Geçen ay MVP Summit videolarını izlerken karşıma çıktı,.NET ekibi sahnede “ConferencePulse” diye bir uygulama gösteriyordu — canlı bir konferans asistanı. İlk bakışta sıradan bir demo sandım. Ama biraz kurcalayınca iş değişti: adamlar, anlattıkları teknolojinin kendisiyle, anlattıkları oturumu yönetiyorlardı. Slayt yoktu yani; kendi yazdıkları framework’ün çalışan hâli sahnedeydi.
Açık konuşayım, ben de yıllardır.NET tarafında AI entegrasyonu yapmaya çalışan biri olarak bu işe baya sıcak baktım. Çünkü bizim derdin adı belli: bir LLM provider seçiyorsun, üç ay sonra başka yere geçmek istiyorsun, hop kodun yarısı elinde kalıyor. Vector DB değiştirmek istiyorsun, bu kez ingestion pipeline’ı baştan toparlıyorsun (ve o an insanın canı sıkılıyor, hani) (ciddiyim). İşte burada Microsoft’un “composable building blocks” yaklaşımı devreye giriyor; kulağa süslü geliyor ama sahada fena da durmuyor (yanlış duymadınız)
Bu yazıda hem ConferencePulse’ın mimarisini kendi gözümden anlatacağım, hem de Türkiye’deki kurumsal projelerde bu yapı taşlarını gerçekten kullanmak isteyenler için pratik bir yol haritası çıkarmaya çalışacağım. Birebir Microsoft blog yazısının çevirisini bekliyorsanız, yanlış yerdesiniz. Ben kendi notlarımı paylaşıyorum. Evet.
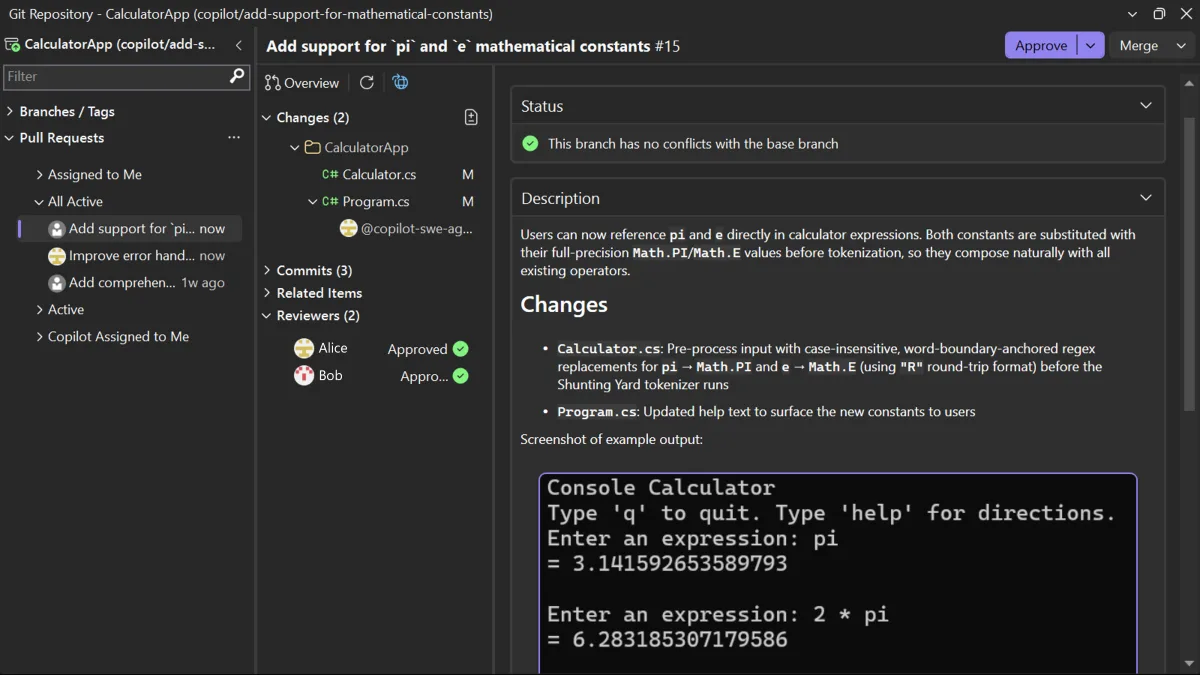
ConferencePulse Tam Olarak Ne Yapıyor?
