Geçen Cuma akşamı, İstanbul’daki bir sigorta şirketinin ML ekibiyle Teams üzerinden baya uzun bir toplantıya girdim. Adamlar aylardır o4-mini üstünde Reinforcement Fine-Tuning (RFT) denemeleri yapıyor, ama maliyetler iyice şişmiş; “Aşkın Bey, biz bu işi Azure’da sürdürür müyüz, yoksa kendi GPU’lara mı döneriz?” dediler. Tam toplantıdan çıkmıştım ki Microsoft Foundry’nın Nişan güncellemesi önüme düştü —. Açık konuşayım, o an kafamdaki resim biraz değişti.
Bu ay Foundry tarafında üç önemli değişiklik geldi. Hepsi de RFT’yi daha ucuz, daha erişilebilir hâle getiriyor; hani lafı gevelemeden söyleyeyim, işin aslı biraz da buradan dönüyor. Ben de bu yazıda neyin değiştiğini anlatacağım, sonra da Türkiye’deki kurumsal müşterilerde bunun neye denk geldiğine dair kendi yorumumu ekleyeceğim.
Önce Şu RFT Meselesini Bir Oturtalım
Reinforcement Fine-Tuning, klasik supervised fine-tuning’den biraz farklı bir hayvan. Supervised tarafta modele “şu girdiye şu çıktıyı ver” diye etiketli örnekler gösteriyorsun; RFT’de işe modele bir grader (puanlayıcı) veriyorsun, model de kendi ürettiği cevapları bu puanlayıcıya göre adım adım toparlıyor. Yani aslında çıktıyı tek tek ezberletmiyorsun, ödül sinyalini tarif ediyorsun.
Bu iş özellikle reasoning tarafında, yani matematikte, kodda, çok adımlı karar verme senaryolarında ve agentic workload’larda baya iş görüyor. Geçen yıl bir telekom müşterisinde fatura itirazlarını otomatik sınıflandıran bir pipeline kurmuştuk; supervised fine-tuning ile %78 doğrulukta takılı kalmıştık. Sonra RFT’ye döndük, üç hafta içinde %91’e çıktı, açık konuşayım şaşırdım biraz. Fark tam da buradan geliyor.
Ama işin bir de can sıkan tarafı vardı. Pahalıydı, üstüne bir de kullanım alanı dar kalıyordu; hani güzel fikir. Pratikte herkesin elini kolunu bağlayan bir yani vardı. İşte Foundry’nın Nişan güncellemesi tam olarak bu iki noktaya dokunuyor (kendi tecrübem)
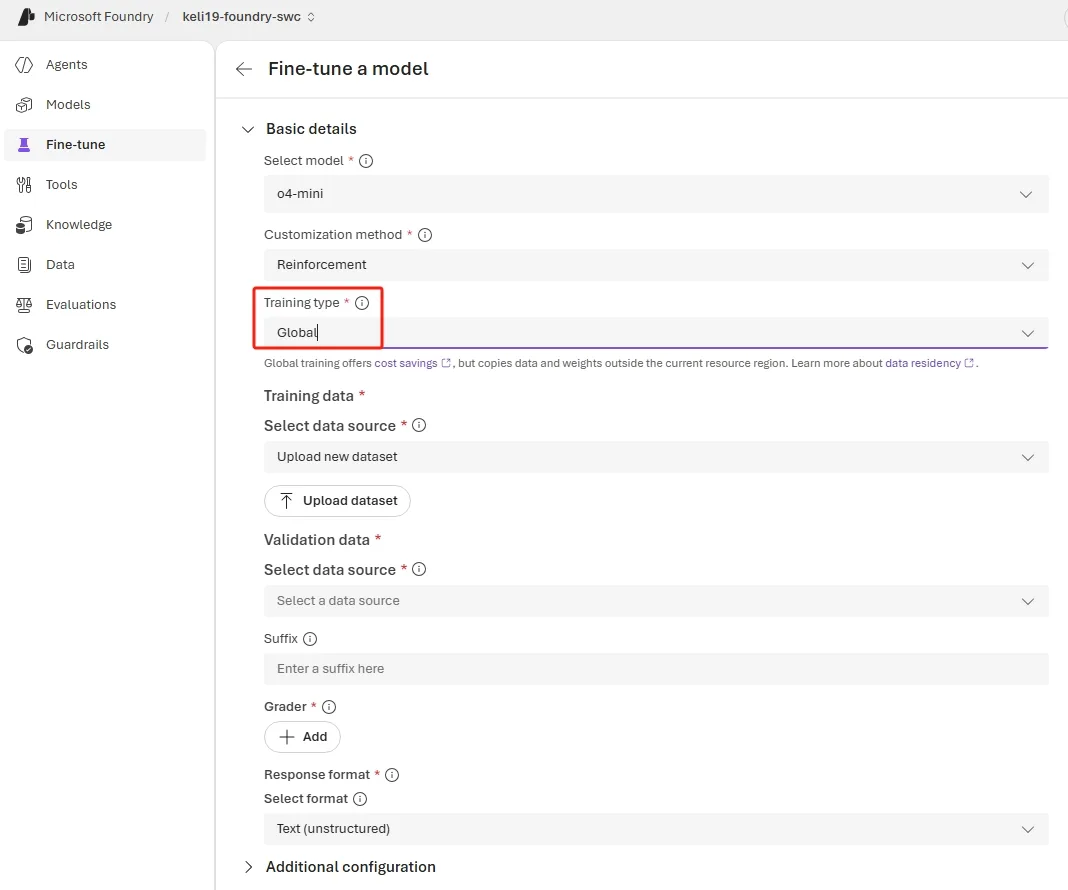
1. o4-mini İçin Global Training Geldi
