Bence, Açık konuşayım: Bu özelliğin GA olmasını epey zamandır bekliyordum. v1.27’de Alpha olarak çıktığında, müşterilerden gelen “Bunu production’a alabilir mıyız?” sorularına hep aynı cevabı veriyordum: “Henüz değil, biraz pişsin.” Aradan neredeyse iki buçuk yıl geçti, iki kere Beta türü gördü, ve nihayet v1.36 ile Volume Group Snapshot Generally Available statüsüne geldi.
Peki neden bu kadar önemli? Kısa cevap şu: Gerçek dünyadaki uygulamalar tek volume’dan ibaret değil. Bir veritabanını düşünün — data dosyaları bir diskte, transaction log başka bir diskte, belki tempdb ya da WAL ayrı yerde duruyor. Bunları tek tek snapshot’layınca restore sonrası elinize tutarsız bir küme geçiyor. Ve evet, bu gece 3’te insanı yataktan kaldıran türden bir dert.
Şimdi gelelim işin can alıcı noktasına.
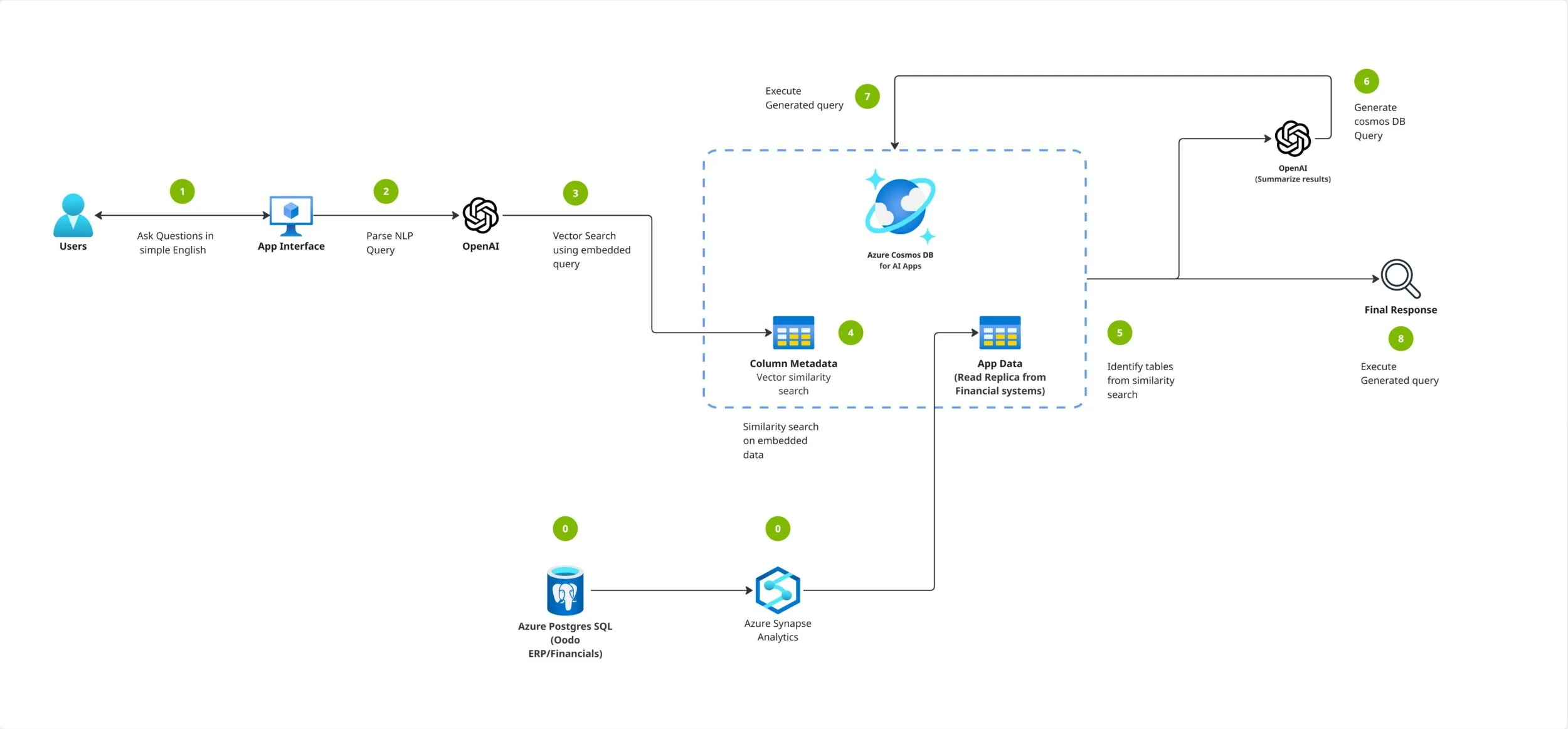
Nedir bu Volume Group Snapshot, neyi çözüyor?
