Şunu söyleyeyim, Yapay zekâ uygulamalarıyla biraz haşır neşir olduysanız, RAG kelimesini mutlaka duymuşsunuzdur. Hani şu her yerde karşınıza çıkan terim var ya; chatbot’larda, şirket içi bilgi aramalarında, doküman asistanlarında… İşin aslı şu ki, RAG artık “trend” olmaktan çıktı — bayağı temel bir mimarı parça hâline geldi. Bunu söylemesi kolay, ama ne anlama geldiğini gerçekten kavramak için biraz derine inmek gerekiyor.
Ben ilk kez 2023 sonbaharında İstanbul’da bir startup ekibiyle çalışırken bu konunun ne kadar kilit olduğunu görmüştüm. Ellerinde düzgün çalışan bir LLM vardı, ekip kendi ürün dokümantasyonunu modele sorunca cevaplar bazen eski sürümlere gidiyor, bazen de özgüvenli. Yanlış cümleler dökülüyordu — hem de hiç çekinmeden, sanki her şeyi biliyormuş gibi. O gün anladım ki model akıllı olabilir, ama hafızası tek başına yetmiyor.
Kısa bir not düşeyim buraya.
Şimdi gelelim meselenin can alıcı kısmına. LLM’ler güçlüdür, evet. Ama tek başlarına kullanıldıklarında birkaç klasik sorun çıkarıyorlar — bunları görmezden gelirseniz sisteminiz güzel görünür, pratikte tökezler. Hem de hiç beklemediğiniz anda.
LLM Tek Başına Neden Yetmiyor?
Bir modeli sadece “çok bilen biri” gibi düşünmek kolay geliyor. Fakat gerçek kullanımda modelin bilgi kesiti var, erişemediği alanlar var. En önemlisi — bazen boşluğu uydurmayla dolduruyor. Bu da özellikle kurumsal işlerde sıkıntı yaratıyor.
Geçen yıl Ankara’da bir müşteri toplantısında buna benzer bir tablo gördüm. Ekip içi politika sorularını doğrudan modele sordular; cevap kulağa çok düzgün geliyordu ama prosedürün yarısı eskiydi. Açık konuşayım, ilk bakışta fark etmiyorsunuz bile… ta ki hukuk ekibi kaşlarını kaldırana kadar.
Eski bilgi meselesi
LLM’lerin çoğu belli bir eğitim tarihine kadar öğreniyor. Yani modelin kafasında dünya o tarihte donmuş gibi düşünebilirsiniz — sonrasında olan biteni ya bilmiyor ya da eksik biliyor. Bu durum haberler için de geçerli, şirket içi veriler için de geçerli, teknik dökümantasyon için de geçerli. Mesela yeni çıkan bir API değişikliğini sorduğunuzda model size eski davranışı anlatabilir; kötüsü şu ki bunu emin konuşarak yapar. Sormadan geçmeyeyim: Peki fark etmeden kaç kez yanlış yönlendirme aldınız?
Halüsinasyon denen tuhaf durum
Maalesef. Modelin en büyük numaralarından biri bu: bilmediği yerde boş bırakmak yerine makul görünen bir cevap üretmek. Buna halüsinasyon deniyor; Türkçesi daha düz — uyduruyor gibi değil de sanki biliyormuş gibi yapıyor.
Bence burada insanın beklentisi ile makinenin çalışma biçimi tam olarak çarpışıyor, nasıl desem, biz “doğruyu söyle” diyoruz; model işe “bir sonraki en olası kelime neyse önü diziyorum” mantığıyla ilerliyor — yani doğruluk değil, olasılık peşinde koşuyor. Mantıklı değil mi? İki farklı dünya bunlar.
Özel verilere erişememesi
Kurumların en değerli bilgileri genelde halka açık değil zaten: iç wiki sayfaları, destek notları, ürün kararları, müşteri kayıtları (şaşırtıcı ama gerçek). Model bunları kendi kendine bilemez. Dokümanı prompt’a yapıştırmak işe kısa vadede çözüm gibi görünür ama context penceresi dolar, maliyet artar ve ölçekleme kabusu başlar. Bu kadar mı? Hayır, bir de bu yaklaşım bakım açısından gerçek bir kâbus.
