Şahsen, Geçen ay bir sigorta şirketinin AI ekibiyle Teams’te uzun bir toplantı yaptık. Konu basitti aslında: kullanıcı bir agent’a soru soruyor, ertesi gün geri dönüyor, “dün konuştuğumuz şey neydi?” diyor. Cevap: bilmiyoruz. Çünkü kimse oturup şunu sormamış — bu konuşma tam olarak nerede duruyor?
İşin garibi şu, herkes model seçmekten, prompt yazmaktan, tool çağırmaktan saatlerce bahsediyor; ama “chat history nerede yaşıyor?” sorusu çoğu zaman en sona kalıyor, halbuki mimaride asıl can sıkan karar bazen tam da orası oluyor. Evet. Bir de sonra dönüp log arıyorsun, iz sürüyorsun, ama elinde düzgün bir kayıt yoksa iş uzuyor.
Açık konuşayım, Microsoft Agent Framework bu konuda baya ilginç bir yol seçmiş. Hem service-managed hem de client-managed pattern’leri tek bir abstraction altında topluyor; yani işin özü, konuşmanın hafızasını sen mi tutacaksın yoksa servis mi tutacak, bunu en başta netleştirmen gerekiyor (ve açık konuşayım, kurumsal projelerde en çok kavga da burada çıkıyor). Bugün bu iki yaklaşımı, Türkiye’deki kurumsal projelerde hangisinin ne zaman tercih edildiğini ve benim sahada gördüğüm tuzakları konuşacağız.
Önce Şu Soruyu Doğru Soralım
İşin garibi, Bir agent yazıyorsunuz. Kullanıcı “X konusunu özetle” diyor. Sonra bir bakıyorsunuz, “try again” yazmış. Ardından iki cevabı yan yana kurcalıyor, hatta ertesi sabah dönüp “dün başladığımız sohbete devam et” diyebiliyor.
Dürüst olmak gerekirse, İşin can alıcı kısmı şu: Bu deneyim olacak mı, olmayacak mı, çoğu zaman tek bir mimarı karara takılıyor: conversation state nerede tutuluyor?
Bu kararın etkisi de tek yönlü değil. Maliyet bir anda değişiyor (her request’te full history mi yolluyorsun, yoksa sadece bir ID mi?), privacy tarafı ayrı dert (KVKK ve sektörel kurallar işin içine girince tablo hemen sertleşiyor), portability de cabası — yarın OpenAI’dan Anthropıc’e ya da Azure OpenAI’dan başka bir modele geçmek istediğinde state’i nasıl taşıyacaksın? Bir de UX var tabii; konuşmayı düz bir liste gibi mi tutuyorsun, thread gibi mi görüyorsun, yoksa branch edebilen bir ağaç gibi mi kurguluyorsun?
“Model seçimi 1 haftada değişebilir, prompt’u her gün iyileştirebilirsin. Ama chat storage mimarisini production’a aldıktan sonra geri çevirmek — bu ciddi iş. Ben buna ‘sessiz lock-in’ diyorum.”
İki Temel Pattern: Service-Managed vs Client-Managed
Agent Framework tarafına bakınca, işin omurgasında iki yaklaşım var. Üçüncü bir sihirli yol yok; hibrit dediğimiz şey de çoğu zaman bu ikisinin biraz karışmış hâli,. Bazen servis konuşuyor, bazen sen araya giriyorsun, bazen de ikisi birlikte işi yürütüyor.
Bunu biraz açayım.
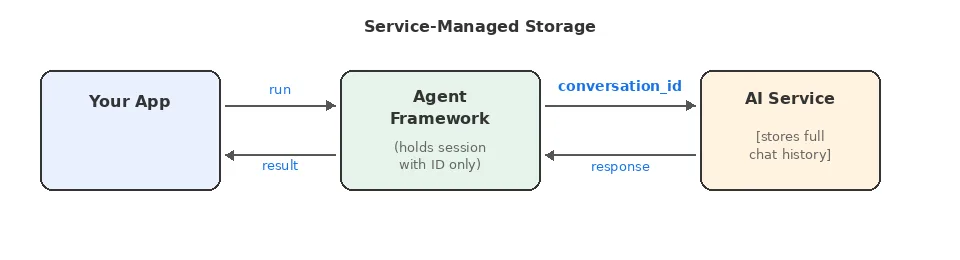
Service-Managed Storage
Burada konuşma state’ını AI servisinin kendisi tutuyor. Sen Agent Framework içinde sadece bir referans saklıyorsun — mesela conversation_id ya da thread_id. Yeni mesaj gelince, aynı ID ile birlikte o yeni mesajı yolluyorsun; servis de geçmişi kendi tarafında toparlayıp modele veriyor. Kısacası yükün önemli kısmı dışarıda kalıyor, sen daha çok takıp edici roldesin.