Açık konuşayım, Kısaca anlatayım. Katılımcı QR kodu okutup oturuma giriyor, sonra sistem sessizce arkada dönmeye başlıyor; oturumun içeriğine göre canlı anketler üretiyor, izleyiciden gelen soruları RAG pipeline’ı üzerinden yanitlıyor, anket sonuçlarından çıkarım yapıyor. Oturum biter bitmez birden fazla AI agent’ını paralel çalıştırıp özet hazırlıyor.
Açık konuşayım, Güzel tarafı şu: hazırlık neredeyse yok gibi. Bir GitHub repo’su gösteriyorsunuz, sistem markdown dosyalarını çekiyor, ingestion pipeline’ından geçiriyor ve onları aranabilir bir knowledge base’e çeviriyor; sonrası baya otomatik ilerliyor, yani anketler de konuşma noktaları da Q&A cevapları da bu içerikten besleniyor.
Şimdi gelelim işin can alıcı noktasına.
Stack tarafı işe şöyle:
- .NET 10 + Blazor Server — UI ve orkestrasyon (bu kritik)
- Aspire — Qdrant, PostgreSQL ve Azure OpenAI servislerini bir araya getiriyor
- Microsoft.Extensions.AI — provider-agnostik AI abstraction’ı
- Microsoft.Extensions.DataIngestion — pipeline tabanlı veri işleme — ciddi fark yaratıyor
- Microsoft.Extensions.VectorData — vector store soyutlaması
- Model Context Protocol (MCP) — tool ve context paylaşımı
- Microsoft Agent Framework — multi-agent workflow
Proje yapısı da çok kalabalık değil aslında. Web, Core, Ingestion, Agents, Mcp, AppHost diye 5-6 klasör var; Aspire AppHost bunların hepsini ayağa kaldıran orkestratör rolünde duruyor. Neyse, çok uzatmayayım, şimdi tek tek parçalarına bakalım.
Evet.
Microsoft.Extensions.AI: Tek Arayüz, Bütün Provider’lar
Bi saniye — IChatClient arayüzü, olayın tam merkezinde duruyor. OpenAI, Azure OpenAI, Ollama, Foundry Local… fark etmiyor, hepsi aynı kapıdan geçiyor; hani bazen bir şey bu kadar sade olunca insan “acaba fazla mi basit?” diye düşünüyor ama işin aslı tam tersi oluyor.
Bunun ne kadar işe yaradığını anlamak için küçük bir hikâye anlatayım. Geçen yıl Logosoft’ta bir sigorta şirketinde POC yapıyorduk. Başlangıçta Azure OpenAI ile ilerledik. Uc hafta sonra müşterinin compliance ekibi geldi ve “veri yurtdisina çıkmasın” dedi. Mecburen Ollama’ya döndük. O sırada SemanticKernel kullanıyorduk ve provider değişikliği baya can yaktı — yaklaşık dört günümüz gitti; yani ufak bir ayar değil, bildiğin mini proje oldu.
Şimdi Microsoft.Extensions.AI ile aynı senaryoda 1-2 saatlik is kalıyor. Connection string’i değiştiriyorsun, model adını değiştiriyorsun, bitti gibi. Evet, bu kadar basit geliyor kulağa; tabii gerçek hayatta yine test var, ufak uyum sorunları var, bir de “bu model neden böyle cevap verdi?” sorusu var. Ana değişim çok daha hafif kalıyor.
Dürüst olmak gerekirse, Asıl hoşuma giden kısım middleware pipeline tarafı. Logging, telemetry, function calling, caching… hepsi delegating handler mantığıyla zincire ekleniyor; yani yapının içine tek tek girip her şeyi yeniden yazmıyorsun, daha çok mevcut akışa ufak katmanlar ekliyorsun. Bak şimdi orası önemli.
Kısa bir not düşeyim buraya.
builder.Services.AddChatClient(sp =>
{
var openai = new AzureOpenAIClient(endpoint, credential)
.GetChatClient(deploymentName)
.AsIChatClient();
return new ChatClientBuilder(openai)
.UseLogging()
.UseOpenTelemetry()
.UseFunctionInvocation()
.UseDistributedCache(cache)
.Build();
});Bu kod parçası benim için ayrıca anlamlı çünkü ASP.NET middleware desenini tanıyan herkes burada hemen tanıdık bir his alıyor. Yeni bir şey ogrenmiyorsun aslında; bildiğin şeyi başka bir alana taşıyorsun. Hani bazen framework değişir ama kafa yapısı aynı kalır ya, işte tam o durum. Microsoft’un burada iyi bir tercih yaptığını düşünüyorum.
