Açık konuşayım: Bankacılıkta “müşteriyi 360 derece görmek” lafını en az 15 yıldır duyuyoruz. Ben ilk kez duyduğumda, sanırım 2010’larda, bir GTB projesinin içindeydik; herkes aynı cümleyi kuruyordu, ama kimse o resmî tam toplayamıyordu. Peki neden? Çünkü veri bir yerde core banking’de duruyordu, bir yerde CRM’de, başka bir yerde kart platformunda, kalan parçalar da Excel’e sıkışmıştı (evet, hâlâ tutan var, inanın bana).
Bugün işler biraz daha iyi. Ama hâlâ tam oturmuş değil. Geçen ay bir katılım bankasının veri ekibiyle konuşurken aynı cümleyi yine duydum: “Müşteri çağrı merkezini aradığında temsilcimiz dört farklı ekrana bakıyor, hâlâ tam resmî göremiyor.” İşte tam bu noktada Azure DocumentDB (MongoDB uyumlu) gibi document-oriented veritabanları devreye giriyor. Bu yazıda neden bu yaklaşımın bankacılık için anlamlı olduğunu, nerede tıkanabildiğini ve Türkiye tarafında nasıl bir yol izlenebileceğini anlatacağım.
Customer 360 Neden Bu Kadar Zor Bir Konu?
İlginç olan şu ki, Bir bankayı gözünüzde canlandırın. Müşteri sabah mobil uygulamadan kredi kartı limitine bakıyor, öğlen şubeye uğrayıp konut kredisi soruyor, akşam çağrı merkezini arayıp fatura ödüyor, gece de chatbot’a bir şey soruyor. Beş kanal var gibi görünüyor, ama arkada işleyen sistem sayısı çok daha fazla. Hepsi aynı kişi. Karışıklık buradan başlıyor.
Ve işler burada ilginçleşiyor.
Sorun şu: Bu sistemlerin çoğu 90’larda ya da 2000’lerde tasarlandı (ki bu çoğu kişinin gözünden kaçıyor). O zamanın mantığı “her departman kendi sistemini kursun” üzerineydi. Şimdi bunları tek resimde toplamaya çalışıyoruz. Kolay mı? Değil. Yapılamaz mı? Hayır, yapılabiliyor.
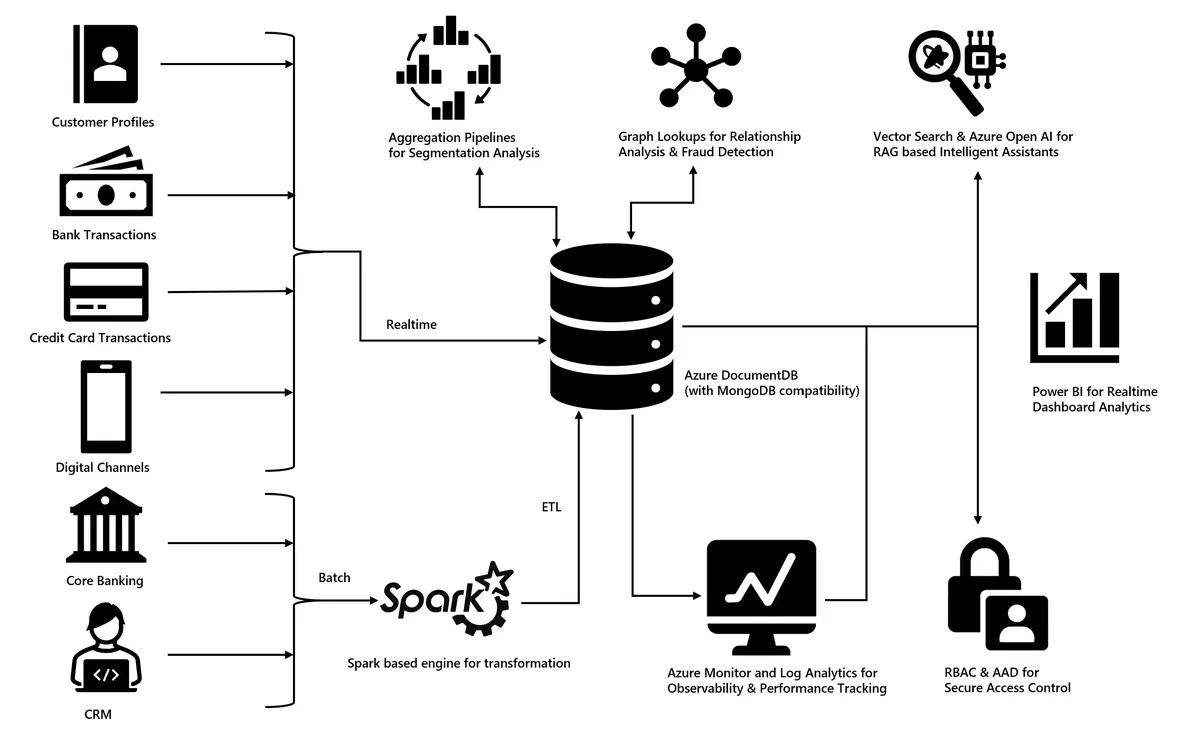
