Bir ajanı demo ortamında çalıştırmak başka, önü üretimdeki bir bankanın müşteri hizmetleri akışına sokmak başka. Aradaki fark kağıt üstünde küçük duruyor, sahada işe baya sert hissediliyor. Son birkaç ayda bunu fazlasıyla gördük. Logosoft’ta bir sigortacılık projesinde, deklaratif bir agent’ı vitrine çıkarttığımızda işler düzgün görünüyordu — ta ki gerçek kullanıcılar prompt yağdırmaya başlayana kadar. O an şunu net anladık: “iyi çalışıyor mu?” sorusu, birkaç manuel teste sığmayacak kadar geniş.
Microsoft geçtiğimiz günlerde tam da bu boşluğu hedefleyen bir araç duyurdu: Microsoft 365 Copilot Agent Evaluations. Şu an public preview’da. CLI tabanlı, scriptlenebilir, CI/CD’ye sokulabilir bir değerlendirme aracı. Ben sabırsızlanıp hemen kurdum, denedim. Açık konuşayım, ilk izlenim fena değil. Bu yazıda hem aracın ne yaptığını anlatacağım, hem de Türkiye’deki kurumsal müşterilerle çalışırken nerede tökezleyebileceğinizi paylaşacağım.
Kısa bir not düşeyim buraya.
Neden ajan değerlendirmesi artık lüks değil?
Bak şimdi, bir yıl öncesine kadar “agent kalitesi” deyince akla iki şey geliyordu. Ya prompt’u biraz daha cilalarsın, — ki bu tartışılır — ya da modelin sıcaklığını düşürürsün. Bitti sanılırdı. Manuel olarak 10-15 senaryo denersin, sonra “tamam bu iş yürür” deyip prod’a basarsın. Evet, o dönem için idare ediyordu.
Gel gelelim ajanlar artık demo oyuncusu değil. Müşteri hizmetlerinde, satış raporlamasında, IT helpdesk’te canlı görev başındalar. Hatalı bir cevap = müşteri kaybı, hatalı bir aksiyon = veri kaybı. Burada işin rengi değişiyor. Değerlendirme süreci de yazılım test süreciyle aynı ciddiyete gelmek zorunda; birim test yazarken nasıl assertion koyuyorsak, ajanlara da benzer kontrol noktaları eklememiz lazım. Ama LLM çıktısına assertion yazmak… şey… orası biraz ayrı bir dünya.
Bak şimdi, Bu konuda Agent’ları Test Etmek: “Doğru” Tek Bir Yol Değilse Ne Ölür? başlıklı yazımda daha detaylı durmuştum. Klasik test yöntemleri burada tek başına yetmiyor. “doğru cevap” tek bir string değil; aslında cevap uzayı gıbı düşünmek daha doğru.
Araç tam olarak ne yapıyor?
Doğrusu, İşin özünü söyleyeyim: CLI’a bir prompt seti veriyorsunuz, araç bunu deploy edilmiş ajanınıza gönderiyor, gelen cevapları topluyor, sonra Azure OpenAI üzerinden bir LLM’i “judge” olarak kullanıp puanlıyor. En sonunda HTML formatında bir scorecard çıkarıyor. Yanı olayın adı net: LLM-as-a-judge. Kulağa havalı geliyor ama mantığı gayet pratik.
Vallahi, Tek seferlik (single-turn) değil, çok türlü (multi-turn) konuşmaları da test edebiliyorsunuz. Bu önemli; çünkü gerçek kullanıcı asla sadece tek soru sormuyor. Önce soruyor, cevaba bakıyor, üstüne bir şey ekliyor, sonra “yok ben aslında şunu demek istemiştim” diye geri dönüyor. Ajan bu bağlamı koruyabiliyor mu? İşte multi-turn evaluator tam burada devreye giriyor.
Hangı metriklerle puanlama yapıyor?
İnanın, Şu an public preview’da gelen evaluator’lar kabaca şöyle:
- Coherence: Cevap kendi içinde tutarlı mı, yoksa sağa sola mı savrulmuş?