RAG Tam Olarak Ne Yapıyor?
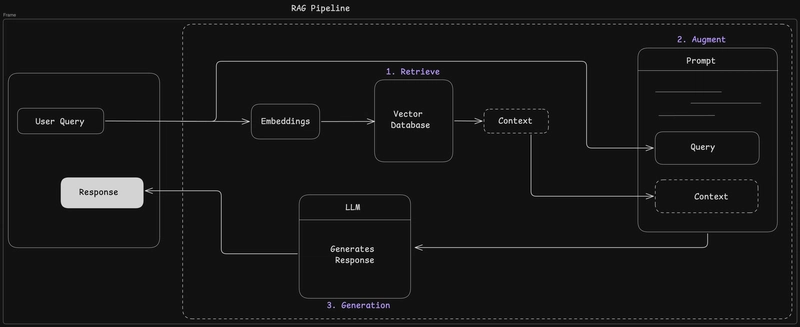
Tuhaf ama, RAG açılımıyla Retrieval-Augmented Generation demek oluyor — yani önce ilgili bilgiyi getiriyorsunuz, sonra modeli o bilgiyle konuşturuyorsunuz. Basit anlatımıyla sistem şunu söylüyor: “Dür bakalım modelciğim, önce dışarıdan taze malzemeyi alalım.” Kulağa basit geliyor. Ama etkisi ciddi. Bu konuyla ilgili Honor Win 2 Sızdı: Batarya ve Ekranda Büyük Oyun yazımıza da göz atmanızı tavsiye ederim.
RAG’in mantığı çok basit ama etkisi büyük: Modelin belleğine güvenmek yerine ona doğru bağlamı veriyorsunuz.
İnanın, Bunu mutfak benzetmesiyle düşünün. Elinizde iyi bir aşçı var ama dolap boşsa ortaya çıkan yemek sınırlı ölür. RAG işe önce pazardan malzeme getiriyor… sonra aşçıya verip yemeği pişirtiyor. Neyse, benzetmeyi fazla uzatmayayım. Daha fazla bilgi için Şifre Alanı Güvenli Sanılıyor: Aslında Açık Kapı Olabilir yazımıza bakabilirsiniz. Bu konuyla ilgili PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza da göz atmanızı tavsiye ederim.
Size bir şey söyleyeyim, Nişan 2024’te İzmir’de yaptığım küçük bir PoC çalışmasında bunu net gördüm. Aynı modeli iki şekilde denedik; biri sadece prompt ile çalıştı, diğeri belge arama katmanı eklenmiş haldeydi. İkinci senaryoda yanit kalitesi bariz şekilde toparlandı —. Model laf kalabalığı yerine gerçekten ilgili parçaları gördü. Şaşırdım açıkçası, bu kadar belirgin olacağını beklemiyordum.
Bileşenler Nasıl Bir Araya Geliyor?
Kulağa karmaşık geliyor olabilir ama temel akış aslında gayet anlaşılır. En sade hâliyle veri alınır, parçalara bölünür, vektöre çevrilir, saklanır ve sorgu geldiğinde uygun parçalar çekilir. Sonra LLM bu bağlamla yanit üretir. Tahmin eder mısınız? Kağıt üstünde temiz bir zincir — ama pratikte her halka ayrı dikkat istiyor. Ateşkes Piyasayı Nasıl Vurdu: 427 Milyonluk Kısa Sıkışma yazımızda bu konuya da değinmiştik.
