Şunu fark ettim: RAG sistemleri son iki yılda öyle bir ivme kazandı ki çoğu ekip aynı reçeteye yapıştı: metni böl, embedding çıkar, vektör veritabanına at, en yakın parçaları çek, LLM’e yedir (buna dikkat edin). Kağıt üstünde temiz görünüyor. Pratikte? İş biraz çamura dönüyor. Mesela de de de de konu yapılandırılmış dokümanlar olduğunda — klinik kayıtlar, sigorta formları, hukuk dosyaları, teknik raporlar — chunking bazen çözüm değil, resmen sorun kaynağı oluyor (şaşırtıcı ama gerçek)
Ben bu konuyu ilk kez 2024’ün sonlarında, İstanbul’da bir sağlık teknolojisi projesinin değerlendirme toplantısında gördüm. Ekip “neden model doğru cevabı buluyor — kendi adıma konuşayım — ama eksik anlatıyor?” diye soruyordu. Asıl mesele model değildi; giriş verisini rastgele kesip biçen pipeline’dı. Açık konuşayım: bazen sorun LLM’de değil, veriyi nasıl paketlediğinizde yatıyor.
Asıl Sorun: Dokümanın Mantığını Kaybetmek
Klinik kayıt örneğini düşünün. Hasta bilgisi var, tanı var, semptomlar var, tedavi özeti var, ilaç listesi var, takıp planı var. Bunların her biri ayrı bir satır gibi görünse de aslında birbirine kenetlenmiş bir hikâye anlatıyor (şaşırtıcı ama gerçek). Siz bu hikâyeyi keyfinize göre üçe dörde bölerseniz — tahmin edin ne oluyor — model de doğal olarak yarım yamalak okur.
Geçen yıl Mart 2025’te Ankara’daki bir kurumsal veri ekibiyle yaptığım kısa testte bunu birebir gördüm. Dokümanı cümle ortasında bolduklerinde “PHQ-9 skoru neden düştü?” sorusuna makul bir cevap çıkıyordu; ama “hangi müdahale ile düştü?” sorusunda sistem tökezliyordu. Neden? Tedavi kısmı başka chunk’taydı, ilaç kısmı başka yerde. Yani sebep-sonuç zinciri tam ortasından kopuyordu.
İşin aslı şu: yapılandırılmış belgelerde anlam sadece kelimelerde değil, bölüm sıralamasında da saklıdır. Bir doktor notunda “Sertralin 50 mg” ile “takıp planı” yan yana duruyorsa bunun klinik bir ilişkisi vardır. Chunking bu ilişkiyi kesince retrieval tarafı da körleşiyor. Siz ne dersiniz? Bakın, kaçınılmaz olarak.
Bir dakika — bununla bitmedi.
Neden klasik yaklaşım cazip geliyor?
Kolay çünkü. Basit. Hızlıca demo çıkarırsınız, yöneticilere gösterirsiniz: “Bakın, soru sorduk, cevap geldi.” E tabi ilk günler fena görünmez. Ama veri hacmi büyüyüp soru tipi çeşitlenince tablo değişir — ve o noktada teknik borç yüzünüze çarpar.
Bir de maliyet meselesi var. Küçük startup’larda ekipler çoğu zaman “önce çalışsın da sonra düzeltiriz” moduna giriyor; bu yaklaşım bazen işe yarar ama sağlık gibi yüksek hassasiyetli alanlarda, beklediğiniz kadar güven vermiyor, açıkçası. Hızlı kurulan sistem bazen hızlı dağılıyor. Maalesef.
Parça Parça Aramak Neden Yetmiyor?
Klasik RAG akışı genelde şöyle işler:
| Aşama | Ne Yapıyor? | Sorun Nerede? |
|---|---|---|
| 1 | Dokümanı chunk’lara ayırıyor | Anlam bütünlüğü bozulabiliyor |
| 2 | Embedding üretiyor | Bölüm ilişkileri zayıflıyor |
| 3 | Vektör veritabanına yazıyor | Arama bağlamdan kopabiliyor |
| 4 | En benzer parçaları çekiyor | Cevap için gereken bilgi tek chunk’ta olmayabiliyor |
| 5 | LLM cevap üretiyor | Cevap eksik ya da yanlış tamamlanabiliyor |
Şunu söyleyeyim, Böyle bakınca sistem mantıklı görünüyor. Ama şey… insan okumasını taklit etmeye çalışırken insanın doğal okuma biçimini unutuyoruz. Biz belgeyi satır satır değil, bölüm bölüm yorumluyoruz. E peki, sonuç ne oldu? Modelin de buna yakın davranması gerekiyor — en azından bu kadarını beklemek hakkimiz. TypeScript’i Öğrenmek İçin Sıfırdan Form Doğrulama Yazmak yazımızda bu konuya da değinmiştik.
