Yapay zekâ tarafında son iki yılda şunu çok net gördük: büyük model demek her zaman en iyi model demek değil. Bazen daha küçük ama daha akıllı bir model, günlük işlerde çok daha fazla iş görüyor. Gemma dört de tam bu noktada ilginçleşiyor. Tahmin eder mısınız? Kâğıt üstünde devasa bir canavar gibi görünmüyor; ama performans-per-parameter dediğimiz o meşhur randıman yarışında bayağı iddialı duruyor.
Editör masasında bu konuyu ilk okuduğumda aklıma hemen geçen ay İstanbul’da bir startup kurucusuyla yaptığım sohbet geldi. Adamın derdi basitti: “Model güzel olsun da, bizim sunucuda nefes alsın yeter.” İşte açık ağırlıklı modellerin asıl olayı burada başlıyor. Her şeyi API’ye bağlayıp aylık faturayı şişirmek yerine, uygun donanımda kendi modelini çalıştırmak istiyorsun. Gemma ailesi de zaten bu ihtiyaca oynuyor.
Çok konuştum, örnekle göstereyim.
Aslında — hayır dür, daha doğrusu — dür bir saniye, önce şunu söyleyeyim: Gemma 4’ü sadece “bir başka LLM sürümü” diye görmek biraz haksızlık ölür. Çünkü burada mesele salt büyüklük değil; sıkıştırılmış bilgi, mimarı ince ayarlar ve öğretmen-öğrenci mantığıyla gelen ciddi bir yoğunluk var. Hani bazı insanlar az konuşur ama nokta atışı yapar ya (ciddiyim). model tarafındaki karşılığı biraz öyle.
Gemma 4 neden konuşuluyor?
Lafı gevelemeden söyleyeyim: çünkü piyasadaki modellerin büyük çoğunluğu hâlâ “güçlü ama ağır” kategorisinde takılı kalmış durumda. Hele bir de kurumsal tarafta bu durum gerçekten can sıkıcı oluyor — GPU maliyeti ayrı dert, gecikme ayrı dert, ölçekleme ayrı dert. Gemma 4 işe daha dengeli bir paket sunmaya çalışıyor.
İşte tam da bu noktada devreye giriyor.
Benzer tartışmayı 2023’te Berlin’deki bir ürün ekibinde de duymuştum. Orada ekip, müşteri destek botu için önce büyük bir kapalı modeli denemişti; cevap kalitesi iyiydi ama yanit süresi. Maliyet yüzünden proje yarım yamalak kaldı. Sonra daha küçük bir modele geçtiler ve biraz ince ayarla işi toparladılar. Yani bazen “en güçlü” olan değil, “yeterince iyi ve sürdürülebilir” olan kazanıyor. Bu kadar basit.
Kendi deneyimimden konuşuyorum, Gemma serisinin genel çizgisi de zaten buraya oturuyor. Google’ın Gemini tarafında geliştirdiği tekniklerin açık dünyaya taşınmış hâli gibi düşünebilirsiniz. Burada önemli olan şu: modelin ham kapasitesinden ziyade o kapasitenin ne kadar sıkışık kullanıldığı.
Mimaride neler var?
Gemma 4’ün omurgası klasik transformer decoder yaklaşımı üzerine kurulu gibi görünse de ayrıntıda işler değişiyor. Multi-Query Attention (MQA) ve Grouped-Query Attention (GQA), özellikle bellek kullanımını hafifletmek için öne çıkıyor. Peki bunu neden söylüyorum? Düz anlatayım: aynı anda birçok kişiye servis veren ama mutfakta tek kasayla çalışan bir restoran gibi düşünün — düzen kurulursa hızlı akıyor, bozulursa her şey tıkanıyor.
Sliding Window Attention (SWA) kısmı da fena değil, hatta baya işe yarıyor diyebilirim. Uzun bağlamlarda her token’a körlemesine bakmak yerine pencere mantığıyla ilerlemek hem hız hem verim sağlıyor. Tabii bunun bir bedeli var; uzun mesafeli bağımlılıklarda bazen gözden kaçırdığı detaylar çıkabiliyor ortaya. Kağıt üstünde süper, pratikte göreceğiz artık. Bu konuyla ilgili Apple, iPadOS 26.5 ve tvOS 26.5 için public beta 2’yi yayına aldı yazımıza da göz atmanızı tavsiye ederim.
| Bileşen | Ne işe yarıyor? | Neden önemli? |
|---|---|---|
| MQA / GQA | Daha az bellekle dikkat mekanizması | Daha hızlı çıkarım ve düşük kaynak tüketimi |
| SWA | Pencere tabanlı dikkat yaklaşımı | Uzun metinlerde verimlilik sağlar |
| Logit Soft-Capping | Aşırı büyük çıktı skorlarını sınırlar | Eğitim kararlılığını artırır |
| RMSNorm + RoPE | Sayısal stabilite ve konum bilgisi | Daha sağlam eğitim ve bağlam takibi |
Logit soft-capping kısmını günlük dile çevirirsek şöyle ölür: modelin özgüvenini biraz törpülüyorsun ki saçmalamasın! Bazı sistemlerde aşırı emin cevaplar hata zinciri yaratabiliyor. İşte bunu frenleyen yöntemlerden biri tam da bu. google konusundaki yazımız yazımızda bu konuya da değinmiştik.