Klasik yaklaşım ne oluyor? Data warehouse kurarsın, ETL ile her yerden veri çekersin, gece toplu iş çalışır, sabah raporlar hazır ölür. Güzel tarafı var, ama bir eksiği de bariz: gerçek zamanlı değil (kendi tecrübem). Müşteri şu anda telefondaysa, 12 saat önceki veriyle hareket etmek pek işe yaramıyor.
“Müşterinin son 30 saniyede ne yaptığını bilmiyorsanız, 360 derecelik görüşünüz aslında 359 derece. Eksik kalan o 1 derece, çoğu zaman en can alıcı olanıdır.”
Document Database Yaklaşımı: Neden Mantıklı?
Bankacılıkta veri yapısı ilk bakışta tablolara uygun gibi duruyor, ama işin içine girince çeşitlilik şaşırtıyor. Bir müşterinin profili; temel bilgiler, hesaplar (1 tane mi var 30 tane mi belli değil), kartlar, krediler, mevduatlar, son işlemler, tercihler, izinler (KVKK tarafı burada bayağı önemli), risk skorları. Segmentler derken uzayıp gidiyor. Bunu klasik relational şemaya sıkıştırmaya kalkarsanız ortaya 40-50 tablolu bir yapı çıkıyor. Sonra kimse bunun içinde rahat yürüyemiyor.
Şimdi gelelim işin can alıcı noktasına.
Document database tarafında işe her müşteri tek bir JSON belgesi gibi düşünülebiliyor. Tek sorguda ihtiyacınız olan parçaları alıyorsunuz. Hız fena değil. Esneklik de baya iş görüyor.
Azure DocumentDB Nedir, MongoDB ile İlişkisi?
İnanın, Burada karışmasın diye net söyleyeyim: Azure DocumentDB, MongoDB protokolüyle uyumlu çalışan Microsoft’un yönetilen veritabanı servisi olarak konumlanıyor. Yani siz MongoDB driver’larıyla ve MongoDB sorgularıyla yazıyorsunuz; arkada Azure’un ölçeklenebilir, yedekli ve güvenli altyapısı dönüyor. Mongo Atlas’a alternatif diye düşünebilirsiniz; ama Azure ekosisteminde yaşıyorsanız entegrasyon tarafı ciddi rahatlık sağlıyor.
Bu arada Cosmos DB tarafıyla karıştıranlar oluyor — bu konuda daha önce yazdığım Cosmos DB Azure RBAC Entegrasyonu: Iki Dünya Birleşti yazısına da göz atabilirsiniz; kimlik yönetimi tarafında işleri epey kolaylaştırıyor.
Pratikte Nasıl Bir Veri Modeli?