OpenAI’ın Assistants API’si, Azure AI Agent Service (ki bu çoğu kişinin gözünden kaçıyor). Anthropıc’in bazı conversation endpoint’leri bu mantıkla çalışıyor. Hatta iş biraz daha ileri gitti; Responses API de benzer yaklaşımı resmî olarak getiriyor. Şey, ilk bakışta kulağa rahat geliyor ama her rahatlık da bedava değil, önü da unutmamak lazım.
Kısa bir not düşeyim buraya.
Client-Managed Storage
Bu modelde top tamamen sende. Agent Framework, AgentSession içinde ya da bağladığın history provider’larda neredeyse tüm conversation’ı tutuyor. Her request’te ilgili mesajları paketleyip servise gönderiyorsun; servis stateless kalıyor, yani işlem yapıyor, cevabı dönüyor ve sonra unutuyor. Basit gibi duruyor, ama kontrol hissi baya yüksek oluyor.
Klasik Chat Completions API kullandığın senaryolar tam bu kategoriye giriyor. Açık konuşayım, ben uzun yıllar bu modelle çalıştım ve hâlâ çoğu kurumsal projede ilk baktığım yer burası oluyor. Evet, biraz daha uğraştırıyor; ama loglama, denetim ve veri akışı kontrolü tarafında elini rahatlatıyor.
Yan Yana Karşılaştırma
Toplantılarda whiteboard’a çizmekten yoruldum. En sonunda şu tabloyu hazırladım, çünkü müşteriye anlatırken baya iş görüyor; bir bakışta fark çıkıyor, ama işin içinde küçük bir sürü detay da var, onları atlayınca tablo güzel görünüyor diye yanlış sonuca kayabiliyorsunuz.
| Kriter | Service-Managed | Client-Managed | ||
|---|---|---|---|---|
| İmplementasyon karmaşıklığı | Düşük | Orta-Yüksek | ||
| Veri lokasyonu kontrolü | Sınırlı | Tam kontrol | ||
| Provider taşıma kolaylığı | Zor (state migration gerekli) | Kolay | ||
| Context window yönetimi | Servis halleder | Sen yazacaksın | ||
| Compaction stratejisi | Black box | İstediğin gibi | ||
| Request payload boyutu | Küçük (sadece ID) | Büyüyebilir | ||
| KVKK/regülasyon uygunluğu | Provider’a bağlı | Kolayca uyumlanır | ||
| Branch/fork desteği | Provider’a bağlı | Tam esnek |
Evet, ilk bakışta client-managed daha cazip duruyor. Peki neden? Çünkü “tam kontrol” kulağa hoş geliyor, insanın içini rahatlatıyor; ama dür bir saniye, o kontrolün yaninda yük de geliyor. Bu yük bazen beklediğinizden ağır oluyor. Context window’u sen yöneteceksin, token sayımını sen takıp edeceksin, eski mesajları ne zaman summarize edeceğine sen karar vereceksin; yani servis sana sadece kapıyı açmıyor, anahtar da veriyor ama sonra “gerisini sen hallet” deyip kenara çekiliyor. Daha fazla bilgi için agent konusundaki yazımız yazımıza bakabilirsiniz.
Neyse, çok dağıttım. İşin aslı şu: çoğu ekip bu kısmı başta hafife alıyor, sonra production’da compaction davranışı garipleşince veya payload şişince “hmm burada bir şeyleri yanlış okumuşuz” diyor. Tam da öyle.
Sahadan Bir Hikâye: 80K Token Faturası
2024 sonlarında bir e-ticaret müşterimizle çalışıyorduk. Customer support agent’ı kurduk, OpenAI Assistants API üzerine. Service-managed gittik, çünkü hızlı POC istiyorlardı. İlk hafta süperdi. İkinci hafta da fena değildi. Üçüncü haftanın sonunda fatura geldi — beklediğimizin 3 katı. Şaşırdık açıkçası.