Bir abstraction’ın değeri, önü değiştirmek istediğin gün ortaya çıkıyor.
IChatClienttam da bu sınavdan geçiyor.
Microsoft.Extensions.DataIngestion: Pipeline Mantığıyla Veri
İngestion tarafı, açık konuşayım, framework’ün en çok toparlanmaya ihtiyacı olan kısmı gibi duruyor. Hani daha preview aşamasında ama yön fena değil; veriyi reader’lar okuyor, processor’lar çeviriyor, writer’lar da hedefe bırakıyor (ASP.NET pipeline mantığını bilen biri için zaten yabancı gelmiyor).
ConferencePulse örneğinde GitHub markdown dosyalarını çekiyor, chunking yapıyor, embedding üretiyor ve Qdrant’a basıyor. Bu ne anlama geliyor? Bu işi elle yazmak — inanın bana — Türkiye’deki çoğu projede aynı döngüye giriyor; bir ekip chunker yazıyor, öteki ekip önü biraz değiştiriyor, sonra üç ay sonra herkes birbirine bakıp “bu niye dağıldı” diye soruyor.
Evet.
Pratik Bir Karşılaştırma
Aşağıdaki tablo, RAG pipeline’larında kendi kodunu yazmakla bu hazır bileşenleri kullanmak arasındaki farkı bence gayet net gösteriyor — kendi gözlemlerimden söylüyorum; ilk kurulumda günler gidiyor ya da yarım güne düşüyor, chunk stratejisini değiştirmek bazen refactor eziyetine dönüşüyor ya da tek satır config ile çözülüyor, yeni format eklemek için parser yazıyorsun ya da sadece reader takıyorsun.
| Konu | Elle Yazınca | DataIngestion ile |
|---|---|---|
| İlk kurulum süresi | 3-5 gün | Yarım gün |
| Chunk strategy değişikliği | Kod refactor | Tek satır config |
| Yeni format desteği (PDF, DOCX) | Yeni parser yaz | Reader ekle |
| Vector DB değişikliği | Acı | Provider swap |
| Test edilebilirlik | Zor | Her aşama mockable |
Neyse, çok dağıttım. DataIngestion tarafında işin güzel yani var ama bir de kırılgan tarafı var; çünkü hâlâ preview ve breaking change yeme ihtimali yüksek. Ben şu an production’da kullanmıyorum, hani gönül rahatlığıyla “bunu direkt canlıya basın” diyemem (ilk duyduğumda inanamadım). Pilot projede denersin, beklersin, sonra karar verirsin; biraz temkinli gitmek burada daha mantıklı. Bu konuyla ilgili Kubernetes v1.36 Controller Staleness: Artık Daha Az Acı yazımıza da göz atmanızı tavsiye ederim.
Maalesef.
İnanın, Daha açık söyleyeyim, peki neden? Çünkü bu tıp altyapılarda asıl mesele sadece çalışması değil, sürpriz çıkarmaması. Şey gibi düşünün; bugün iyi çalışan bir ingestion hattı yarın ufak bir update sonrası farklı davranabiliyor, o yüzden önce küçük bir senaryoda sınamak baya iş görüyor. Bu konuyla ilgili VS 2026 Insiders 3’te TypeScript 7 Beta: 10x Hız Geldi yazımıza da göz atmanızı tavsiye ederim.
VectorData: Qdrant, Cosmos, Postgres — Hepsi Aynı Arayüz
Burası bence işin en hayatı tarafı. Bizde vector DB seçimi çoğunlukla teknik bir tartışmadan çok, ticarî bir yöne kayıyor. Müşterinin Azure aboneliği varsa — en azından ben öyle düşünüyorum — Cosmos DB Vector Search’e gidiyorsun. PostgreSQL hazır duruyorsa pgvector kullanıyorsun. Self-hosted istiyorsa Qdrant geliyor. VectorStore abstraction’i sayesinde de üç senaryoda kod neredeyse aynı kalıyor. Güzel taraf bu.