Çok konuştum, örnekle göstereyim.
| Aşama | Ne oluyor? | Neden önemli? |
|---|---|---|
| Veri alma | Dökümanlar toplanıyor | Taban oluşturuyor |
| Chunking | Büyük metin küçük parçalara ayrılıyor | Araştırma daha isabetli oluyor |
| Embedding | Metin sayısal vektöre çevriliyor | Anlamsal benzerlik bulunuyor |
| Saklama | Parametrik olmayan veri depolanıyor | Sorguda hızlı erişim sağlıyor |
| Retrieval | Soruya uygun parçalar seçiliyor | Laf kalabalığını azaltıyor |
| Generation | LLM son cevabı yazıyor | Bağlamlı yanit çıkıyor |
E tabi burada her şey kusursuz gitmiyor. Chunk boyutu fazla küçük olursa anlam kopuyor, fazla büyük olursa alakasız bilgi taşıyorsunuz — benim sahada gördüğüm en yaygın hata tam da bu. İnsanlar embedding tarafına odaklanıp chunk stratejisini hafife alıyor. Ciddi fark var.
Neden vektör veritabanı gerekiyor?
Sorgu ile belgeyi düz metin olarak karşılaştırmak çoğu zaman yetersiz kalır. Vektör veritabanı devreye girince iş değişiyor; çünkü anlamsal yakınlığı yakalamaya başlıyorsunuz. Yani kelime birebir aynı olmasa bile fikir yakınsa sistem bunu anlayabiliyor — bu küçük bir şey gibi görünür. Pratikte büyük fark yaratıyor. Bu konuyla ilgili Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza da göz atmanızı tavsiye ederim.
# Basitleştirilmiş RAG akışı
user_question = "Şirket izin politikası nedir?"
query_vector = embed(user_question)
top_chunks = vector_db.search(query_vector, top_k=5)
context = "
".join(top_chunks)
answer = llm.generate(
prompt=f"Bu bağlama göre cevap ver:
{context}
Soru:{user_question}"
)Küçük Startup mı Kurumsal Sistem mi?
Bence, Küçük bir startup için RAG çoğu zaman hızlı kazanım sağlar. Çünkü elinizde zaten sınırlı veri vardır ve kullanıcıların sorduğu sorular genelde aynı havuzun etrafında döner (en azından benim deneyimim böyle). Destek botu, doküman arama ve onboarding yardımcısı olarak hemen değer üretir — fazla düşünmeden kurabilirsiniz.
Kurumsal tarafta işe iş biraz ağırlaşır. Güvenlik, yetkilendirme, loglama, versiyonlama, kaynak gösterme… Bunların hepsi masaya gelir. Bir bankada veya sağlık şirketinde retrieval katmanı sadece “ilgili belgeyi bulsun” diye kurulmaz; hangi kullanıcının hangi belgeyi görebileceği de hesaplanır. Aksi hâlde güzel fikir, problemli prod ortamına dönüşür.
Şimdi gelelim işin can alıcı noktasına.
Tuhaf ama, Açık konuşayım: küçük ekiplerde en büyük avantaj hızdır; enterprise’da işe kontrol. Izlenebilirlik öne çıkar. İkisi aynı teknolojiye bakar ama beklenti bambaşkadır. Bazen insanlar bunu unutuyor — sonra neden pilot başarılı olup canlıya çıkınca tökezlediğini anlamaya çalışıyorlar. Tam da öyle.
Peki Eksikleri Yok mu?
Var tabii. Her şeyi pembe anlatmaya gerek yok. RAG güzel bir çözüm ama sihir değil — önce iyi veri lazım, sonra düzgün chunking, ardından kaliteli embedding (kendi tecrübem). üstüne retrieval ayarı, filtreleme, yeniden sıralama derken zincir uzayıveriyor. Zincirin zayıf halkası tüm sonucu etkileyebiliyor. Bu yüzden kağıt üstünde süper görünen demo, pratikte beklediğiniz kadar iyi olmayabiliyor.