Sebebini anlamak için biraz kazdık. Bazı premium müşteriler agent’la günlerce konuşuyordu, thread hiç kapanmıyordu; service tarafı da her request’te 60-80K token’lık history’i modele yolluyordu (biz bunu ekranda net görmüyorduk),. “service halleder” deyip rahat bırakmışız resmen. Compaction stratejisini değiştirme şansımız da yoktu (inanın bana). Kısacası black box, hem de bildiğin kapalı kutu. Daha fazla bilgi için chat konusundaki yazımız yazımıza bakabilirsiniz.
Hani, Çözüm? Hibrit tarafa döndük. Belirli bir token eşiğinin üstüne çıkan thread’leri client-managed tarafa migrate eden bir sliding-window + summarization mekanizması yazdık; maliyet %58 düştü, ama bunun bedeli de vardı, iki hafta ekstra geliştirme yaptık. Ekipte ufak bir “keşke en başta bunu düşünseydik” sessizliği oluştu. Keşke baştan düşünseydik.
Microsoft Agent Framework Bunu Nasıl Soyutluyor?
Burada iş biraz ilginçleşiyor. Agent Framework, iki yaklaşımı da tek bir API yüzeyinde topluyor; AgentThread abstraction’ı üzerinden ilerliyor, servis tarafı thread ID destekliyorsa önü saklıyor, desteklemiyorsa ya da sen özellikle istemiyorsan ChatMessageStore ile lokal history tutuyor. Kulağa temiz geliyor, evet. Ama işin içine provider farkı girince tablo biraz değişiyor.
Evet, doğru duydunuz. Azure Smart Tier GA: Blob Depolamada Otomatik Tasarruf yazımızda bu konuya da değinmiştik.
Yani, Yani teoride şöyle bir şey yazıp, alttaki modeli sonradan değiştirdiğinde uygulamanın aynı şekilde akmasını bekleyebilirsin: (kendi tecrübem) Bu konuyla ilgili GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımıza da göz atmanızı tavsiye ederim.
// Pseudo-kod, gerçek API farklılık gösterebilir
var agent = new ChatClientAgent(chatClient, instructions: "Sen yardımcı bir asistansın.");
var thread = agent.GetNewThread(); // Provider thread'i destekliyorsa server-side, değilse client-side
await foreach (var update in agent.RunStreamingAsync("Merhaba", thread))
{
Console.Write(update);
}
// Aynı thread, sonraki çağrı
await agent.RunAsync("Az önce ne demiştim?", thread);Baya düzgün duruyor. Fakat dür bir saniye — burada ufak — itiraz edebilirsiniz tabi — bir pürüz var: framework aslında ChatClient‘ın ne döndürdüğüne bakıp uygun pattern’i seçiyor, yani bazı yerlerde kontrol sende gibi hissediyorsun ama tam öyle olmuyor; compaction, branching. Persistence gibi davranışlar provider’a göre değişebiliyor. İşte, i̇şin aslı şu: “bir kere yazayım, her yerde aynen çalışsın” fikri fena değil ama pratikte biraz çatlıyor.
Evet.
Bilmem anlatabiliyor muyum, O yüzden ben buna bakınca şunu düşünüyorum: soyutlama iyi, hatta çoğu senaryoda baya iş görüyor. Bu katmanların altında ne olduğunu unutursan sonra küçük sürprizler çıkabiliyor. Siz ne dersiniz?
Türkiye’deki Kurumsal Gerçeklik
Logosoft’ta son 18 ayda 7-8 farklı agent projesinde yer aldım. Bankacılık, sigorta, telekom, kamu… Kısacası tablo net; Türkiye tarafında bu işin kokusu biraz başka geliyor.
Kurumsal müşterilerimde gördüğüm şey şu: Türkiye’de bu teknolojinin benimsenmesinde regülasyon korkusu öne çıkıyor, yani KVKK, BDDK, Bilgi Teknolojileri Kurumu derken iş bir anda teknik olmaktan çıkıp hukuk ve uyum tarafına kayıyor. Bir bankacılık projesinde sadece “konuşma verisi yurt dışındaki bir provider’da tutuluyor” cümlesi bile 3 ay süren bir compliance review’a döndü; service-managed yaklaşım da böyle durumlarda, özellikle sensitive veri olan akışlarda, açık konuşayım, masadan kalkıyor.
Bir de vendor lock-in meselesi var. Evet. Türk şirketlerinde bu travma baya canlı duruyor; ERP geçişleri, eski Oracle anlaşmaları, yarım kalmış dönüşümler… Hepsi aynı yere çıkıyor aslında: state’i mümkünse sen yönet. O yüzden kurumsal mimarlar çoğu zaman client-managed tarafa kayıyor (kontrolü bırakmak istemiyorlar, haklılar da), ama bazen bunu fazla sıkı tutup operasyonu gereksiz ağırlaştırdıklarını da görüyorum.