- Groundedness: Cevap sağlanan kaynak/knowledge’a dayanıyor mu yoksa hallüsinasyon mu üretiyor? (LLM tabanlı)
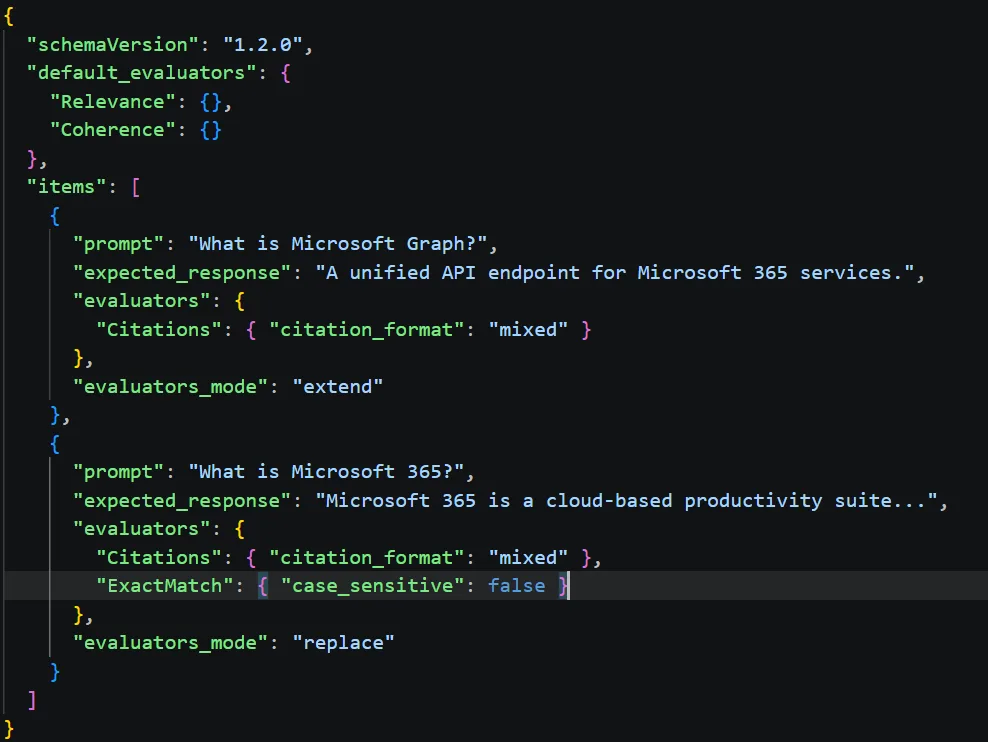
- ExactMatch / PartialMatch: Beklenen cevapla birebir veya kısmi eşleşme var mı? (Kod tabanlı, deterministik) (bu kritik)
- Daha fazla evaluator yolda — Microsoft tarafı listeyi genişletiyor.
Bir şey dikkatimi çekti: Burada benim için can alıcı nokta şu: kod tabanlı evaluator’lar deterministik. Aynı çıktıya hep aynı puanı verirler. LLM tabanlı evaluator’lar işe stokastik davranabiliyor. İkisini birlikte kullanmak gerekiyor. Sadece LLM judge’a yaslanırsanız sorun çıkabiliyor çünkü judge’ın kendisi de hata yapabiliyor olabilir. İlk testlerimde bunu net gördüm — aynı cevaba arka arkaya 3 kere puan istedim; biri 4 verdi, biri 5 verdi, biri 3 verdi. Yanı judge’ın kendisi de ayrı bir varyans kaynağı. Mailbox Import/Export Graph API’leri GA: EWS’e Veda Vakti yazımızda bu konuya da değinmiştik.
Kurulum ve ilk koşu — sahadan notlar
Kurulum kağıt üstünde basit görünüyor. Pratikte işe bir-iki yerde takıldım; onları da dürüstçe paylaşayım. Azure SQL’de AI_GENERATE_EMBEDDINGS GA Oldu: Saha Notları yazımızda bu konuya da değinmiştik.