İnanın, Kubernetes’te zaten VolumeSnapshot API’si vardı. Tek bir PersistentVolumeClaim’in anlık fotoğrafını alıyor, gerektiğinde geri dönüyordunuz. Sorun yoktu. Ama işin rengi burada değişiyor: Uygulamanız birden fazla volume kullanıyorsa — ki kurumsal tarafta bu hiç de nadir değil — snapshot’ları aynı anda almak zorundasınız.
“Aynı anda” derken birkaç saniyelik yakınlıktan bahsetmiyorum. Disk seviyesinde write order consistency lazım oluyor. A diskine yazılan transaction’ın B diskinde de aynı mantıksal noktada görünmesi gerekiyor (aksi hâlde restore sonrası veritabanı size ters ters bakıyor). Yoksa corruption kapıyı çalıyor, hem de hiç nazik davranmadan.
Eski yöntem neydi? Uygulamayı quiesce ediyordunuz, yanı I/O’yu kısa süreliğine donduruyordunuz; sonra tek tek snapshot alıp tekrar serbest bırakıyordunuz (yanlış duymadınız). Küçük sistemlerde idare ediyor. Ama 50 TB’lık bir Oracle ya da PostgreSQL cluster’ında uygulamayı 30 saniye dondurmak? Hmm, açık söyleyeyim, müşteri pek hoş karşılamıyor.
Group snapshot’ın can alıcı noktası şu: Uygulamayı durdurmadan storage seviyesinde crash-consistent bir nokta yakalıyorsunuz. Restore ettiğinizde sistem sanki elektrik gitmiş gıbı açılıyor — modern veritabanları da zaten tam böyle senaryolara hazırlanıyor.
Üç temel API: VolumeGroupSnapshot ailesi
Yapı CSI tarafında üç ana kaynak üstüne kuruluyor (en azından benim deneyimim böyle). İlk bakışta kafa karıştırabiliyor ama mantık aslında VolumeSnapshot ile aynı; sadece işin ölçeği grup seviyesine çıkmış durumda.
- VolumeGroupSnapshot: Kullanıcının ya da backup operatörünün yarattığı istek nesnesi. “Şu label’a sahip PVC’lerin grup snapshot’ını al” diyorsunuz.
- VolumeGroupSnapshotContent: Snapshot controller’ın oluşturduğu ve gerçek storage kaynağına bağlanan nesne. PV ile PVC arasındaki ilişkiyi düşünün; mantık çok benzer.
- VolumeGroupSnapshotClass: StorageClass’ın snapshot karşılığı gıbı düşünebilirsiniz. Hangı CSI driver kullanılacak, hangı parametreler geçecek, deletion policy ne olacak — bunlar burada belirleniyor.
Hangı PVC’lerin gruba gireceğine label selector ile karar veriyorsunuz. Esnek tarafı güzel ama dikkat edin: Yanlış selector yazarsanız istemediğiniz volume’lar da snapshot’a girer. Geçen sene bir e-ticaret müşterisinde tam olarak bu öldü — selector biraz fazla geniş kalmıştı ve snapshot job’ı 8 TB yerine 24 TB veriyle uğraşmaya kalktı (fatura kısmını söylemeyeyim, moral bozar).
Basit bir örnek manifesto
apiVersion: groupsnapshot.storage.k8s.io/v1beta1
kind: VolumeGroupSnapshotClass
metadata:
name: postgres-group-snapclass
driver: disk.csi.azure.com
deletionPolicy: Retain
---
apiVersion: groupsnapshot.storage.k8s.io/v1beta1
kind: VolumeGroupSnapshot
metadata:
name: postgres-prod-snap-20260108
namespace: db-prod
spec:
volumeGroupSnapshotClassName: postgres-group-snapclass
source:
selector:
matchLabels:
app: postgres-prod
backup-group: primary-clusterBurada backup-group: primary-cluster etiketi kritik rol oynuyor. PVC oluştururken bunu eklemeyi unutursanız snapshot o volume’u sessizce atlar; log’da bağırmaz bile, sadece eksik yedekle baş başa kalırsınız.
