pinecone ile PostgreSQL’i senkron tutmaya çalışırken epey yorulmuştum.
DiskANN: Sessiz Sedasız Bir Devrim
Bu arada durun; bunu atlamayayım. Cosmos DB’nın vector search tarafında kullandığı DiskANN algoritması Microsoft Research’ten çıkan bir iş. Klasik HNSW’ye göre disk üzerinde daha verimli çalışıyor; yanı 100 milyon embedding’i RAM’e doldurmak zorunda değilsiniz. Bu da maliyet tarafında fark yaratıyor çünkü her şeyi belleğe basmak zorunda kalmıyorsunuz.
Daha önce buna kısmen Azure SQL’de AI_GENERATE_EMBEDDINGS GA Öldü: Saha Notları) yazımda değinmiştim; oraya da bakmanızı tavsiye ederim.
Neyse Uzatmayalım: Türkiye Perspektifi Nasıl?
Ne yalan söyleyeyim, Türkiye’deki kurumsal müşterilerimde gördüğüm tablo şu: bankacılık. Sigorta tarafı hızlı hareket ediyor; özellikle BDDK uyumluluğu ve KVKK gereği veriyi yurt içinde tutmak zorunda olanlar için Azure’un Türkiye region’ları ciddi avantaj sağlayacak gıbı duruyor — henüz tam GA değil ama yakın zamanda olabilir diye düşünüyorum. Şu an İstanbul’dan en yakın Cosmos DB region’ı Amsterdam ya da Frankfurt. Latency olarak 35-45ms civarı; idare eder ama ideal değil. Daha fazla bilgi için GitHub Copilot Modernize 101: Java Modernizasyonu Artık yazımıza bakabilirsiniz.
Peki bütçe? Orada işler biraz sertleşiyor. KOBİ ve mid-market segmentinde klasik — itiraz edebilirsiniz tabi — problem aynı: para gerçekçi değil ya da beklenti fazla yüksek oluyor. Geçen ay bir holding sahibinden duyduğum cümle hâlâ aklımda: “Aşkın, biz aylık 50 bin TL bütçeyle AI yapmak istiyoruz, mümkün mü?” Mümkün tabii ama beklentiyi doğru koymanız lazım; bu bütçeyle Nexus gıbı tam ölçekli kurumsal çözüm değil de daha dar bir use case yaparsınız — mesela sadece müşteri hizmetleri için 5 bin SSS dokümanı üzerinden RAG gıbı. Daha fazla bilgi için Kubernetes v1.36 Volume Group Snapshot: Sonunda GA Oldu yazımıza bakabilirsiniz.
Çok konuştum, örnekle göstereyim.
Büyük Şirket mi Küçük Ekip mi?
Bunu netleştirelim çünkü çok karışıyor: cosmos konusundaki yazımız yazımızda bu konuya da değinmiştik. Daha fazla bilgi için GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımıza bakabilirsiniz.
- Startup veya küçük ekipseniz: Hemen Cosmos DB’ye koşmayın derim. Önce pgvector ya da Azure AI Search ile başlayın. 100K doküman altındaysanız bunlar fazlasıyla yeterli olabilir; Cosmos DB’nın gerçek değeri ölçek büyüyünce ortaya çıkıyor.
- Mid-market (50-500 kişilik): Cosmos DB serverless + Azure OpenAI ile başlayın. Document ingestion için Azure Functions kullanın. Maliyet aylık $500-2000 bandında tutulabiliyor.
- Enterprise (1000+): Multi-region Cosmos DB, dedicated throughput ve Azure AI Foundry orkestrasyonu düşünün; ayrıca Foundry Hosted Agents: MAF Ajanını Production’a Almak‘ta anlattığım gıbı agent altyapısını da planlayın demek isterim. AVASOFT Nexus tam olarak bu seviyeye hitap ediyor.
Sahada Bir RAG Pipeline’ı Nasıl Görünüyor?
Lafı gevelemeden söyleyeyim; geçtiğimiz yıl Logosoft’ta bir bankacılık projesinde buna benzer yapı kurduk. Tam Nexus seviyesinde değildi ama mimarı desen aynıydı (kendi tecrübem). Akış kabaca şöyleydi:
// 1.
Dokuman geldi
(event-driven)
Blob Storage ->
Event Grid ->
Azure Function
//
2
Chunking + embedding
Function:
— PDF parse
(Document Intelligence)
—
800 token chunks
,
100 overlap
— Azure OpenAI text-
embedding-
3-large
//
3
Cosmos
DB'
ye yaz
container.upsert({
id:
chunkId,
documentId:
docId,
content:
text,
vector:
embedding,
//
3072 boyut
metadata:
{ source,
page,
dept,
lastUpdated }
})
//
4.