Küçük ekip için ne anlama geliyor?
Küçük startup’lar genelde iki şey ister: ucuz olsun ve kolay dağıtılsın. Gemma tarzı modeller burada avantajlı çünkü doğrudan kendi ortamında test edip gerektiğinde özelleştirebiliyorsun. Ben Ankara’daki bir SaaS girişiminde buna benzer bir senaryoyu gördüm; ekip müşteri e-postalarını sınıflandırmak için kapalı API’den çıkıp yerel modele geçtiğinde aylık maliyetlerini ciddi biçimde aşağı çekti. Dramatik fark vardı açıkçası.
Kurum tarafında tablo nasıl?
Bir şey dikkatimi çekti: Büyük şirketlerde mesele biraz farklıdır. Orada güvenlik ekibi devreye girer, veri egemenliği sorulur, log politikası konuşulur, sonra üç toplantı daha yapılır — olmazsa olmaz bunlar. Açık ağırlıklı modeller burada kontrol hissi verdiği için değerli oluyor, ama entegrasyon işleri yine kolay değil; MLOps boru hattını düzgün kurmazsanız model ne kadar iyi olursa olsun boşa gider — bence çok yerinde bir karar —. Tahmin eder mısınız? Gerçekten. YouTube Canlı Yayınlarda Reklam Molası: Vibe Bozulmadan yazımızda bu konuya da değinmiştik. Daha fazla bilgi için Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza bakabilirsiniz. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
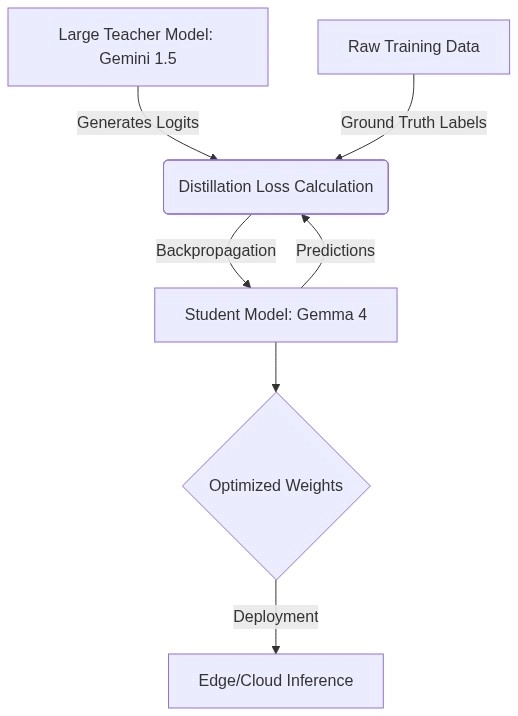
Eğitimde distillation neden kritik?
Bakın, İşin aslı şu ki Gemma 4’ün en ilginç taraflarından biri bilgi damıtımı, yani knowledge distillation yaklaşımı. Büyük öğretmen modeli düşünün; öğrenci model onun davranışlarını taklit ederek öğreniyor. Sadece doğru cevabı değil, cevaba giden yolu da bir şekilde kokluyor diyelim — biraz garip ifade oldu ama doğruya yakın.
Distillation sayesinde küçük modeller sadece ezber yapmıyor; belirsizlikleri, karar tonunu ve örüntüleri de öğreniyor.
Bunu geçen yıl Madrid’de katıldığım kapalı bir teknik oturumda canlı canlı dinledim sayılır; anlatılan şey şuydu: öğrenciyi sıfırdan yetiştirmek yerine usta el hareketlerini gösteriyor, o havayı aktarıyor. Sonuç? Daha kompakt ama beklenenden zeki davranan modeller ortaya çıkabiliyor. Şaşırdım açıkçası.
Piyasadaki rakiplere göre nerede duruyor?
Şöyle ki, Burada dürüst olmak lazım. Hiçbir açık model sihirli değnek değil. Llama ailesi hâlâ çok güçlü, Mistral ekosistemi hâlâ çevik, kapalı tarafta işe bazı ticarî modeller saf kalite açısından önde kalabiliyor (buna dikkat edin). Ama Gemma’nın oyun alanı farklı; özellikle performans/parametre oranına baktığınızda gözünüz istemsizce oraya kayıyor.
- Daha az kaynakla makul sonuç isteyen ekipler için mantıklı.
- Kendi altyapısında koşmak isteyen kurumlara uygun.
- Araştırmacılar için deneme alanı geniş.
- Tam kusursuz olmayan fakat dengeli çözümler arayanlar için iş görür.