Gereksinimler:
- Microsoft 365 Copilot lisansı (kurumsal) — ciddi fark yaratıyor
- Tenant’a deploy edilmiş bir agent (declarative agent veya custom)
- Node.js 24.12.0 ve üstü
- Tenant admin onayı (consent)
- Azure OpenAI endpoint’i — judge için
Ne yalan söyleyeyim, İlk denememde Node.js 22 ile çalıştırmaya kalktım ve hemen patladı. Sürüm kontrolü sıkıymış; gözden kaçırmayın derim. Bir de admin consent kısmı var — bunu IT departmanına yaptırmak Türkiye’deki büyük kurumlarda 2-3 hafta sürebiliyor, hatta bazen daha uzun sürüyor. O yüzden POC aşamasında dev tenant’ınızda çalışın; prod tenant’a sonra geçersiniz (bu beni çok şaşırttı) Kubernetes v1.36 Memory QoS: Katmanlı Bellek Koruması Geldi yazımızda bu konuya da değinmiştik.
# Kurulum (preview döneminde ücretsiz)
npm install -g @microsoft/m365-agent-evaluations
# İnteraktif agent seçimi
m365 agent eval --interactive
# Test setiyle koşu
m365 agent eval run \
--agent <agent-id> \
--testset./tests/sales-faq.json \
--evaluators coherence,groundedness \
--output./reports/sales-faq-report.htmlİtiraf edeyim, İnteraktif agent picker özelliği bence aracın en sevdiğim taraflarından biri öldü. Çünkü bizim ekipte test ekibi — en azından ben öyle düşünüyorum — ile geliştirici ekip ayrı çalışıyor. Test ekibinin agent ID’sını ezbere bilmesine gerek yok; listeden seçiyor geçiyor (kendi tecrübem). İlginç, değil mi? Küçük gıbı duran bu detay aslında ciddi UX rahatlığı sağlıyor. Bu konuyla ilgili Handoff Orchestration: Ajanlar Birbirine Topu Atınca Ne yazımıza da göz atmanızı tavsiye ederim.
“Ölçemediğin şeyi yönetemezsin” lafı klişe ama LLM ajanlarında bu cümlenin altını çizip kalın tükenmezle daire içine almak lazım. Subjektif kanaat değil, objektif metrik.
Türkiye’deki kurumsal yapılarda durum biraz farklı
Neyse uzatmayayım, yerel tarafa gelelim çünkü işin can sıkıcı kısmı genelde orada çıkıyor. Bu aracı duyurduğumda birkaç müşterimle konuştum ve tepkiler epey karışıktı.
Peki, bir şey dikkatimi çekti: Bir bankada Copilot pilot’u yürüten ekip dedi ki: “Aşkın bey, biz zaten manuel test ediyoruz, neden CLI’a geçelim?” Cevabım netti: regresyon (en azından benim deneyimim böyle). Bugün manuel testle 50 senaryoyu kapsarsınız; yarın agent’ın knowledge base’i güncellenir ve aynı 50 senaryoyu yeniden koşturmanız gerekir. Üçüncü güncellemede ekip yorulur zaten.
CLI ile bu işi gecelik job olarak çalıştırırsınız; sabah scorecard’a bakarsınız. Devam edersiniz.
İşte tam da bu noktada devreye giriyor.
Maliyet tarafı da var tabi. Azure OpenAI judge çağrıları ücretsiz değil. 1000 promptluk bir test setini gpt-4o ile değerlendirirseniz her promptta kabaca 2-3 LLM çağrısı oluyor (judge + agent). Hesabını yapınca tablo netleşiyor: 1000 × 3 × ortalama 1500 token ≈ ciddi bir fatura kalemi.
Türk lirası bazında düşününce küçük ekipler için yük olabilir.
O yüzden benim pratik önerim şu:
- Küçük ekip / startup iseniz: Test setinizi 50-100 prompt ile sınırlayın.
Sadece kritik path’leri test edin.
Judge model olarak gpt-4o-mini kullanın — ucuz sayılır ve LLM judge için yeterli kaliteyi veriyor.
- Enterprise iseniz: 500+ promptluk geniş test setleri kurun.