Bazı yerlerde is ilk bakışta temiz görünüyor, ama dür bir saniye — pratikte karar genelde kısa bir toplantıda veriliyor, sonra herkes entegrasyon tarafında nefesini tutuyor; geçen ay bir e-ticaret müşterisiyle tam böyle oldu, önce Qdrant ile POC yaptık, sonra müşteri Cosmos’a geçmek istedi (Microsoft sertifikasyon avantajı yüzünden), migration da bir günde bitti. Eskiden bu is bir haftayı rahat görürdü. Cosmos DB tarafında ek detaylar için Cosmos DB Azure RBAC Entegrasyonu: Iki Dünya Birlesit yazıma da göz atabilirsiniz.
Peki neden?
MCP: Tool’ları Standartlaştırmak
İşin garibi, Model Context Protocol, son bir yılın en sessiz işlerinden biri bence. Anthropıc çıkardı, Microsoft da hızlıca sahiplendi. İşin özü basit: AI modellerine tool vermek için ortak bir protokol var artık. Eskiden her framework kendi tool mantığını ayrı ayrı kuruyordu, şimdi tablo biraz değişti. Evet.
ConferencePulse tarafında bir MCP server var, bu server da poll oluşturma, audience insight çıkarma gibi tool’ları dışarı açıyor. Aynı tool’lar hem uygulamanın içinde kullanılıyor hem de — istersen — Claude Desktop ya da GitHub Copilot tarafından çağrılabiliyor; yani tek tek entegrasyon kovalamak yerine, tool setini bir yerde toparlayıp farklı AI agent’larına dağıtma fikri baya iş görüyor, ama tabii burada yönetim tarafı da hafif kafa yoruyor. Peki neden? Çünkü şirketler zamanla kendi tool çevreini kurup bunu farklı yüzlere sunmaya başlayacak gibi duruyor. Daha fazla bilgi için azd Nisan 2026: Multi-Language Hooks ve Sessiz Devrim yazımıza bakabilirsiniz.
Bu arada Azure MCP Server.mcpb Paketi: Runtime Derdine Veda yazımda paketleme kısmına da girmiştim, ilgilenen varsa oraya da bir göz atabilir. Neyse uzatmayalım.
Microsoft Agent Framework: Multi-Agent Işin Eğlenceli Tarafı
Burada, oturum biter bitmez devreye giren o özet mekanizması var ya, ConferencePulse’in en gösterişli kısmı bence tam orası. Dört agent yan yana çalışıyor; biri anketlere bakıyor, biri soruları ayıklayıp duruyor, biri insight topluyor, diğeri de hepsini bir araya getirip final özeti çıkartıyor. Sequential yaparsanız 30+ saniye gidiyor, paralel akinca 8-10 saniyeye düşüyor. Fena değil. Bu konuyla ilgili Azure Cosmos DB Conf 2026: Notlarım, İzlenimlerim ve yazımıza da göz atmanızı tavsiye ederim.
Evet.
Türkiye’deki Kurumsal Yapislar Için Notum
Bak şimdi, açık konuşayım: multi-agent mimarileri Türkiye’de hâlâ biraz erken sayılıyor. Çoğu müşterimde tek bir RAG pipeline’i bile zor onay alıyor, “bir sürü agent paralel konuşacak” dediğinizde compliance ekibi ister istemez geriliyor; cost predictability, audit trail ve error handling tarafları da agent sayısı artınca tuhaf şekilde daha uğraştırıcı hâle geliyor. Hani teknik olarak yapılır, ama işin operasyonu başka dert.
Benim önerim su: Eğer bir startup ya da küçük bir ekipseniz, Agent Framework ile doğrudan multi-agent tarafa geçin, çünkü hız ve çeviklik bayağı iş görüyor (ki bu çoğu kişinin gözünden kaçıyor). Ama büyük kurumsal taraftaysanız, önce tek-agent’li bir RAG ile başlayın, bunu 6 ay üretimde tutun, sonra ikinci agent’i ekleyin; yoksa ilk haftada her şey güzel görünür ama sonraki ay loglar, izinler ve hata senaryoları kafa karıştırır (inanın bana). Tahmin eder mısınız? Bu konuda detay lazımsa Microsoft Agent Framework’te Chat History: Nerede yazımdaki state management kısmına da bir bakın derim. Kubernetes v1.36: Pod-Level In-Place Resize Beta’da yazımızda bu konuya da değinmiştik.
İlginç olan şu ki, Peki neden?