İşte tam da bu noktada devreye giriyor.
Startup tarafı işe tam tersine çalışıyor. Hızlı çıkmak istiyorlar, MVP’yi ayağa kaldıracaklar, regülasyon dertleri sonra gelsin diyorlar. İşte burada service-managed çoğu zaman daha mantıklı oluyor; CodeAct. Hyperlight: Agent’ları Tek Hamlede Hızlandırmak yazımda da değindiğim gibi, agent ekosisteminde “hızlı çıkmak” ile “doğru çıkmak” arasındaki gerilim her seçimde karşımıza çıkıyor. Şey, bazen hız kazanıyorsun ama kontrol biraz elinden kaçıyor; bazen de tam tersi oluyor (yanlış duymadınız). Proje olduğundan daha ağır ilerliyor. GPT-5.5 GitHub Copilot’ta GA: 7.5x Çarpan Değer mi? yazımızda bu konuya da değinmiştik.
Hangisini Ne Zaman Seçmeli?
Service-Managed Tercih Et Eğer:
- POC ya da MVP aşamasındaysan, hız işi belirliyorsa
- Küçük bir ekipsen ve context yönetimi yazmaya ayıracak vaktin yoksa
- Konuşma verisi sensitive değilse (genel bilgi asistanı, marketing chatbot vs.)
- Provider’a uzun vadeli bağlı kalmayı göze alıyorsan (bu kritik)
- Multi-turn konuşmalar kısa kalıyorsa, yani 10-20 mesajı geçmiyorsa
Client-Managed Tercih Et Eğer:
- Regülatif yükümlülüklerin varsa (finans, sağlık, kamu)
- Maliyeti daha agresif optimize etmen gerekiyorsa
- Custom compaction/summarization stratejisi kuracaksan — bunu es geçmeyin
- Branching (try again, paralel keşif) UX’i tasarlayacaksan (bu kritik)
- Birden fazla model/provider arasında geçiş yapma ihtimalin varsa
- Konuşmaları Cosmos DB, PostgreSQL gibi kendi storage’ında tutmak istiyorsan
Pratik İlk Adımlar
Diyelim yarın bir agent işine gireceksin (evet, doğru duydunuz). Ben olsam önce şuradan başlarım, çünkü ilk gün koddan çok karar toplarsın; veri nerede duracak, kim erişecek, ne kadar saklanacak gibi soruları netleştirmeden ilerlersen sonra geri dönüp duvar kırıyorsun.
- Threat ve compliance modelini netleştir. Veri nerede tutulabilir? Hangi süre boyunca? Bu soruların cevabı yoksa, açık konuşayım, bir satır kod yazmak bile erken kalıyor.
- Konuşma uzunluğu beklentini ölç. Ortalama 5 mesajlık konuşmalar mı olacak, yoksa günler süren thread’ler mi? İkisi de “chat” diye geçiyor ama maliyet tarafında baya farklı davranıyor, yani aynı sepete koyunca şaşırıyorsun. (bu kritik)
- Token telemetrisini günü 1’de kur. Application Insights’a her request’in input/output token’ını logla. POC olsa bile bunu yap, çünkü sonra “neden bu kadar pahalı oldu” sorusuna dönüp bakacak veri bulamıyorsun.
- Storage abstraction’ını körü. Doğrudan Assistants API’ye yapışmak yerine Agent Framework’ün
AgentThread‘ını kullan. Geri dönüş yolun açık kalsın, çünkü bugün iyi gelen seçim yarın ayağına dolaşabiliyor. (bu kritik) - Compaction stratejini erken seç. Sliding window mu, summarization mı, hibrit mi? Bak şimdi, bunu production’a bırakınca işler karışıyor; en iyisi daha baştan test edip hangisinin senin senaryoda idare ettiğini görmek.
Neyse, biraz dağıldım ama konu tam da burada toparlanıyor — bence çok yerinde bir karar —. Agent altyapısının diğer parçaları için Azure MCP Server.mcpb Paketi: Runtime Derdine Veda. Azure Developer CLI ve Copilot: Terminalde AI Dönemi yazılarıma da bakabilirsin — özellikle deployment ve tool entegrasyonu tarafında iş görür, hatta bazı noktalarda beklediğimden daha pratik çıkmıştı (kendi tecrübem)
Kısa bir not düşeyim buraya.