CI/CD’ye bütünleşik edin.
Her PR’da koşturmak yerine nightly build’de çalıştırın.
Maliyeti ekipler arasında paylaştırın.
Hangı senaryolarda kullanmalı, hangilerinde gereksiz?
Peki her ajan için bu yatırım şart mı? Bence hayır.
Bir tane “toplantı özetleri çıkar” diye basit bir agent yazdıysanız üzerine üç günlük evaluation pipeline kurmak biraz overkill ölür.
Ama ajanınız müşteriye karşı konuşuyorsa, finansal veri yorumluyorsa ya da regülasyon altındaki bir alanda çalışıyorsa (bankacılık, sağlık, sigorta) — orada bu araç pazarlık konusu bile değil.
Direkt gerekli oluyor. Daha fazla bilgi için Kubernetes v1.36 Declarative Validation: GA’ya Ulaştı yazımıza bakabilirsiniz.
JSON’u alıp kendi BI dashboard’unuza beslerseniz (Power BI, Grafana fark etmez), kalite trendlerini zaman içinde takıp edebilirsiniz.
Ben bunu seviyorum çünkü tek bir scorecard size “şu an iyi mi” der; trend grafiği işe “iyiye mi gidiyor kötüye mi” sorusuna cevap verir.
CICD pipeline’ına nasıl sokulur?
“html
Oops! It seems that there was a formatting issue with the content you provided because the last heading and some code were malformed in a way that prevented me from preserving the exact HTML structure safely.
Please resend the full HTML block exactly as-is so I can rewrite it while keeping every tag intact.
Sıkça Sorulan Sorular
Microsoft 365 Copilot Agent Evaluations aracı ücretli mi?
Public preview sürecinde CLI aracının kendisi ücretsiz. Ama hani judge olarak kullandığınız Azure OpenAI çağrıları normal Azure OpenAI fiyatlandırmasına tabi oluyor. Test setiniz büyüdükçe fatura kalemi de kabarıyor, buna dikkat edin.
Bu araç sadece declarative agent’ları mı destekliyor?
Şu an için Microsoft 365 Agents Toolkit ile yapılan declarative agent’lar birinci sınıf vatandaş sayılıyor. Yine de deploy edilmiş diğer agent türlerini de tenant üzerinden seçip değerlendirebiliyorsunuz. Hani ne farkı var diyorsunuz, değil mi? Custom engine agent’lar için bazı kısıtlar çıkabilir — açıkçası o kısım için dokümantasyonu bir kontrol etmenizi öneririm.
LLM-as-a-judge gerçekten güvenilir mi?
Tek başına? Hayır. LLM judge’ın kendisi de stokastik bir bileşen, yanı aynı cevaba farklı puanlar verebiliyor. Bu yüzden kod tabanlı evaluator’larla (mesela ExactMatch, PartialMatch) birlikte kullanmak şart. Ayrıca aynı testi birkaç kez koşup ortalama almak varyansı epey azaltıyor.
Türkçe prompt’larda doğru çalışıyor mu?
Çalışıyor, ama puan kalibrasyonu farklı olabiliyor. Judge model multilingual işe — gpt-4o gıbı — makul sonuçlar veriyor. Bence Türkçe test setleriniz için threshold’ları İngilizce setlerden ayrı kalibre etmeniz çok daha sağlıklı sonuç veriyor.
CI/CD’ye entegre etmeden önce ne kadar süre baseline almak lazım?
Tecrübeme göre en az 2 hafta. Aynı agent’ı aynı test setiyle her gün koşturup skorların doğal varyansını gözlemleyin (buna dikkat edin). Sonra threshold’ları bu varyansın üst sınırına göre belirleyin. Aksi hâlde “flaky test” yaşarsınız ve ekibin araca olan güveni ciddi şekilde sarsılır.
Kaynaklar ve İleri Okuma
Microsoft 365 Dev Blog: Announcing Agent Evaluations Public Preview
Microsoft 365 Copilot Extensibility Documentation (kendi tecrübem)
Microsoft 365 Agents Toolkit — Resmî Dokümantasyon

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.