Yapay zekâ dünyasında son iki yılda en sık duyduğum cümlelerden biri şu: “Prompt’u biraz daha uzatalım, sorun çözülür.” Açık konuşayım — çoğu zaman çözülmüyor. Hatta bazen tam tersi oluyor; model kendi uydurduğu cevapları daha da özgüvenli bir ses tonuyla sunmaya başlıyor. Geçen yıl Mart 2025’te İstanbul’da bir ürün ekibiyle yaptığım toplantıda tam da bunu tartışmıştık. Ekip, tek bir sistem prompt’una her şeyi yükleyip agent’tan mucize bekliyordu. Mucize gelmedi. Token faturası işe gayet düzenli geldi.
İşin aslı şu: agentic AI tasarlamak, “iyi prompt yazma” işiyle aynı kategoride değil. Burada mesele sadece doğru cevabı almak değil — doğru aracı seçmek, yanlışını fark etmek, hata görünce geri dönebilmek ve neredeyse tüm bunları kontrolsüz bir döngüye çevirmemek. Yani konu biraz mutfak robotu gibi. Bıçaklar var, karıştırıcı var, zamanlayıcı var… Ama kapağı açık unutursanız ortalık savaş alanına dönüyor.
Bu yazıda prompt merkezli düşünceden çıkıp biraz daha mimarı bir bakışa geçmek istiyorum. Kafamda tek bir soru vardı: Bir LLM’i gerçekten üretim ortamında kullanacaksak, önü nasıl “konuşkan. Uslu” hâle getiririz? Cevap kısa değil. Ama birkaç sağlam parça var ve hepsi birlikte çalışınca tablo ciddi biçimde değişiyor.
Neden Prompt Yetmiyor?
Eh, Basit chatbot ile agent arasında uçurum var. Ciddi bir uçurum. Chatbot soruya cevap verir; agent işe karar verir, araç çağırır, sonucu okur, gerekirse düzeltir ve tekrar dener. İşte tam burada stokastiklik devreye giriyor — modelin davranışı olasılıksal, yazılımın beklentisi işe deterministik. Aradaki bu boşluk, yani stochasticity gap, çoğu sistemin sessizce patladığı nokta.
Yani, Geçen sene Eylül 2024’te Berlin’de çalışan bir SaaS ekibinin loglarını inceleme fırsatım oldu. Agent aynı API aracını dört kez üst üste çağırıyordu; çünkü her seferinde önceki çıktıyı yeterince “kesin” bulmuyordu. Kullanıcı açısından sonuç sıfır. Sistem açısından maliyet şişmiş. Baya klasik, baya can sıkıcı.
Bir de şu var: LLM bazen aracı yanlış isimle çağırıyor. Bazen sayısal değer yerine metin yolluyor. Bazen de hiç veri almadan gayet özgüvenle cevap uyduruyor. Normal uygulamada bunların her biri bug’dır (ki bu çoğu kişinin gözünden kaçıyor). Agent dünyasında işe… nasıl desem… bunlar günlük ekmek gibi. Ne yazık ki.
Ve işler burada ilginçleşiyor.
Cognitive Loop Nedir, Ne İşe Yarar?
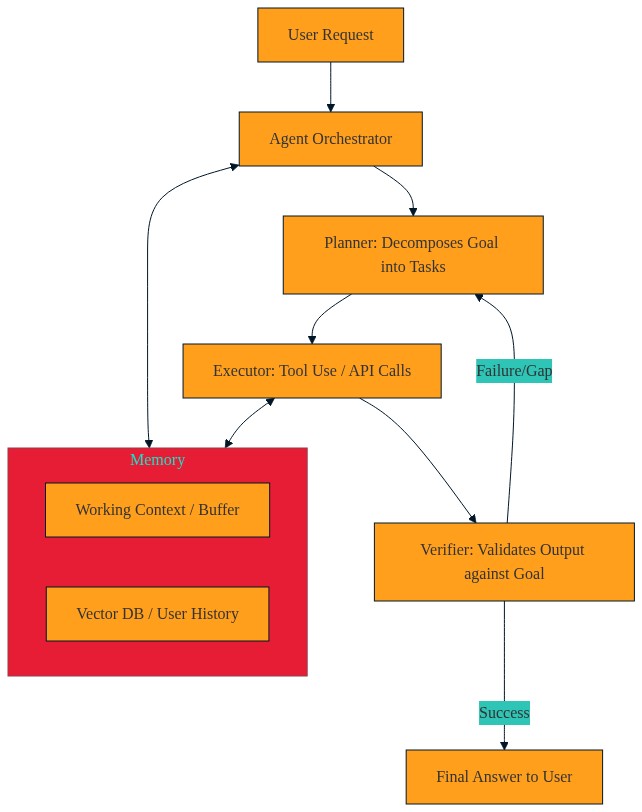
Şöyle söyleyeyim, Benim sevdiğim yaklaşım şu: LLM’i programın kendisi gibi değil, CPU’su gibi düşünmek (buna dikkat edin). Programın geri kalan kısmı hafızayı tutuyor, araçları seçiyor, izinleri denetliyor ve gerektiğinde frene basıyor. Böyle bakınca “tek atımlık prompt” fikri biraz bir düşüneyim… çocukça kalıyor. Evet, o kadar.