Aspire: Yapıştırıcı Görevini Hakkıyla Yapıyor
Aspire olmasa bu mimariyi iki dakikada göstermek zor olurdu (inanın bana). Qdrant container’ını kaldır, PostgreSQL’i ayağa al, Azure OpenAI bağlantısını ekle, sonra bunları Blazor Server uygulamasına bağla; Aspire bunu birkaç satır C# ile toparlıyor, yani işin en sıkıcı kısmını üstünden alıyor.
var builder = DistributedApplication.CreateBuilder(args);
var qdrant = builder.AddQdrant("qdrant").WithDataVolume();
var postgres = builder.AddPostgres("pg").WithPgAdmin();
var openai = builder.AddConnectionString("openai");
builder.AddProject<Projects.ConferenceAssistant_Web>("web")
.WithReference(qdrant)
.WithReference(postgres)
.WithReference(openai);
builder.Build().Run();İşte, dürüst olmak gerekirse, Bunu ilk denediğimde, açık konuşayım, Docker Compose dosyalarını çöpe atma fikri aklımdan geçti. Tam atmadım tabii — production tarafında hâlâ Compose. Helm chart kullanıyorum çünkü — ama development ortamında Aspire bence net şekilde öne geçti. Evet, biraz iddialı duruyor.
Maliyet Tarafı: TL Bazında Gerçekçi Bakış
Şimdi en sevmediğim yere geldik: para. Bu mimariyi Türkiye’de kurunca ne çıkar, işin aslı bu. Kabaca bir hesap yapalım, Kasım 2024 fiyatlarıyla ve orta ölçekli bir kullanım senaryosuyla konuşursak:
- Azure OpenAI (GPT-4o): Aylık 800-1500 USD (orta seviye kullanım)
- Embeddings (text-embedding-3-small): 50-100 USD
- Qdrant self-hosted (Standard_D4s_v3): 130 USD
- PostgreSQL Flexible Server: 90 USD
- App Service / Container Apps: 100-200 USD
Toplamda, ortalama bir konferans ya da etkinlik asistanı için aylık 1200-2000 USD bandı çıkıyor. TL’ye vurunca rakam göze batıyor, — kendi adıma konuşayım — evet, ama enterprise tarafta bu seviye çoğu zaman korkutucu değil; hatta bazı projelerde gayet normal kalıyor. Peki neden? Çünkü yükü doğru dağıtırsanız, o fatura bir anda şişmiyor.
- Embedding’i lokal modelle yapın (BGE veya E5), sadece chat için Azure OpenAI kullanın
- Distributed cache’i agresif kullanın — aynı sorulara aynı cevap
- GPT-4o-mini ile başlayın, sadece zor query’ler için 4o’ya yükseltin (router pattern)
- Vector DB’de quantization açın — bellek %75 düşüyor
Bak şimdi, burada küçük ama etkili bir oyun var: her şeyi buluta yıkmak yerine bazı parçaları içeride tutarsanız maliyet baya toparlıyor. Az önce dediğim şey önemliydi. Aslında — hayır dür, daha doğrusu daha kritik nokta şu; trafik desenini iyi okumazsanız en ucuz servis bile gereksiz pahalıya dönebiliyor. Neyse, çok dağıtmayayım, konumuza dönelim.
Peki neden?
Bu tarafta Cosmos DB Maliyet Optimizasyonu: AI Yüklerinde 7 Taktık yazımda daha detaylı taktikler var, ilgisi olan bakabilir. Şey, orada özellikle cache ve veri erişim tarafında iş gören birkaç pratik örnek de paylaştım; hani teoride güzel duran şeyler değil, sahada gerçekten işe yarayan türden.
Evet.
Karşılaştığım Bir Hata ve Çözümü
Bakın, Bu yapıyı kendi makinemde denerken bir yerde tökezledim. UseFunctionInvocation() middleware’ını ekleyince tool çağrıları sessiz sedasız patlıyordu; ne bir hata vardı, ne de düzgün bir log, yani ortada “neden olmadı şimdi bu?” dedirten garip bir sessizlik kalıyordu. Yarım gün debug ettim, baya uğraştırdı. Sonunda taşlar yerine oturdu: FunctionInvokingChatClient‘ın varsayılan MaximumIterationsPerRequest değeri 10’muş ve benim agent tam 12. iterasyona çıkıyordu.
Bence, Evet, mesele buydu. Settings tarafında bu değeri artırınca her şey normale döndü, ama açık konuşayım, ilk bakışta insan bunu pek yakalayamıyor; çünkü davranış bozuk gibi duruyor, oysa aslında sadece limitte takılıyor.