Bakın, Bir müşteri belgesi şöyle görünebilir. Aşağıdaki örnek gerçek bir bankada uyguladığımız modelin sadeleştirilmiş hâli:
{
"_id": "TCKN_HASH_a8f3...",
"musteriNo": "10245678",
"kimlik": {
"adSoyad": "Ahmet Yılmaz",
"dogumTarihi": "1985-03-12",
"segment": "AFFLUENT",
"musteriOlmaTarihi": "2014-06-22"
},
"iletisim": {
"telefon": "+90...",
"email": "...",
"izinler": {
"sms": true,
"email": false,
"arama": true,
"güncelleme": "2025-09-14"
}
},
"hesaplar": [
{ "iban": "TR...", "tip": "VADESIZ", "bakiye": 45200.50, "paraBirimi": "TRY" },
{ "iban": "TR...", "tip": "VADELI", "bakiye": 250000, "vade": "2026-03-15" }
],
"kartlar": [...],
"krediler": [...],
"sonEtkilesimler": [
{ "kanal": "MOBIL", "aksiyon": "LOGIN", "zaman": "2025-11-20T08:14:22Z" },
{ "kanal": "CAGRI_MERKEZI", "aksiyon": "LIMIT_SORGU", 'zaman': '...' }
],
'riskSkoru': 720,
'nextBestAction': 'KONUT_KREDISI_ONERI'
}
Bu yapının güzel yani şu: Çağrı merkezî temsilcisi müşteri bağlandığında tek bir sorgu atıyor. Her şeyi alıyor. Bekleme süresi azalıyor; JOIN cehennemi de ortadan kalkıyor diyebilirim. Aggregation Pipeline ile istediğiniz boyutta veri türetebiliyorsunuz zaten.
$graphLookup ile İlişkisel Bağlantılar
Şunu söyleyeyim, Bankacılıkta en sevdiğim araçlardan biri bu diyebilirim. Bir müşterinin eşi kimmiş, çocuğu kimmiş, ortağı kimmiş — bunları fraud ekibi için toplamak altın değerinde oluyor. $graphLookup operatörüyle “şu hesabın bağlı olduğu tüm hesapları üç derece derinliğe kadar getir” gibi sorgular yapabiliyorsunuz. Geçen yıl bir müşteride şüpheli para hareketi tespit ederken bunu kullandık; normalde manuel araştırma iki gün sürerdi (hatta biraz daha uzardı), biz dört saniyede sonucu gördük. Abartmıyorum. Bu konuyla ilgili GPT-5.2 ve GPT-5.2-Codex Emekli Oluyor: Geçiş Notları yazımıza da göz atmanızı tavsiye ederim.
Peki neden?
Türkiye’deki Bankacılık Sektörü Açısından Değerlendirme
Şimdi gelin biraz yerel bağlamdan konuşalım; çünkü Türkiye’de tablo biraz farklı ilerliyor.
Birinçisi, BDDK ve KVKK regülasyonları nedeniyle veri lokasyonu can alıcı konu oluyor. Azure’un Türkiye’de henüz region’ı yok (bu konu sürekli değişebiliyor; siz bu yazıyı okurken durum farklı olabilir). Bu yüzden çoğu banka Batı Avrupa ya da Kuzey Avrupa region’larını kullanıyor. Gecikme tarafında bu size yaklaşık 35-50ms ekstra latency getiriyor. Mobil uygulamada çok hissedilmiyor; ama yüksek frekanslı işlemlerde planlama gerekiyor. Bu konuyla ilgili Teams SDK Python Desteği GA: Pythoncular İçin Yeni Kapı yazımıza da göz atmanızı tavsiye ederim.
Dürüst olmak gerekirse, İkinci nokta şu: Türkiye’de bankacılık sektörü baya dijital ilerliyor. Mobil bankacılık penetrasyonu Avrupa ortalamasının üstünde bile diyebiliriz bazen. Bu da Customer 360 işini zorlaştırıyor; çünkü müşteri verisi çok hızlı üretiliyor. Saniyede binlerce işlem görmek sıradan hâle geldi.