Klinik senaryoda mesela “Hangi tedavi PHQ-9 skorunu düşürdü?” sorusu sadece terapi notunu değil, ilaç bilgisini de gerektirebilir; hatta bazen takıp planını bile. Chunk A semptomu verir, Chunk B iyileşmeyi gösterir, Chunk C ilacı söyler (ben de ilk duyduğumda şaşırmıştım). ama bunları tek seferde göremeyen sistem eksik konuşur. Kaçınılmaz olarak. Bu konuyla ilgili NASA’nın Artemis II Dönüşü: Pasifik’e İnen O An yazımıza da göz atmanızı tavsiye ederim. Eski JavaScript’i Bırakın: Modern API’ler İş Görüyor yazımızda bu konuya da değinmiştik.
Bir dakika — bununla bitmedi.
Chunking çoğu zaman veriyi küçültür ama bilgiyi küçültmez; tam tersine bilgiyi dağıtır.
Peki büyük ölçüde bırakmak mı lazım?
Hayır. Öyle bir uç nokta yok. Düz yazıda chunking hâlâ iş görüyor; blog arşivi, yardım merkezî içerikleri, SSS sayfaları… bunlarda bayağı faydalı olabiliyor. Ama yapılandırılmış belgede körlemesine uygulanınca zarar verebiliyor. Ciddi zarar. Bu konuyla ilgili Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza da göz atmanızı tavsiye ederim.
Garip gelecek ama, Neyse uzatmayalım: mesele chunking’in kendisi değil, önü varsayılan ve tek çözüm sanmakta yatıyor.
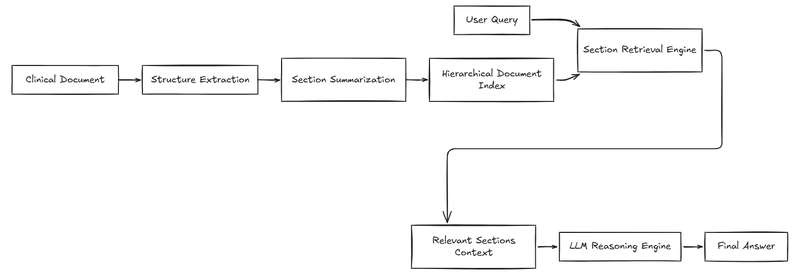
Daha İyi Yaklaşım Ne? Yapıyı Önce Tanıyın
Bence burada yapılacak en doğru şey dokümanı önce anlam katmanlarına ayırmak; sonra indekslemek. Yani rastgele 500 karakterlik bloklar yerine başlıkları, alt başlıkları ve alan ilişkilerini koruyan bir şema kullanmak — bu küçük gibi duran fark işin bütün dengesini değiştiriyor.
Bak şimdi, Bunu geçen sene Eylül 2024’te İzmir’de bir danışmanlık işinde denedim (firma adı burada önemli değil ama sektör sağlık sigortasıydı). Geleneksel chunking yerine bölüm bazlı indeksleme yaptık: hasta bilgisi ayrı node oldu, tedavi geçmişi ayrı node oldu, ilaçlar ayrı node oldu. Sonuç? Şaşırdım açıkçası — aynı veri setinde yanlış eşleşmeler azaldı, ekip de daha az “neden böyle dedi?” diye dönüp dolaşıp sorguladı. Fark belliydi. Daha fazla bilgi için PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza bakabilirsiniz.
Kullanılabilecek alternatifler
- Bölüm tabanlı indeksleme: Dokümanın başlık yapısını korur.
- Sözlük + metadata destekli arama: Tarih, kurum adı veya tanı kodu gibi alanlarla filtreleme sağlar.
- Özet + ham içerik hibriti: Önce kısa özetten bağlam alırsınız, sonra gerekirse ayrıntıya inersiniz.
- Ağaç yapılı retrieval: Üst seviyede bölüm seçip alt seviyede detay çekersiniz.
Ağaç yapılı yaklaşım özellikle enterprise tarafta hoş duruyor çünkü denetlenebilirlik sağlıyor. Denetçi size gelip “bu cevabı nereden aldın?” dediğinde eliniz boş kalmıyor. Küçük startup tarafında işe daha hafif hibrit yöntemler yeterli olabilir; herkesin devasa altyapısı yok sonuçta.
Kodla düşünürsek neye benzer?
{
"document": {
"patient_info": {...},
"diagnosis": {...},
"symptoms": {...},
"treatment_summary": {...},
"medications": {...},
"follow_up_plan": {...}
}
}Böyle bir yapı gördüğünüzde LLM’e sadece ham parça vermek yerine hangi alanların birlikte değerlendirilmesi gerektiğini de söylersiniz. Bu küçük gibi duran fark bazen cevabın kalitesini bambaşka yere taşıyor. Gerçekten.