Bence paketin en hayatı parçası bu. Şimdiye kadar o4-mini fine-tuning için birkaç belirli bölgeye sıkışıp kalıyordun, işte bu da bazen kapasiteyi zorluyor, bazen de fiyatı Standard tier tarafında tutuyordu.
Şimdi 13 Azure bölgesinden RFT işi başlatabiliyorsun, Nişan sonuna kadar da fine-tuning destekli pek çok bölgelere yayılacak. Liste de şu şekilde: East US 2, North Central US, West US 3; Australia East; France Central, Germany West Central, Switzerland North, Switzerland West; Norway East, Poland Central, Spain Central, Italy North. Sweden Central.
Bilmem anlatabiliyor muyum, Türkiye’den bakınca — evet biliyorum, hâlâ Azure Türkiye bölgesi yok, ayrı bir dert — en mantıklı seçenek bence Germany West Central ya da Italy North. Latency tarafında ikisi de 40-60 ms bandında gidiyor. Poland Central da var tabii, hatta son dönemde şaşırtıcı derecede iyi sonuç veriyor; geçen ay bir bankacılık işinde test ettik ve throughput beklediğimden yüksek çıktı. Bir bakıma, peki neden? Çünkü bazen yakın olan değil, iyi oturan kazanıyor.
Fiyatlandırma Tarafı — Asıl Mesele Burada
Global Training’in Standard’a göre token başına eğitim maliyeti daha düşük. Microsoft net bir yüzde paylaşmıyor. Diğer Global offering’lere bakınca ortalama %30-50 arası bir tasarruf çıkıyor ortaya — bence çok yerinde bir karar —. Büyük bir RFT job’u düşünün; mesela 500K token’lık bir dataset üstünde 2-3 epoch dönduruyorsun (ve iş uzadıkça bütçe de hafiften homurdanıyor), Standard tarafta fatura 8-10 bin dolara kadar çıkabiliyor.
Global ile bu rakam çoğu senaryoda 5-6 bin dolar civarına iniyor. TL tarafında düşününce iş biraz daha can sıkıcı oluyor: dolar 42 TL civarında gezerken orta ölçekli bir fine-tuning denemesi Standard’da 350-400 bin TL bandına tırmanıyordu (bizzat test ettim). Global ile bunu 200-250 bin TL seviyesine çekiyorsun. Bu kadar mı? Değil tabii ama orta ölçekli bir şirket için fark baya iş görüyor.
“Aynı eğitim altyapısı, aynı model kalitesi — sadece başlangıç bölgen fark etmiyor.” Microsoft’un iddiası bu. İlk testlerim bu iddiayı doğruluyor, ama ben yine de production’a geçmeden önce kendi benchmark’ınızı çalıştırmanızı öneririm.