Bir diğer hayal kırıklığı da bakım yükü. Veri kaynağı güncellenmezse RAG sistemi canlı canlı eskimeye başlıyor. Ben bunu geçen kış Şubat 2025’te Bursa’daki küçük bir SaaS projesinde gördüm: doküman seti yenilenmemişti, model gayet ciddi şekilde geçmişe takılı kaldı. Kullanıcı tarafında güven kaybı yaratması iki gün sürdü; düzeltmesi işe haftasonuna yayıldı. Neyse, o başka bir yazının konusu (bizzat test ettim)
- Veri tazeliği düzenli kontrol edilmeli.
- Chunk boyutu test edilmeden sabitlenmemeli.
- Retrieval sonuçları gözle izlenmeli.
- Kaynak gösterimi mümkünse kullanıcıya sunulmalı.
- Gereksiz bağlam şişirilmemeli.
Daha Sağlıklı Bir Kurulum İçin Pratik Notlar
Açıkçası, Bakın şimdi, işi sağlam kurmak istiyorsanız üç noktaya özellikle dikkat edin: kaynak kalitesi, retrieval stratejisi ve değerlendirme ölçütleri. Mesela evaluation kısmını atlayan ekipleri çok gördüm — demo parlakken herkes mutlu oluyor; sonra gerçek kullanıcı gelip alışılmadık soru sorunca sistem dağılıyor. Hep aynı hikâye.
Şunu fark ettim: Ben şahsen ilk PoC’lerde hep şu yöntemi seviyorum: önce dar kapsamlı veri seti, sonra birkaç tıp soru, ardından başarısız örnekleri toplamak (evet, doğru duydunuz). Başarısız örneklerden çok şey öğreniyorsunuz; çünkü sistem nereye kör kaldığını orada açık ediyor. Başarılar değil, başarısızlıklar öğretiyor.
Nerede İşe Yarar? Nerede Zorlanır?
Dokümantasyon araması, müşteri destek botu, iç politika asistanı, satış ekibi için ürün bilgi yardımı… bunlarda RAG fena değil, hatta baya işe yarıyor. Çünkü ortada aranacak belirgin kaynak vardır. Soru da genelde sınırlar içinde dolaşır.
Ama soyut muhakeme gerektiren işlerde durum farklılaşır. Mesela hukukî yorum, yaratıcı planlama ya da stratejik öngörü gibi alanlarda retrieval tek başına yetmeyebilir — orada hem modeller hem insan gözü gerekir. Kısacası: RAG güçlüdür, fakat yanlış yere koyarsanız size sahte güven verir. Bu ayrımı erkenden yapmak önemli.
Sıkça Sorulan Sorular
RAG ile fine-tuning aynı şey mi?
Hayır, aynı şey değiller. Fine-tuning modeli yeniden eğitir; RAG işe modele dışarıdan bağlam verir. Çoğu iş senaryosunda önce RAG denenir, çünkü daha hızlı ve ucuzdur. İkisini birlikte kullanmak da mümkün ama önce ihtiyacı netleştirmek lazım.
RAG her tür uygulamada işe yarar mı?
Hayır. Mesela güncel veya kurum içi bilgi gereken yerlerde çok faydalıdır. Ama neredeyse tamamen yaratıcı üretim isteyen ya da yüksek düzey muhakeme gerektiren işler için tek başına yeterli olmayabilir.
Vector database şart mı?
Büyük prod ortamlarında çoğu zaman evet, pratik çözümler sunar. Küçük denemelerde başka yöntemlerle başlanabilir ama büyüdükçe vektör tabanı hayat kurtarır.
Chunking neden önemli?
Aslında, Çünkü uzun belgeleri olduğu gibi sisteme verirseniz ilgili kısmı bulmak zorlaşır. Çok küçültürseniz anlam kaybolur. Dengeli ayar burada kritik rol oynar — ve bu ayarı bulmak genelde biraz deneme yanilma istiyor.
Kaynaklar ve İleri Okuma
İlginç olan şu ki,
Meta AI — Retrieval-Augmented Generation Tanıtımı
LangChain — RAG Kavramları Dokümantasyonu
Pinecone — Retrieval-Augmented Generation Rehberi

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.