Burada en işe yarayan yapı Plan-Execute-Verify döngüsü. Önce planlama yapılıyor; sonra ilgili adım çalıştırılıyor; ardından ayrı bir doğrulama katmanı çıktının gerçekten işe yarayıp yaramadığına bakıyor. Bu üçüncü adım kritik, çünkü agent’lar — ve bunu gözlerimle defalarca gördüm — kendi hatalarını fark etmeden sonsuza kadar oyalanabiliyor.
Kendi testlerimde özellikle verifikasyon katmanını eklediğimde ilginç bir şey fark ettim: İlk anda başarı oranı sanki düşüyormuş gibi geliyor, çünkü sistem daha fazla kontrol yapıyor ve bazı istekleri geri çeviriyor. Ama birkaç gün sonra toplam kalite artıyor, kullanıcı şikayeti azalıyor ve gereksiz tool çağrıları ciddi biçimde düşüyor. Şaşırdım açıkçası, bu kadar net fark beklemiyordum (bizzat test ettim) PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
Açık konuşayım — bu yapı kağıt üstünde süper görünüyor ama pratikte küçük pürüzleri var. Verifier fazla sert olursa iyi cevapları da eler. Fazla gevşek olursa zaten kapıyı açık bırakmış oluyorsunuz. Yani iş biraz terazi ayarına benziyor.
Planlama katmanı neden kritik?
Araya gireyim: Planlayıcıyı ön beyin gibi düşünebilirsiniz, ama ben ona daha çok proje yöneticisi gözüyle bakıyorum. Gelen karmaşık isteği alıyor. Tahmin eder mısınız? Parçalara ayırıyor: veri çekme, karşılaştırma yapma, özetleme üretme gibi adımlara bölüyor. Bu konuyla ilgili Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza da göz atmanızı tavsiye ederim.
Aslında — hayır dür, daha doğrusu, Mesela kullanıcı “Son üç çeyrekte Nvidia ve AMD gelirlerini karşılaştır” dediğinde doğrudan cevap vermek yerine DAĞ benzeri bir görev ağacı kurmak çok daha sağlıklı. Çünkü aksi hâlde model tek API çağrısına takılıp kalabiliyor ya da gereksiz yere dolaşıp duruyor. Bitti. Başka açıklamaya gerek yok. Daha fazla bilgi için Apple, iWork’te Eski Maç Uygulamalarını Neden Sildi? yazımıza bakabilirsiniz.
Verifier neden göz ardı ediliyor?
Çünkü kimse ekstra katman koymayı sevmiyor. Herkes hızlı demo istiyor. Ama verifier olmadan agent’ın cevabına güvenmek giderek zorlaşıyor — bunu 2025 Şubat’ında Ankara’daki küçük bir fintech projesinde net gördüm. Ayrı doğrulama olmadan sistem yüzde yüz özgüvenle yanlış veri dönduruyordu. Evet, baya kötü.
Agent tasarımında asıl mesele modeli büyütmek değil; modeli sınırlar içinde tutmak.
Agentic Stack’in Dört Temel Parçası
Sağlam bir agent mimarisinde dört modül neredeyse omurga görevi görüyor: planner, tool registry, verifier ve memory manager/loop kontrolü. Bunlardan biri eksik olursa diğerleri işi toparlamaya çalışıyor, ama kusura bakmayın — o kadar da sihir yok ortada. Daha fazla bilgi için Çifte Ücretleri Bitiren Tasarım: Billing’de Üç… yazımıza bakabilirsiniz.
| Bileşen | Görev | Zayıf Nokta |
|---|---|---|
| Planner | İşi adımlara böler | Aşırı parçalama yapabilir |
| Tool Registry | Sadece ilgili araçları sunar | Kötü filtrelenirse araç bulunamaz |
| Verifier | Cevabı denetler | Sertse iyi çıktı eleyebilir |
| Memory Manager | Konteksti düzenler | Pis tutulursa halüsinasyon artar |
Tool registry tarafı özellikle önemli, çünkü modele bütün araçları aynı anda gösterince gürültü oluşuyor. Her şeyi masaya dökmek iyi fikir sanılıyor. Değil. Hani dolapta on iki çeşit tornavida varken hiçbirini seçememek gibi bir şey bu — ihtiyaca göre dinamik araç seti vermek hem token tasarrufu sağlar hem de seçim hatasını ciddi ölçüde azaltır. Linux 7.0 Geldi: Numara Değişti, Asıl Hikâye Başka yazımızda bu konuya da değinmiştik.