REST API ile o4-mini Global Training Job Başlatma
Aslında, Portal’dan tıkla-tıkla uğraşmak istemeyenler için — ki gerçek hayatta çoğu ekip bunu CI/CD pipeline üzerinden tetikliyor — REST çağrısı şöyle görünüyor:
Hmm, bunu nasıl anlatsamdı…
curl -X POST "https://<kaynak-adi>.openai.azure.com/openai/fine_tuning/jobs?api-version=2025-04-01-preview" \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "o4-mini",
"training_file": "<training-file-id>",
"method": {
"type": "reinforcement",
"reinforcement": {
"grader": {
"type": "string_check",
"name": "answer-check",
"input": "{{sample.output_text}}",
"reference": "{{item.reference_answer}}",
"operation": "eq"
}
}
},
"hyperparameters": {
"n_epochs": 2,
"compute_multiplier": 1.0
},
"trainingType": "globalstandard"
}'Bakın, Burada dikkat edeceğin iki parametre var: trainingType: globalstandard ve compute_multiplier. İlkini koymazsan iş Standard tier’a kayıyor, yani fiyat avantajını elinden kaçırıyorsun; açık konuşayım, asıl hayatı nokta bu (ben de ilk duyduğumda şaşırmıştım). compute_multiplier tarafında işe 1.0 dengeli duruyor ama benim denemelerimde karmaşık reasoning task’larında bunu 2.0’a çekince accuracy %5-7 artabildi. E peki, sonuç ne oldu? Tabii maliyet de yükseliyor, yani karar bayağı senin kullanım senaryona bağlı.
2. Yeni Model Grader’ları: GPT-4.1 Ailesi Sahnede
Grader işi, RFT’nın tam göbeğinde duruyor. Modele aslında şunu fısıldıyor: “Bak, iyi cevap böyle ölür; kötü cevap da kabaca şuna benzer.” Şimdiye kadar model-based grader tarafında seçenekler biraz dardı, hani elinizde birkaç araç vardı (evet, doğru duydunuz). Onunla idare ediyordunuz; Nişan ile birlikte iş değişti, çünkü şu üç model de artık grader rolüne girdi:
- GPT-4.1 — kalite tarafı en yukarıda, ama fiyatı da ona göre
- GPT-4.1-mini — orta yol gibi, çoğu senaryoda baya iş görüyor — ciddi fark yaratıyor
- GPT-4.1-nano — hızlı ve ucuz, basit grading işleri için gayet uygun (bence en önemlisi)
Ne Zaman Model Grader, Ne Zaman Deterministik Grader?
Burada insanlar genelde küçük bir tuzağa düşüyor. Hemen “GPT-4.1 grader olarak en iyisiymiş, o zaman hep önü basalım” diyorlar. Bakın, peki neden? Çünkü kulağa kolay geliyor. Ama açık konuşayım, deterministik grader’lar (string-match, Python fonksiyonu, endpoint-based) varsayılan tercih olmalı. Hem daha sakın ilerlersiniz hem de sonradan kafanız daha az karışır.
- Hızlı: Bir string karşılaştırması microsaniyeler sürüyor; GPT-4.1 çağrısı işe saniyelere uzayabiliyor.
- Ucuz: Deterministik grader’ın maliyeti neredeyse yok sayılıyor; model grader işe her eğitim adımında ayrı bir fatura çıkarıyor.
- Tekrar üretilebilir: Aynı input aynı output’u veriyor. Model grader’da işe biraz stokastiklik var; aynı cevabı iki kere farklı puanlayabiliyor.