Üçüncüsü ve bence önemli kısmı şu: Türkiye’deki büyük bankaların çoğu hâlâ mainframe + Oracle ağırlıklı çalışıyor. “Bütün veriyi DocumentDB’ye taşıyalım” demek gerçekçi olmaz; hatta biraz aceleci durur. Onun yerine hibrit yaklaşım daha mantıklı geliyor: Master data kaynak sistemde kalsın ama Customer 360 katmanı için DocumentDB üzerinde denormalize bir görünüm oluşturulsun ve Change Data Capture (CDC) ile senkron tutulsun. Bu konuyla ilgili .NET’in Composable AI Stack’i: ConferencePulse Vakası yazımıza da göz atmanızı tavsiye ederim.
Maliyet: Açık Konuşalım
Bu kısmı atlayan teknik yazılardan ben de hoşlanmıyorum açıkçası. Maliyeti konuşmadan mimarı önermek biraz fiyatına bakmadan araba almak gibi kalıyor. Bu konuyla ilgili Azure konusundaki yazımız yazımıza da göz atmanızı tavsiye ederim.
Evet, doğru duydunuz.
Bence, Azure DocumentDB fiyatlandırması iki ana eksende ilerliyor: compute (vCore tabanlı) ve storage. Basitçe söylemek gerekirse valla iş görüyor. Hesap kitap yapmak şarttır; kesin rakamlar için yine Azure pricing calculator’a bakmanızı öneririm tabi ki:
| Senaryo | Tahmini Aylık Maliyet | Kullanım |
|---|---|---|
| Küçük banka / fintech (200K müşteri) | $800 — $1.500 | 2x M40 cluster, ~500GB |
| Orta ölçek (2M müşteri) | $4.000 — $7.000 | 3x M60, ~3TB, replikasyon |
| Büyük banka (10M+ müşteri) | $20.000+ | Çoklu region, sharded cluster |
TL bazında düşündüğünüzde orta ölçek bir banka için yıllık kabaca 1.5-2 milyon TL bandından söz ediyoruz diyebilirim; bu sadece DocumentDB tarafı için geçerli tabii ki. Ekosistemin tamamını — Event Hubs, Functions, Synapse ve benzerlerini — eklediğinizde rakam büyüyor ister istemez. Maliyet iyileştirmeu konusunda yazdığım Cosmos DB Maliyet Optimizasyonu: AI Yüklerinde 7 Taktık yazısındaki taktiklerin çoğu burada da işe yarıyor; özellikle TTL ve indeks stratejisi baya fark ettiriyor.
Startup mı, Enterprise mı?
Eğer fintech startup’ıysanız ve Customer 360 yapmak istiyorsanız küçük başlayın. Tek collection, basit aggregation pipeline’lar yeterli oluyor. M30-M40 cluster çoğu durumda fazlasıyla yetiyor. Premature optimization yapmayın; müşteri sayınız gerçekten büyüyene kadar beklemek daha mantıklı.
Ama büyük kurumsal bir bankaysanız ilk günden mimariyi doğru kurmanız gerekiyor. Sharding stratejisi (ben genelde musteriNo hash’i öneriyorum), region replikasyonu, zone redundancy, RBAC, audit logging — bunların hepsi başlangıçta düşünülmeli (en azından benim deneyimim böyle). Sonradan değiştirmek açık konuşayım korkunç pahalıya çıkabiliyor.
Vector Search ve AI Tarafı: İşin Yeni Boyutu
Sıradaki kısım beni son bir yıldır en çok heyecanlandıran alanlardan biri oldu. DocumentDB’de native vector search artık var. Bu ne demek?
Müşterinin geçmiş davranışlarını embedding’e çeviriyorsunuz, vector index’liyorsunuz. Sonra “bu müşteriye benzer profile sahip yüz müşteri kim” gibi sorguları milisaniyelerde alabiliyorsunuz. Cross-sell modellerinde baya etkili olabiliyor. RAG mimarisi kurmak isteyenler için langchain-azure-cosmosdb: Tek Veritabanıyla Agent. RAG yazımdaki pattern’lar burada da uygulanabilir. Entra Agent ID GA: Sponsor Grup Tipi Kısıtlaması Geldi yazımızda bu konuya da değinmiştik.