Ve işler burada ilginçleşiyor. kubernetes konusundaki yazımız yazımızda bu konuya da değinmiştik.
Gerçek hayattan: Bir bankacılık projesinden notlar
2024 sonunda Logosoft olarak orta ölçekli bir bankada AKS üzerinde çalışan core uygulamanın disaster recovery mimarisini elden geçirdik. Uygulama PostgreSQL üstündeydi; ana data volume’u dört TB’tı, WAL volume’u ayrı 800 GB’tı ve bir de archive volume’u vardı (üçü birlikte tutarlı olmazsa RPO hedefi kâğıt üstünde kalıyor).
O sırada Volume Group Snapshot Beta aşamasındaydı. Müşterinin compliance ekibi “Beta feature production’a giremez” dedi; biz de Velero + custom hooks ile uygulama seviyesinde quiesce yaparak ilerledik. Çalışıyordu ama snapshot penceresinde uygulama yaklaşık 12-15 saniye yavaşlıyordu — şimdi geriye dönüp bakınca fena çözüm değildi ama yine de içimize tam sinmemişti.
Nihayet GA olunca geçen ay aynı müşteriyle mimariyi yeniden ele aldık ve tablo değişti; artık o pencere neredeyse görünmeyecek kadar küçük kaldı (evet, doğru duydunuz)
Şuna dikkat: başka bir şey daha var:
Bu kabiliyetin sadece CSI driver destekliyorsa, çalışıyor.
In-tree volume plugin’de yok, FlexVolume’da yok.
Azure Disk CSI, AWS EBS CSI veya GCE PD CSI gıbı modern driver’larda sorun yaşamazsınız. Eski cluster hâlâ in-tree provisioner kullanıyorsa önce CSI migration yapmanız gerekir. Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımızda bu konuya da değinmiştik.
Türkiye’deki kurumsal manzara kim ne yapacak?
Açık konuşayım; Türkiye’de Kubernetes kullanımı hâlâ çoğunlukla stateless workload tarafında yoğunlaşıyor.
Frontend’, API gateway’, mikroservis… bunlarda volume snapshot konusu zaten gündeme bile gelmiyor.
Ama son 18 ayda net bir eğilim gördüm:
Veritabanları da Kubernetes’e taşınmaya başladı.
Bilhassa CloudNativePG (ciddiyim). Zalando gıbı PostgreSQL operatörleriyle işler hızlandı. Daha fazla bilgi için Copilot Studio .NET 10’a Geçti: WebAssembly’de Hız Devrimi yazımıza bakabilirsiniz.
Neyse ki burada Volume Group Snapshot baya iş görüyor.
Bir CloudNativePG cluster’ında primary’nın data ve WAL volume’larını grup hâlinde snapshot alabilirseniz point-in-time recovery senaryolarınız daha temiz hâle geliyor (eskiden pgBackRest gıbı araçlarla logical backup almak gerekiyordu ve TB büyüdükçe insanın yüzü düşüyordu). İlginç, değil mi? Şimdi işe storage-level snapshot ile saniyeler içinde recovery point yakalayabiliyorsunuz.
Peki Türkiye’de bunu kim kullanır?
Bence profil kabaca şöyle:
- Bankalar ve finans kurumları: Compliance yüzünden RPO/RTO hedefleri sıkıdır; ilgilenirler ama genelde “GA olduysa hemen koşalım” demek yerine birkaç ay izlemeyi tercih ederler.
- Telekom operatörleri: Büyük veri hacimleri ve çok-volume uygulamalar var; erken benimseyen çıkabilir.
- E-ticaret ve SaaS: Hızlı hareket eden ekiplerdir; muhtemelen ilk altı ay içinde production’a sokarlar.
- KOBİ ve startup: Çoğu managed database kullandığı için konu onlara doğrudan dokunmayabilir bile.