Sorgu zamanı
SELECT TOP 10 c.content,
VectorDistance(c.vector,
@queryVec) AS score
FROM c WHERE c.metadata.dept = @userDept ORDER BY VectorDistance(c.vector,
@queryVec)
İnanın, Bunun sade hâli bu. Production’da işin içine reranking, hybrid search (
BM25 + vector)
,
guardrails,
logging ve evaluation pipeline’
ı da giriyor.
Ama özü burada.
Bir de açık söyleyeyim:
ilk kurulumda VectorDistance fonksiyonunu yanlış indexleyip
4 saniye süren query’
lerle uğraşmıştım.
Çözüm neydi?
Container’
da vector index policy’
sını düzgün tanımlamak.
Default ayarlar production için yetmiyor;
mutlaka quantizedFlat
veya diskANN
seçin,
brute force bırakmayın.
“Neden Sonuçlar Saçma Geliyor?” Diye Soranlara…
retrieval kalitesi çoğu zaman modelden değil, chunking stratejisinden geliyor.
Maliyet Tarafını TL Bazında Konuşalım mı?
En sevdiğim konu bu. Çünkü herkes “bulut pahalı” diyor (yanlış duymadınız). Hesap yapan az.
AVASOFT Nexus benzeri kurumsal yapı için kaba tahminim şöyle; orta ölçekli,
500 kullanıcı,
1 milyon döküman üzerinden:
- Cosmos DB (
provisioned,
20K RU/s,
multi-region
2 bölge)
: ~$1,
400/ay — bunu es geçmeyin - Azure OpenAI (
embedding +
chat,
ortalama kullanım)
: ~$2,
200/ay - Document Intelligence: ~$600/ay
- Azure Functions +
Storage +
diğerleri: ~$300/ay - Toplam: ~$4,
500/ay yanı aylık
150-
160 bin TL bandı
500 kullanıcı için kişi başı yaklaşık
300 TL/ay yapıyor. Bunu tasarruf edilen çalışan saatiyle karşılaştırın;
bir kurumsal avukatın saatlik ücreti
2000-
3000 TL bandında olabiliyor. Eğer GenAI sistemi avukatların ayda
5 saatini kurtarıyorsa ROI gayet pozitif çıkıyor. Ben bu hesabı yaparken hep temkinli gidiyorum;
gerçekte tasarruf daha fazla olabiliyor, şaşırdığım öldü açıkçası.
Peki Ne Eksik? Eleştirel Bakış Burada Başlıyor.
Şimdi sadece övgü düzmek istemiyorum.
AVASOFT sunumu iyiydi. Dürüst olayım;
bütün GenAI projelerinde olduğu gıbı bazı sorular hâlâ havada duruyor.
Açıkçası,
Birinçisi:
Evaluation.
Production’
da modelin doğru çalıştığını nasıl ölçeceksiniz?
Bu konuda Copilot Agent Evaluations:
Ajan Kalitesini Ölçen CLI Geldi
yazımda bahsetmiştim. Sektör hâlâ standart framework’e oturmuş değil;
her ekip kendi metric setini yazıyor.
İkincisi:
Hallüsinasyon.
RAG bunu azaltıyor. Bitirmiyor.
En çok da uzun bağlamlı sorularda hâlâ tahmini cevaplarla karşılaşıyorum.
Kurumsal müşteride “yanlış cevap = hukukî sorun”
senaryosu varsa risk ciddileşiyor.
Dürüst olmak gerekirse,
Üçüncüsü:
Region eksikliği.
Türkiye’de operasyon yapan ve veriyi yurt dışına çıkaramayan müşteriler için Cosmos DB hâlâ tam ideal sayılmaz.
Frankfurt ya da Amsterdam ile idare etmek zorundayız.
Bunu daha önce Azure Avrupa Yatırımları:
Egemen Bulut ve AI Yarışı
yazımda tartışmıştım. Bu konuyla ilgili Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımıza da göz atmanızı tavsiye ederim.
Peki İlk Otuz Günde Ne Yapılır?
İlginç olan şu ki, Eğer bu yazıyı okuyup “Tamam ben de yapayım” diyorsanız somut adımlar şöyle:
- Hafta
1: Use case’i daraltın.”Tüm dokümanlarımız” yerine “X departmanının Y süreci”.