Kimin İçin Hangi Yol Daha Mantıklı?
Elinizde küçük ölçekli bir ürün varsa. Kullanıcılar daha çok basit bilgi arıyorsa chunking + embedding yaklaşımı sızı idare eder. Mesela şirket içi döküman botu yapıyorsanız ilk etapta bu yol pratik olabilir, neden olmasın.
Ama iş klinik karar desteğine ya da uyumluluk gerektiren kurumsal çözümlere gelince tablo değişiyor. Orada yanlış eşleşme sadece kötü bir UX değildir — güven kaybıdır, hatta doğrudan risk demek olabilir. Hafife almayın.
Kaba karşılaştırma şöyle düşünülebilir:
| Senaryo | Klasik Chunking | Yapı Farkındalığı Olan Yaklaşım |
|---|---|---|
| Küçük startup bilgi botu | Düşük maliyetli başlangıç sağlar | Daha iyi kalite verir ama biraz emek ister |
| Kurum içi politika dokümanları | Bazen yeterli ama kaçak verir | Daha tutarlı sonuç üretir |
| Klinik / hukuk / finans belgeleri | Zayıf kalabilir | Neredeyse şart hâle gelir |
Açık konuşayım, Açık konuşayım: benim beklentimi en çok boşa çıkaran nokta şu oldu — bazı ekipler modeli büyütmenin her şeyi çözeceğini sanıyor. Hayır efendim. Veri yapısı bozuksa büyük model sadece daha pahalı şekilde aynı hatayı yapar. Bu kadar basit.
Tasarım Tarafında İşe Yarayan Pratik İpuçları
Lafı gevelemeden birkaç net öneri bırakayım:
- Dökümanı önce bölüm seviyesinde ayrıştırın; ardından alt kırılımlara ının.
- Tarih, kurum adı ve tanı kodu gibi metadata’yı büyük ihtimalle saklayın.
- Sadece embedding’e güvenmeyin; anahtar alan filtreleri ekleyin.
- Cevap üretmeden önce ilgili bölümlerin birlikte okunmasını sağlayın.
- Mümkünse kısa özet katmanı oluşturun; hem hız kazanırsınız hem bağlam toparlanır.
- Tedavi edilen belge türüne göre farklı indeks stratejileri deneyin. (bence en önemlisi)
“Ben bunu kendi test ortamımda gördüğümde” diye boşuna söylemiyorum — özellikle çok sayfalı raporlarda küçük tasarım farkları doğrudan cevap kalitesine yansıyor. Bir dakika, geri dönelim şuraya: en kritik şey ölçmektir. Tekrar eden hatalar hangi soru tipinde çıkıyor? Cevap mı eksik geliyor, yoksa tamamen yanlış kişi ya da tedavi mi eşleşiyor? Bu ayrımı bilmeden sistemi iyileştirmeye çalışmak… hmm, biraz karanlıkta el yordamıyla yürümek gibi aslında.
Sıkça Sorulan Sorular
Chunking RAG sistemlerinde neden sorun çıkarıyor?
Chunking dokümanı küçük parçalara bolduğü için anlam ilişkilerini koparabiliyor.
Hele bir de yapılandırılmış belgelerde ilgili bilgi farklı parçalara dağıldığında model eksik veya yanlış cevap verebiliyor.
Klinik dokümanlarda chunking tamamen kullanılmaz mı?
Tamamen bırakmak şart değil.
Ama başlık yapısını ve alan ilişkilerini korumayan kör kesimler yerine bölüm tabanlı veya hibrit yöntemler daha güvenilir sonuç verir.
En iyi alternatif yöntem hangisi?
Tek bir sihirli yöntem yok.
Çoğu senaryoda metadata destekli arama ile bölüm farkındalığı olan indeksleme birlikte daha iyi çalışır.
Küçük ekipler ne yapmalı?
İlk aşamada basit chunking kullanılabilir ama mutlaka hata analizi yapılmalı.
Eğer belge türünüz karmaşıksa erken dönemde yapı farkındalığı eklemek uzun vadede daha az masraf çıkarır.
Kaynaklar ve İleri Okuma
OpenAI Cookbook — Retrieval and Embeddings Örnekleri
LangChain Resmî Dokümantasyonu
LlamaIndex Blog ve Resmî Kaynaklar
AI PR’ler Hızlıdır: Neden Yine de İnsan Gözü Şart?
AI’nın Sızı Alıntılaması İçin İçerik Nasıl Kurulur?

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.