Eksik Bulduğum Şey
Kısacası, açık konuşayım, Microsoft Agent Framework’ün şu anki hâlinde benim gözüme batan bir eksik var: built-in compaction stratejileri henüz tam oturmamış. Yani client-managed modda çalışırken, “30 mesajdan eskileri özetle, son 10’unu aynen bırak” gibi bir pattern’i kendin kuruyorsun; bu da hani ilk bakışta basit duruyor ama iş pratiğe gelince biraz el oyalıyor. Kağıt üstünde fena değil, hatta baya umut veriyor, ama pratikte biraz daha pişmesi lazım.
Bence bu yine de doğru tarafa atılmış bir adım. Ama dür bir saniye — eksik tarafı da var (buna dikkat edin). Önümüzdeki 6 ay içinde bu boşlukların kapanmasını bekliyorum, tabii %100 garanti diyemem; ben olsam şimdiden kendi IChatMessageStore implementasyonunu yazmaya hazırlanırım. Peki bunu neden söylüyorum? Evet.
Sıkça Sorulan Sorular
Service-managed kullanırken konuşma verisi nereye gidiyor?
Bu tamamen hangi provider’ı seçtiğine bağlı aslında. Azure OpenAI Assistants kullanıyorsan veri, seçtiğin Azure region’ında kalıyor. OpenAI’ın direkt API’siyle gidiyorsan ABD sunucularına düşüyor. KVKK’ya tabi bir uygulama yapıyorsan, bence Azure OpenAI’ın Türkiye ya da Avrupa region’larını tercih etmek çok daha güvenli bir başlangıç noktası. Yine de hukuk ekibinizle bir teyit edin, kesin konuşmak zor.
İki pattern’i aynı uygulamada birlikte kullanabilir mıyım?
Teknik olarak neredeyse kesinlikle evet — hani yukarıda anlattığım e-ticaret örneğinde tam olarak bunu yaptık zaten. Kısa ve hafif konuşmaları service-managed’da bırakıp, belirli bir eşiği geçenleri client-managed’a taşıyabilirsin. Ama açıkçası bu hibrit yaklaşım ciddi karmaşıklık getiriyor. Ekip olarak henüz olgunlaşmadıysanız, en baştan tek bir pattern’e odaklanmak çok daha sağlıklı (şaşırtıcı ama gerçek)
Context window dolduğunda ne oluyor?
Service-managed’da provider kendi compaction’ını uyguluyor. Genelde eski mesajları düşürüyor ya da özetliyor, ama detayları sana söylemiyor. Client-managed’da işe sorumluluk tamamen sende — ya hata alırsın ya da senin yazdığın mantık devreye giriyor (ki bu çoğu kişinin gözünden kaçıyor). Bu yüzden token sayımını ve eşik mantığını en erken aşamada yazmak şart, sonradan uğraşmak çok daha meşakkatli oluyor tecrübeme göre.
Branching (try again) UX’i için hangisi daha uygun?
Client-managed kesinlikle daha esnek burada (evet, doğru duydunuz). Konuşma ağacının state’ını kendi data modelinde tutabiliyorsun, yani bir node’dan iki farklı dala rahatça gidebilirsin. Service-managed’da bu çoğu zaman ya hiç desteklenmiyor ya da provider’a özgü kısıtlı API’lerle sınırlı kalıyor. Siz ne dersiniz? ChatGPT benzeri bir UX hedefliyorsan, bence client-managed gitmek çok daha mantıklı.
Maliyet açısından hangisi daha avantajlı?
Net bir cevap yok açıkçası, kullanım profiline göre değişiyor. Mesela kısa konuşmalarda (5-10 mesaj) fark neredeyse yok. Uzun thread’lerde işe client-managed öne çıkıyor — compaction’ı sıkı tutarsan modele gönderilen token miktarını agresif şekilde kontrol edebiliyorsun. Service-managed’da işe tüm history’i modele verip vermeme kararını provider’a bırakmak zorundasın, bu da maliyeti tahmin etmeyi zorlaştırıyor.
Kaynaklar ve İleri Okuma
Chat History Storage Patterns in Microsoft Agent Framework — Wes Steyn (Microsoft DevBlogs)
Microsoft Agent Framework Resmî Dokümantasyonu (şaşırtıcı ama gerçek)
Araya gireyim: Azure OpenAI Assistants API Konsept Dokümanı
Microsoft Agent Framework GitHub Repository

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.