Bir bakıma, geçen ay bir katılım bankasında bunu denedik. Müşteri çağrı merkezini aradığında bot konuşmayı transkript ediyor, embedding alıyor, benzer geçmiş aramaları buluyor — temsilciye “bu müşterinin sorunu büyük ihtimalle X, geçmişte Y çözümü işe yaradı” diye öneri sunuyor. İlk testlerde çağrı süresi %22 düşmüştü. Kalıcı oldu mu? Emin değilim; hâlâ test fazındayız ama umut verici görünüyor (bu konuda ikircikliyim).
Peki Nereden Başlamalı?
Tamam, ikna oldunuz diyelim. Customer 360’ı DocumentDB üstünde kurmak istiyorsunuz. O zaman benim önerim adım adım gitmeniz yönünde:
- Kapsamı daraltın:“Tüm müşteri verisini birleştirelim” yerine “çağrı merkezî 360’ı” gibi spesifik bir use case seçin. Üç ayda canlıya çıkacak kadar dar olsun.
- Veri modelini önce kağıt üstünde çizin:Hangi attribute’lar embed edilecek, hangileri reference olacak? Document size için16MB sınırını unutmayın.
Source sistemlerden DocumentDB’ye veri akışını sağlayın. Event Hubs + Stream Analytics iyi kombinasyon oluyor. - Yanlış index = yavaş sorgu + yüksek maliyet. Compound index’leri ihmal etmeyin.
- BDDK denetiminde “kim ne zaman ne sorguladı” sorusuna cevap verebilmeniz lazım.
- Tek consumer ile başlayın:Önce sadece çağrı merkezî entegre olsun. Sonra mobil, sonra fraud. Big bang yapmayın.
Bu adımları AZ-305 sınavına çalışırken aklımda tuttuğum mimarı prensiplerle birlikte düşününce, çoğu projede dört ila altı ay içinde anlamlı bir Customer A360 MVP’si çıkarabiliyoruz tabii; yönetim desteği varsa. Bu ne anlama geliyor? Yönetim desteği yoksa hiçbir şey çıkmıyor zaten, o ayrı mesele.
Eksik Yanlar ve Dikkat Edilmesi Gerekenler
Sadece iyi yanlarını anlatsam doğru olmaz; açıkçası eksikleri de var:
- Schema discipline gerekiyor:“Schema-less” diye gevşek bırakırsanız altı ay sonra kimse veriyi anlayamıyor.
Schema validation kullanın. - Karmaşık analitik için yetersiz kalabiliyor:“Son beş yılın aylık ortalama bakiye trendi” gibi sorgular için Synapse/Databricks daha uygun oluyor.
DocumentDB OLTP odaklıdır; OLAP işi ona kalınca zorluyor.
— bunu es geçmeyin - Yedekleme ve geri dönüş stratejisi:Document yapısı bozulursa restore edersiniz; ama referential integrity yoktur.
Test ortamında senaryolarınızı mutlaka deneyin. - BDDK denetiminde “neden NoSQL” sorusu:Hâlâ bazı denetçiler ilişkisel veritabanına alışkın olabiliyor.
Doküman yapınızı, ACID garantilerini ve güvenlik kontrollerinizi açıklayabilecek dokümantasyon hazırlayın.
Küçük bir detay: B ir de şunu söyleyeyim — kağıt üstünde her şey sakın duruyor ama production’da ilk üç ay mutlaka sorun çıkıyor.
Bağlantı pool ayarları, retry policy’leri, throttling — hepsi elle tutulup ayarlanması gereken şeyler.
Bir telekomda gördüğüm vakayı paylaşayım: bağlantı pool size default bırakılmıştı, peak saatte tüm uygulama timeout’a düştü;
iki günlük debug sonrası sebep bu çıktı.