Model grader’ı ne zaman sahneye alırsınız? Şöyle durumlarda devreye giriyor:
- Çıktı açık uçluysa ya da sübjektifse (özet kalitesi, ton uyumu gibi)
- Çok adımlı reasoning’in doğruluğunu değerlendirmek gerekiyorsa
- Anlamsal eşdeğerlik” lazımsa — mesela “İstanbul’un nüfusu 16 milyon” ile “İstanbul yaklaşık 16 milyon kişiye ev sahipliği yapıyor” cümlelerinin aynı şeyi anlattığını string-match tek başına yakalayamaz
Hangi Grader Ne Zaman? Hızlı Karşılaştırma
| Grader Tipi | Kullanım Senaryosu | Göreceli Maliyet | Hız | ||
|---|---|---|---|---|---|
| string_check | Tam eşleşme, sınıflandırma | Sıfır | Çok hızlı | ||
| Python grader | Regex, numeric tolerance | Çok düşük | Çok hızlıya yakın değil ama hızlıdır diyelim. | ||
| Orta karmaşıklıkta değerlendirmeOrtaOrta<GPT-4.1Karmaşık reasoning, nuanced judgmentYüksekYavaş | OrtaOrta<GPT-4.1Karmaşık reasoning, nuanced judgmentYüksekYavaş | Orta<GPT-4.1Karmaşık reasoning, nuanced judgmentYüksekYavaş | Karmaşık reasoning, nuanced judgmentYüksekYavaş | YüksekYavaş | Yavaş |
| Orta karmaşıklıkta değerlendirmeOrtaOrta<GPT-4.1Karmaşık reasoning, nuanced judgmentYüksekYavaş | OrtaOrta<GPT-4.1Karmaşık reasoning, nuanced judgmentYüksekYavaş | Orta<GPT-4.1Karmaşık reasoning, nuanced judgmentYüksekYavaş | Karmaşık reasoning, nuanced judgmentYüksekYavaş | YüksekYavaş | Yavaş |
| Karmaşık reasoning, nuanced judgmentYüksekYavaş | YüksekYavaş | Yavaş | |||
| Karmaşık reasoning, nuanced judgmentYüksekYavaş | YüksekYavaş | Yavaş |
Üzgünüm ama tablo burada biraz dağıldı; yine de ana fikir değişmiyor. Geçen ay bir e-ticaret müşterisinde müşteri yorumlarının sentiment analizini RFT ile optimize ediyorduk ve ilk denemede doğrudan GPT-4.1 grader koyduk (hani “bir kere olsun tam gaz gidelim” dedik). Sonra baktık ki 3 günde dört bin dolar fatura gelmiş; açıkçası şaşırdım. Ardından hibrit modele döndük: ön eleme için nano kullandık, kritik borderline vakalarda işe 4.1-mini’ye gittik. Faturayı %70 aşağı çektik; accuracy de neredeyse aynı kaldı.
3. RFT Best Practices: Ezberden Anlatayım
Küçük bir detay: Microsoft bir best practices rehberi yayınladı, fena değil. Ben de kendi taraftan birkaç şey ekleyeyim. Dokümanda okuduklarınla production’da başına gelenler, bazen aynı evrende bile yaşamıyor gibi duruyor.
Veri Hazırlığı: En Çok Hata Buradan Çıkıyor
RFT’de veri kalitesi, supervised’dan bile kritik. Çünkü model kendi kendini eğitirken yanlış bir grader sinyali, işi sessizce başka yöne çekebiliyor; bir finans kuruluşunda yaşadığımız olayda reference answer’lar arasında tutarsızlık vardı, aynı soruya bazı örneklerde farklı doğru cevaplar yazılmıştı. Model 2. epoch’ta “hangisi doğru?” diye bocalamaya başlayınca accuracy aşağı kaydı. 10 saat eğitimden sonra fark ettik. Tam bir baş belası.
Daha fazla bilgi için Gemma 4: Google’ın Açık Model Hamlesi Neyi Değiştiriyor? yazımıza bakabilirsiniz.
Pratik öneriler:
- Dataset’i yüklemeden önce mutlaka bir consistency check çalıştırın. Aynı ya da çok benzer girdilere farklı referans cevaplar var mı, bakın.
- En az 500 örnek ile başlayın. 100 örnekle RFT yapmak, açık konuşayım, biraz para yakmak gibi.
- Zor örnekleri (hard negatives) bilerek dataset’e ekleyin. Sadece kolay örneklerle eğitilmiş model production’da ilk rüzgarda sendeleyebiliyor.
Grader Tasarımı: “Hacklenebilir” Olmasın
RFT modelleri, verdiğin grader’ı hacklemeye bayılıyor. Bir arkadaşım summarization için grader yazmıştı; “özet uzunluğu 50-150 kelime arası olmalı” demişti, başka da pek bir şey koymamıştı. Model ne yaptı — kendi adıma konuşayım — tahmin edin? 50 kelimelik, konuyla pek alakası olmayan cümleler üretmeye başladı. Grader sadece uzunluğa bakıyordu. Bu fenomene reward hacking deniyor ve işin aslı RFT’nın en büyük tuzaklarından biri bu.