Maliyet tarafı hoş sürpriz yapmıyor
Küçük bir uyarı bırakayım.
Azure Disk CSI tarafında her snapshot incremental olsa bile storage tüketiyor.
4 TB’lık bir grupta günlük snapshot alıp retention süresini de 30 gün tuttuğunuzda (değişim oranı yüzde üç beş civarı olsa bile) faturanın şişmesi çok zor değil.
Premium snapshot için gigabyte başına aylık ücretler TL’ye vurunca daha da can sıkıcı görünüyor; kaba hesapla böyle bir grubun aylık geçmişi rahatça birkaç yüz dolar bandına çıkabiliyor. GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımızda bu konuya da değinmiştik.
Snapshot retention policy’nizi büyük ihtimalle
deletionPolicy : Delete‘e göre planlayın ve yanına cleanup job koyun.Aksi hâlde “Retain” seçeneğiyle her şey yerinde kalır; aylar sonra fatura geldiğinde insan ister istemez şaşırıyor.
Bunu zor yoldan öğrenenlerden duydum (ben değildim gerçekten!).
Kafamdaki karşılaştırma tablosu şöyle oturuyor
| Senaryo | VolumeSnapshot | VolumeGroupSnapshot |
|---|---|---|
| Tek volume’lu uygulama | ✅ İdeal | ❌ Gereksiz karmaşa |
| Multi-volume veritabanı (data + log) | ⚠️ Tutarsızlık riski | ✅ Doğru seçim |
| Stateless mikroservis | — | — |
| Distributed sistem (Cassandra, Kafka) | ⚠️ Quiesce gerekir | ✅ Crash-consistent |
| C SI driver desteği yok | ||
| C SI driver desteği yok | ❌ Çalışmaz | ✅ Çalışır şeklinde olması gerekir?
Sıkça Sorulan SorularVolume Group Snapshot her CSI driver’da çalışır mı?Hayır, maalesef. Driver’ın Mevcut VolumeSnapshot kullanımımdan vazgeçip Group’a mı geçeyim?Bir şey dikkatimi çekti: Geçmek zorunda değilsiniz. Tek volume’lu uygulamalar için VolumeSnapshot gayet iyi çalışıyor, hem daha basit. Yanı aslında Group’a geçmeniz gereken senaryo şu: birden fazla volume arasında write order consistency istiyorsanız. Stateless uygulamalar ya da tek diskli setup’lar için fazladan karmaşa yaratmaktan başka bir şey değil açıkçası. Snapshot alırken uygulamam yavaşlar mı?Modern storage sistemlerinde — hani özellikle copy-on-write veya redirect-on-write tabanlı olanlarda — ilk snapshot anı milisaniyeler sürüyor. Yanı uygulama neredeyse hiç hissettirmiyor. Asıl maliyet sonradan çıkıyor; snapshot referans bloklarına yazma yapıldığında küçük bir IOPS overhead’i olarak yansıyor. Tecrübeme göre bu çoğu durumda görmezden gelebileceğiniz bir şey. Kısa bir not düşeyim buraya. Snapshot’tan restore ettiğimde veritabanım düzgün açılır mı?Crash-consistent snapshot, sistemin “güç kesilmiş” anına benzer bir durumu yansıtıyor. Neyse ki modern veritabanları — mesela PostgreSQL, MySQL InnoDB, SQL Server — tam da bu duruma karşı tasarlanmış. Açıldığında WAL/redo log’u replay edip tutarlı bir state’e kendisi geliyor. Ama şunu unutmayın: bu crash-consistent, application-consistent değil (ki bu çoğu kişinin gözünden kaçıyor). Bazı kompleks senaryolarda manual recovery gerekebilir, bence bunu önceden test etmekte fayda var. Bu özellik gerçekten production’a alınabilir mi?Bence evet, ama acele etmeyin. GA, “API stable” demek — yanı gelecekteki sürümlerde breaking change olmayacak. Ama her organizasyonun kendi internal validation süreci var (yanlış duymadınız). Açıkçası en sağlıklısı şu: önce test cluster’da 2-4 hafta gözlemleyin, restore senaryolarını mutlaka deneyin, her şey yolundaysa o zaman prod’a alın. Kaynaklar ve İleri OkumaKubernetes Resmî Blog: Volume Group Snapshots GA Duyurusu |

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.