Böyle şeyler her zaman başınıza gelebiliyor,
o yüzden ilk günlerden itibaren gözünüz açık olsun.
Sıkça Sorulan Sorular
Azure DocumentDB ile Cosmos DB for MongoDB aynı şey mi?
Doğrusu, Tam olarak değil, ama hani kardeş sayılırlar. Cosmos DB for MongoDB, Cosmos DB’nın MongoDB API’si sunan versiyonu yani. Azure DocumentDB işe daha yeni, vCore tabanlı ve daha “saf MongoDB” hissi veren bir seçenek — aslında mevcut MongoDB uygulamalarını taşıyacaksanız DocumentDB (vCore) çok daha kolay geçiş sağlıyor. Hangisi sizin için doğru? Workload’unuza bakarak karar verin.
Mevcut Oracle tabanlı core banking sistemimi söküp atmam mı gerekiyor?
Eh, Hayır, kesinlikle hayır. Customer 360 katmanı, mevcut sistemlerinizin üstüne oturan, okuma odaklı bir katman. Oracle’da hesap işlemleri kendi hayatına devam ediyor, DocumentDB tarafında işe bu verilerin denormalize, sorguya optimize edilmiş bir kopyası tutuluyor. CDC ile de senkronu sağlıyorsunuz zaten.
BDDK denetimleri açısından bu mimarı uygun mu?
Doğru kurulduğunda evet. Dikkat etmeniz gerekenler şunlar: veri lokasyonu (Avrupa region’ları genelde kabul görüyor), şifreleme (at-rest. In-transit), audit logging, kimlik doğrulama (Entra ID entegrasyonu) ve veri sınıflandırması. Açıkçası bunları düzgün belgelendirdiğiniz sürece sorun çıkmıyor — bence en hayatı adım da zaten belgelendirme, hiçbir projede sıkıntı yaşamadım bu konuda.
Latency hassas işlemler için yeterli mi?
Customer 360 gibi okuma ağırlıklı senaryolar için fazlasıyla yeterli. Tek dijit milisaniye okuma süreleri zaten normal sayılıyor. Ama yüksek frekanslı trading veya saniyede on binlerce yazma gibi uç senaryolarda mimariyi daha dikkatli kurgulamak gerekiyor — o noktada sharding. Indeks stratejisi kritik hâle geliyor, mesela bunu atlayınca işler sarpa sarıyor.
İlk POC’yi ne kadar bütçeyle yapabilirim?
Yani, Küçük bir POC için aylık 500-800 dolar yeterli aslında. M30 tier bir cluster, birkaç GB veri, basit bir dashboard — 4-6 hafta içinde anlamlı bir demo çıkarabilirsiniz. Tecrübeme göre kurum içi onay almak için de bu bütçe genelde yeterli geliyor. Production’a geçerken tabi rakam katlanıyor, ama ilk adım için düşünülmüş bir miktar.
Kaynaklar ve İleri Okuma
Şahsen, Azure Cosmos DB for MongoDB Resmî Dokümantasyonu — Microsoft’un kendi dokümantasyonu, başlangıç için en iyi yer.
Azure Cosmos DB DevBlog — Bu yazıya da ilham veren orijinal kaynağın olduğu blog. Banking ve FSI senaryoları için düzenli içerik geliyor.
MongoDB Aggregation Pipeline Dokümantasyonu — DocumentDB MongoDB uyumlu olduğu için tüm aggregation operatörleri buradan öğrenilebilir. $graphLookup, $facet gibi operatörler özellikle Customer 360 için altın değerinde.
Son söz olarak: Customer 360 bir teknoloji projesi değil, bir kültür projesi. Bankanızda departmanlar veriyi paylaşmıyorsa, dünyanin en iyi DocumentDB cluster’ını kursanız da işe yaramıyor. Önce insanları, sonra süreçleri, en son teknolojiyi düşünün. Bu sırayla ilerleyenler kazanıyor — tersine gidenler 3 yıl sonra hâlâ “POC aşamasında” oluyor. İnanın, çok gördüm.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.