100-
500 doküman bandında POC scope’u belirleyin. - Hafta
2: Azure Cosmos DB serverless açın,
küçük container ile başlayın.
Azure OpenAI’da text-
embedding-
3-large modeline access alın. - Hafta
3: İlk RAG pipeline’ını Python ile yazın (
LangChain veya Semantic Kernel —
tercih sizin)
.
Evaluation için
50 soruluk test set hazırlayın. - Hafta
4: Kullanıcı testleri yapın.
5-
10 gerçek kullanıcıya açıp geri bildirim toplayın.
Chunking ve retrieval tarafını iterasyonla düzeltin.
Bundan sonra production kararını verirsiniz (inanın bana). POC’tan production’a geçiş ayrı konu; orada Cosmos DB’nın provisioned throughput, multi-region replication. Indexing policy detaylarını gerçekten tasarlamanız gerekiyor.
Sıkça Sorulan Sorular
Azure Cosmos DB vector search mi, Azure AI Search mi kullanmalıyım?
Veriniz zaten Cosmos DB’de duruyorsa ya da hem transactional hem AI workload’u aynı anda koşturuyorsanız, Cosmos DB mantıklı. Ama aslında sadece semantic search yeterliyse ve NoSQL’e girmek istemiyorsanız, hibrit ranking (yanı BM25 + vector bir arada) da önemliyse Azure AI Search çok daha pratik bir seçenek. Bence bazı projelerde her ikisini birden kullanmak da gayet makul oluyor.
DiskANN ne zaman HNSW’den daha iyi çalışıyor?
Embedding sayısı gerçekten büyüdüğünde, mesela 10M+’ı geçtiğinde. RAM maliyeti sızı korkutmaya başladığında DiskANN devreye giriyor. HNSW her şeyi memory’de tuttuğu için hızlı — kendi adıma konuşayım — ama pahalı. 1M’ın altında zaten farkı hissetmiyorsunuz; büyük ölçekte işe DiskANN ciddi tasarruf sağlıyor (en azından benim deneyimim böyle). E peki, sonuç ne öldü? Açıkçası küçük projelerde bu karşılaştırmayı yapmak pek gerekmiyor.
RAG sistemimde hallüsinasyonları nasıl azaltabilirim?
Tecrübeme göre üç şeye odaklanmak gerekiyor. Birinçisi retrieval kalitesini iyileştirin — daha iyi chunking yapın, reranking ekleyin (inanın bana). İkincisi prompt’a “kaynak göstermeden cevap verme” gıbı kısıtlar koyun. Üçüncüsü işe system mesajına “Eğer cevabı kaynaklarda bulamazsan ‘bilmiyorum’ de” talimatını ekleyin. Bu üçü bir araya gelince hallüsinasyon oranı gerçekten ciddi şekilde düşüyor.
İşte tam da bu noktada devreye giriyor.
Cosmos DB vector search Türkçe içerikte iyi çalışıyor mu?
Cosmos DB’nın kendisi dil agnostik, yanı bu tarafta sorun yok. Asıl mesele hangı embedding modelini kullandığınız. text-embedding-3-large Türkçe’de fena değil ama mükemmel de sayılmaz. Bizim deneyimimizde domain-specific terimler içeren Türkçe metinlerde retrieval kalitesi İngilizce’ye kıyasla %10-15 civarında düşüyor. Bunu kapatmak için hybrid search ve domain glossary kullanmak oldukça iyi sonuç veriyor.
AVASOFT Nexus gıbı bir çözümü kendim kurmak yerine partner’dan almak ne zaman mantıklı?
İç ekibinizde 2-3 AI mühendisi yoksa, partner çözümü çok daha hızlı ve daha az riskli. Kendi kurarsanız hani 6-9 ay sürebiliyor; partner’la çalışırsanız 6-8 hafta içinde production’a alabiliyorsunuz. Bence mutlaka şu karşılaştırmayı yapın: dahili ekip maaşı vs partner fee. Çoğu mid-market müşteride partner çözümü ilk 2 yılda daha ekonomik çıkıyor.
Kaynaklar ve İleri Okuma
Şöyle söyleyeyim, Scalable AI with Azure Cosmos DB: AVASOFT Süper Insight (Microsoft DevBlogs)
Azure Cosmos DB Vector Search Resmî Dokümantasyonu
Şöyle ki, Cosmos DB for NoSQL: DiskANN. Vector Index Policy Detayları
Azure Samples: Cosmos DB NoSQL Copilot Reference Architecture (GitHub)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.