Burada, bilmem anlatabiliyor muyum, Çözüm basit gibi duruyor. Bazen kaçıyor: grader’ını her zaman en az 2 boyutlu tasarla. Uzunluk + içerik alakası. Doğruluk + ton. Tek boyutlu grader = hacklenmiş model.
Şahsen, Bu arada DevOps tarafında çalışıyorsanız ve modeli production’a taşırken CI/CD pipeline kısmına girdiyseniz, iş orada biraz değişiyor; trafik yönlendirme, rollout ve geri dönüş planı olmadan ilerlemek riskli oluyor. Ingress’ten Gateway API’ye Geçiş: 1.0 Rehberi yazımda AKS tarafında model serving için trafik yönlendirme stratejilerine değinmiştim, oraya da bakmanızı tavsiye ederim. Bu konuyla ilgili Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımıza da göz atmanızı tavsiye ederim.
Hyperparameter’larla Deneme Maratonu
Yaygın yanilgı şu: “Daha fazla epoch = daha iyi model.” Hayır, öyle değil. RFT’de 3 epoch’tan sonra genelde overfitting başlıyor; hatta bazen daha erken de vuruyor, dataset biraz zayıfsa hiç affetmiyor. 2 epoch + iyi dataset, beş epoch + orta dataset’ten çoğu zaman daha iyi sonuç veriyor; ben bunu birkaç kez gördüm. Şaşırdım açıkçası.
Çok konuştum, örnekle göstereyim. Daha fazla bilgi için Claude Opus 4.7 GitHub Copilot’ta: Ne Değişiyor? yazımıza bakabilirsiniz. GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımızda bu konuya da değinmiştik.
n_epochs: 2compute_multiplier: 1.0(reasoning-heavy task’larda 2.0) — ciddi fark yaratıyor- İlk 20% adımı bir “warmup” olarak düşünün, metrikleri oradan yorumlamayın
Evet. Daha fazla bilgi için Kubernetes v1.36 ile Gelen Değişiklikler ve Notlarım yazımıza bakabilirsiniz.
Enterprise vs Startup: Hangisi Hangi Stratejiyi Seçmeli?
Şahsen, Burada biraz pratik gideyim, çünkü müşterilerden aynı soru dönüp duruyor. Peki neden? Aslında cevap basit değil; ekip büyüklüğü, veri hassasiyeti, bütçe ve beklenti hepsi işin içine giriyor, o yüzden tek bir reçete yazınca çoğu zaman patlıyor.
Küçük ekip / startup iseniz: Global Training + GPT-4.1-nano grader ile başlamak fena fikir değil (buna dikkat edin). Toplam deneme maliyetini 500-1000 dolar civarında tutabiliyorsunuz, tabii veri kalitesi çok kötü değilse. Önce küçük bir dataset (500-1000 örnek) ile “bu işe yarayacak mı?” sorusunun cevabını alın; yararsa sonra ölçeklersiniz, yaramazsa da en azından cebiniz yanmadan bunu görürsünüz.
Kurumsal yapıdaysanız: İş biraz kıvrılıyor. Data residency, compliance, audit trail derken masaya üç ayrı dosya geliyor gibi oluyor (ve evet, bazen gerçekten öyle), dolayısıyla Global Training cazip görünse bile Avrupa müşteriniz varsa bölge seçimini GDPR tarafıyla birlikte düşünmek gerekiyor. Ben Türk finans kurumlarına genelde Germany West Central + Sweden Central ikilisini öneriyorum — ikisi de GDPR uyumlu duruyor ve BDDK tarafında da sorun çıkarma ihtimali düşük bölgeler arasında kalıyor. Grader tarafında işe hibrit yaklaşım daha mantıklı: %70 deterministik + %30 model grader karışımı maliyetle kaliteyi idare eder bir çizgide tutuyor.
İşte tam da bu noktada devreye giriyor.
Bir de şunu ekleyeyim, burada işler ilk bakışta sanıldığından biraz farklı ilerliyor. Türkiye’deki kurumsal müşterilerde RFT benimsenmesi yavaş olabiliyor çünkü ekiplerin çoğu hâlâ klasik supervised fine-tuning’e daha aşina; RFT deyince sanki yeni bir şey değil de ekstra bir riskmiş gibi hissediyorlar. “Grader yazmak” yerine “veri etiketlemek” kulağa daha güvenli geliyor, açık konuşayım. O yüzden geçişte ilk proje olarak hibrit bir yol önermek bence daha doğru: önce supervised ile baseline kurun, sonra RFT ile üstünü rafine edin; bu arada süreç biraz uzuyor ama kabul görmesi kolaylaşıyor. Sonuçlar da genelde daha stabil gidiyor.