Size bir şey söyleyeyim, Neyse uzatmayalım. Eğer hedefiniz “her alanda lider olmak” işe beklentiyi dozunda tutmak lazım. Ama hedefiniz belli görevlerde yüksek verim almaksa, Gemma çizgisi bayağı mantıklı duruyor. Bilhassa de kodlama, özetleme, çok dilli içerik üretimi gibi işlerde potansiyelini ciddiye almak gerekiyor.
Nerede hayal kırıklığı yaratabilir?
Açık konuşayım: bazen topluluk hype’ı modeli olduğundan büyük gösterebiliyor. Kağıt üzerinde müthiş duran şey, gerçek projede veri temizliği yüzünden tökezleyebiliyor. Bir arkadaşım İzmir’deki e-ticaret projesinde tam bunu yaşadı; model iyiydi ama giriş verileri kirliyken çıktıların tadı kaçtı. Yani sorun her zaman modelde olmuyor. Çoğu zaman beslediğiniz veri işi bozuyor.
Sahada kullanırken nelere bakmalı?
Eğer küçük bir startup iseniz önceliğiniz genelde üçlüdür: maliyet, gecikme, kolay bakım. Gemma benzeri açık modeller burada rahat ettirir çünkü doğrudan optimize edebiliyorsunuz. Quantization ile boyutu düşürürsünüz, cache stratejisini ayarlarsınız, gerektiğinde belirli katmanları döndürürsünüz. Basitçe söylemek gerekirse elinizde tornavida var; kapalı API’deyse sadece düğmeye basıyorsunuz. Fark bu.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "google/gemma-4-example"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto"
)
prompt = "Kısaca yapay zekâda distillation nedir?"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=120)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Vallahi, Büyük kurumlarda işe hikâye başka. Orada yalnızca performans yetmez; gözlemleme — itiraz edebilirsiniz tabi — gerekir, sürüm yönetimi gerekir, erişim kontrolü gerekir. Bir production ortamında modeli koyup bırakmak diye bir lüks yok. Geçen sene Londra merkezli finans ekibinde izlediğim kurulumda mühendisler neredeyse modeli yazardan çok loglarla konuşturuyordu — haklıydılar da. Çünkü regülasyon baskısı altında yanlış cevap verecek sistem istemezsiniz.
Kime göre ideal?
| Kullanıcı tipi | Avantajları | Zayıf yani |
|---|---|---|
| Küçük startup | Düşük maliyet, esnek dağıtım, kendi sunucusunda çalışma imkânı | Ayar ister |
| Kurum içi AI ekibi | Veri kontrolü, gizlilik, daha iyi uyarlama | Operasyon yükü artar |
| Araştırmacı / geliştirici | Deneme özgürlüğü, mimariyi anlama fırsatı | Donanım ihtiyacı dolayısıyla yükselir |
Peki benim genel izlenimim ne?
Açık konuşayım. Gemma 4 bana “gösterişli” olmaktan çok “akıllıca tasarlanmış” hissi verdi. Bu ayrım önemli çünkü teknoloji dünyasında çoğu ürün ilk bakışta parlıyor, sonra sönüp gidiyor (buna dikkat edin). Buradaysa tersine bir durum var — az sakın görünüyor ama içine girince mantığını anlıyorsunuz. Hatta biraz mühendis kafası taşıyanlara hitap ediyor diyebilirim.
Yani, Yine de kusursuz değil. Uzun bağlamlarda kimi görevler hâlâ ekstra ayar isteyebilir, bazı senaryolarda rakiplerinin gerisinde kalabiliyor, hatta kullanıcı deneyimi açısından beklediğim kadar pürüzsüz olmayabiliyor. Ama dürüst olayım: ben zaten böyle modellere “tek tuşla mucize” gözüyle bakmıyorum. Önemli olan doğru yerde doğru işi yapmaları.
SIKÇA SORULAN SORULAR
GemMA
hangi tür işler iÇ in uygundur?
Kodlama yardımı, met in özet leme, soru-cevap, içerik taş lak laması multi dil desteği gerektiren uygulamalar iÇ in uygundur. En i yi sonuç, tem iz veriyle alınır.
AçIk aĞIrLIkLI MODELLER NiYe tercih edilir?
ÇÜnkÜ modeli kendi altyapınızda koşturabilirsiniz. Bu, gizlilik, maliyet kontrolÜ Ve özelleŞtirme açIsIndan bÜyük rahatlık verir.
KüÇ ÜK ŞIRketLER İçİN pahalı mıdır?
DoĞru optimizasyonla hayır; aksine bulut API masrafIndAn kurtulmanıza yardImcı olabilir. Tabii GPU veya CPU kaynak planlamasını İYi yapmak şart.
Distillation neden önemli?
Çünkü bÜyük modell erDen gelen davran ış örÜntülerIni kÜÇ ük modele aktar Ir. Böylece parametre sayısı düşük olsa bile zekâ yoğunluğu artar.
Kaynaklar ve İleri Okuma

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.