Bu çok küçük bir detay gibi görünüyor. Ama yeni başlayanların kafasını fena karıştırabiliyor. Microsoft.Extensions.AI dokümantasyonunda bu varsayılanlar bence biraz gölgede kalmış; hani “nasıl olsa anlaşılır” denmiş gibi duruyor ama pratikte öyle olmuyor, çünkü siz tool zincirine güveniyorsunuz, sistem işe sessizce frene basıyor.
İlk uyarım şu: ChatOptions‘ı detaylıca tanıyın. Şey, üstünkörü geçmeyin; özellikle iteration limitleri, middleware sırası ve client davranışı gibi noktalar bazen işi tamamen değiştiriyor. Siz de böyle bir şey yaşadınız mı?
Hangi Senaryoda Bu Stack’e Geçmeli?
Ne yalan söyleyeyim, Tarafsız olmaya çalışacağım. Bu mimarı her projeye uymaz.
Uyduğu yerler: Birden fazla AI provider’ı denemek isteyen, vendor lock-in’den kaçınan, multi-agent senaryolarına gidecek,.NET ekosistemine sadık takımlar. Microsoft Learn dokümantasyonu, GitHub içerikleri gibi kurumsal knowledge base’leri RAG’a çevirmek isteyen projeler için de fena durmuyor; hatta doğru kurgulanırsa baya iş görüyor.
Uymadığı yerler: Çok hızlı POC çıkarmak isteyen ekiplerde biraz ağır kalabilir, Python tarafına. Yakın duran data science grupları için de açık konuşayım daha tanıdık seçenekler var. LangChain veya LlamaIndex daha hazır komponentler sunuyor —. Oranın kendi dertleri de ayrı, önü başka bir yazıda açarım.
Sıkça Sorulan Sorular
Microsoft.Extensions.AI production-ready mi?
Garip gelecek ama, Çekirdek paket — hani IChatClient, IEmbeddingGenerator. Middleware altyapısı — evet, GA durumunda ve ben de kendi projelerimde aktif olarak kullanıyorum. Ama DataIngestion ve bazı yan paketler hâlâ preview aşamasında. Bu ne anlama geliyor? Açıkçası, production’a almadan önce paketin sürüm durumunu NuGet’ten bir kontrol edin, sonradan sürprizle karşılaşmayın.
SemanticKernel ile Microsoft.Extensions.AI arasında ne fark var?
SemanticKernel daha üst seviye, yani size “şöyle yap, böyle yap” diyen opinionated bir framework. Microsoft.Extensions.AI işe daha alt seviyede, abstraction odaklı çalışıyor. Aslında ikisi birbirine rakip değil — tamamlayıcılar. Yeni Agent Framework de zaten SemanticKernel’in yerini alacak ve Microsoft.Extensions.AI üzerine inşa ediliyor.
MCP olmadan da bu mimarı kurulur mu?
Tabi ki kurulur. MCP, mesela tool’ları farklı AI client’larıyla paylaşmak istediğinizde işe yarıyor. Tek uygulama içinde kalacaksanız doğrudan function calling gayet yeterli. Bence MCP’yi “ilerisi için bir seçenek” olarak düşünmek daha mantıklı.
Türkiye’de bu stack’e geçen şirketler var mı?
Logosoft müşteri portföyümde 2024 sonu itibarıyla 3 kurumsal müşteri Microsoft.Extensions.AI tabanlı RAG kurdu. Hepsi şu an pilot aşamasında — production trafiği henüz düşük (kendi tecrübem). Tecrübeme göre önümüzdeki yıl ciddi bir adoption dalgası geliyor, özellikle.NET’e yatırım yapmış finans ve telekom tarafında (evet, doğru duydunuz)
Aspire olmadan bu projeyi build edebilir mıyım?
Edebilirsiniz, ama development experience’ı bayağı düşüyor açıkçası. Docker Compose ile aynı ortamı kurabilirsiniz — sadece Aspire’ın service discovery, dashboard. Telemetry entegrasyonundan mahrum kalırsınız. Küçük projeler için Compose yeterli, bence sorun olmaz.
Kaynaklar ve İleri Okuma
Şöyle ki, Building an AI-Powered Conference App with.NET’s Composable AI Stack — Microsoft DevBlogs
Microsoft.Extensions.AI Resmî Dokümantasyonu
Şöyle söyleyeyim, .NET AI Samples GitHub Reposu
Model Context Protocol Spesifikasyonu

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar

Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.