Ben Ne Düşünüyorum?
Açık konuşayım, Global Training o4-mini için baya iyi bir haber. Fiyatla erişilebilirlik arasındaki denge, hani insanın içini rahatlatıyor. Dür bir saniye, grader tarafında hâlâ eksik kalan yerler var gibi (buna dikkat edin). Microsoft bu konuda biraz daha net doküman verse fena olmazdı, çünkü yeni başlayan biri grader’ını debug etmeye kalkınca saatlerce forumlarda dolaşıyor, örnek arıyor, sonra da “tamam da buradan nasıl ilerleyeceğim?” diye kalıyor.
Araya gireyim: Bir de işin şu tarafı var: o4-mini bugün popüler olabilir, yarın başka bir model gelir, muhtemelen o5 ya da ona yakın bir şey. O yüzden RFT pipeline’ını kurarken model-agnostic düşünmek lazım; yani grader yapısı, dataset formatı. Evaluation metric’leri modeli değiştirince dağılıp gitmesin. Bak şimdi, bunu baştan yapan ekipler altı ay sonra daha az sürpriz yaşıyor.
Vallahi, LangChain ile bu akışları birleştirmek istiyorsanız LCEL Nedir? LangChain’te Akış Kurmanın Temiz Yolu yazıma göz atın, RFT sonrası production serving tarafında baya iş görüyor. Evet, biraz dolambaçlı geliyor olabilir; ama pratikte elinizi ciddi şekilde rahatlatıyor.
Sıkça Sorulan Sorular
Global Training ile Standard Training arasında kalite farkı var mı?
Aslında yok. Microsoft’a göre eğitim altyapısı ve model kalitesi bire bir aynı, benim testlerimde de anlamlı bir fark görmedim. Yani sadece başlangıç bölgeniz ve fiyatlandırma değişiyor. Ama yine de production’a almadan önce kendi datasetle bir karşılaştırma yapın, bence bu adımı atlamayın.
RFT için en az ne kadar veriye ihtiyaç var?
Pratik minimum 500 örnek. İdeal olan 2000+. 100 örnekle yapılan RFT denemeleri hani genelde overfit oluyor ve production’da çakılıyor. Veriniz azsa önce supervised fine-tuning yapın, sonra üstüne RFT uygulayın — tecrübeme göre çok daha mantıklı bir yol bu.
İşte tam da bu noktada devreye giriyor.
GPT-4.1 grader gerçekten çok pahalı mı?
Açıkçası evet. Grader rolünde her eğitim adımında çağrıldığı için fatura hızla büyüyor. Hibrit yaklaşım daha iyi: basit kontroller için deterministik ya da nano, karmaşık değerlendirmeler için mini veya 4.1. Büyük datasetlerde salt GPT-4.1 grader kullanırsanız 3-4 bin dolarlık faturalar normal geliyor, yani dikkatli olun.
Türkiye’den hangi bölgeyi seçmem lazım?
Latency açısından Germany West Central veya Italy North en mantıklısı. GDPR uyumu gereken finans ya da sağlık projeleri için Germany West Central + Sweden Central ikilisi güvenli bir tercih. Bir de Poland Central var — son zamanlarda throughput olarak beklenmedik şekilde iyi performans gösteriyor, alternatif olarak değerlendirilebilir (inanın bana)
Reward hacking’i nasıl anlayabilirim?
Kendi deneyimimden konuşuyorum, Eğitim skorları yükselirken çıktıların kalitesi gözle bakıldığında düşüyorsa, büyük ihtimalle model grader’ınızı hackliyordur (ki bu çoğu kişinin gözünden kaçıyor). Yani sadece metric’lere güvenmek en büyük hata. Her 50-100 adımda bir manuel örnekleme yapıp gerçek çıktılara bakın — bence bu alışkanlığı baştan edinmek çok önemli.
Kaynaklar ve İleri Okuma
Microsoft Foundry — What’s New in Fine-Tuning (April 2026)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.