Memory manager tarafı da hafife alınıyor bence. Bilhassa uzun oturumlarda bağlam çöplüğe dönmeye başlıyor ve model geçmişte ne yaptığını unutuyor, ya da yanlış hatırlıyor — insanın kendine fazla güvenmesi gibi bir şey bu. Claude Code. Cursor tarzı araçlarda bellek yönetimi konuşulurken bunun niye bu kadar kritik olduğunu zaten görüyoruz; Claude Code ve Cursor Neden Unutur? AMFS ile Çözüm.
Küçük Startup ile Kurumsal Ölçek Arasında Fark Ne?
Küçük startup’ta en büyük cazibe hız. Kurumsalda işe hızdan çok kontrol aranıyor. Startup tarafında basit Plan-Execute-Verify akışıyla gayet yürüyebilirsiniz, çünkü kullanıcı sayısı az ve hata maliyeti sınırlı. Ama enterprise seviyede iş değişiyor — orada audit log gerekir, izin matrisi gerekir, fallback mekanizmaları gerekir, kısacası oyuncak prototip yetmez (buna dikkat edin)
Bunu 2024 Kasım’da İzmir’de danışmanlık verdiğim orta ölçekli bir ekipte bizzat yaşadım. Başlangıçta tek agent vardı ama üç hafta sonra yetkisiz tool erişimi yüzünden sistemi iki ayrı role bölmek zorunda kaldılar. Bu bana çok net bir şey öğretti: küçük ekipler basitliği sever, büyük ekipler öngörülebilirliği ister. Ve ikisi aynı şey değil.
- Küçük startup için avantaj: hızlı iterasyon ve düşük kurulum maliyeti.
- Küçük startup için dezavantaj: hata toleransı düşük olduğunda işler çabuk dağılıyor.
- Enterprise için avantaj: güçlü denetim ve güvenlik katmanları eklenebiliyor.
- Enterprise için dezavantaj: karmaşıklık artıyor ve geliştirme hızı düşüyor.
Tasarımı Sağlamlaştırmak İçin Pratik İpuçları
Lafı gevelemeden söyleyeyim: agent sistemlerinde ilk yapılacak şeylerden biri tekrar sınırı koymak. Aynı tool üç kez — kendi adıma konuşayım — başarısız olduysa kör inatla devam etmesin — alternatif yol denesin veya insan onayına geçsin. Aksi hâlde token tüketimi sessizce kanar. Gerçekten.
{
"max_retries": 3,
"allowed_tools": ["getUserData", "searchDocs"],
"verification_mode": "strict",
"fallback": "human_review"
}Aman ha, unutmayın: başka bir nokta da guardrail’lerin sade olması. Fazla kural koyarsanız model nefes alamaz. Hiç koymazsanız kendi kafasına göre dolaşır. İkisi de kötü, yani orta yol burada gerçekten işe yarıyor. Ben genelde önce dar kapsamlı başlıyorum, sonra gerçek trafik geldikçe kuralları genişletiyorum. Bu yaklaşım geçen yıl Ekim’de bir e-ticaret destek botunda baya zaman kazandırdı — ilk hafta yakaladığımız saçmalıkları ikinci haftada otomatik filtrelemeye çevirdik. Peki bunu neden söylüyorum? Fena değildi.
Neleri ölçmelisiniz?
- Aynı aracın kaç kez tekrarlandığı
- Döngünün ortalama kaç tür sürdüğü
- User-visible error oranı
- Verifier tarafından reddedilen yanit yüzdesi
- Maliyet / başarılı görev oranı — ciddi fark yaratıyor
Sıklıkla Atlanan Riskler ve Hayal Kırıklıkları
Beni en çok şaşırtan şeylerden biri şu oldu: bazı ekipler hâlâ agent’a insan muamelesi yapıp mantıklı davranmasını bekliyor (bu konuda ikircikliyim). Beklediğim kadar değildi diyeyim. Model bazen gayet düzgün başlayıp ortasında kendi hikâyesine sapabiliyor — o noktada problem “zekâ eksikliği” değil, kontrol eksikliği. Tamamen farklı şeyler bunlar.
Bence, Bir de performans meselesi var. Beş adımlı zincirde her adım yüzde doksan başarılıysa toplam başarı yaklaşık yüzde elli dokuza düşüyor. Kulağa teknik geliyor ama pratikte şu demek: zincir uzadıkça güven azalıyor. Bu yüzden kısa yol varsa kısa yolu seçmek gerekiyor — hatta bazen manuel müdahale otomasyondan daha ucuz çıkıyor. Garip ama gerçek.
Sıkça Sorulan Sorular
Agentic AI ile chatbot arasındaki fark nedir?
Chatbot genelde soru-cevap odaklıdır; agentic AI işe araç kullanır, plan yapar, sonucu denetler ve gerekirse yeniden dener. Yani pasif cevap veren sistemden aktif görev tamamlayan sisteme geçersiniz.
Prompt’u uzatmak neden yetmiyor?
Çünkü sorun çoğu zaman dil modeli kapasitesi değil, sistem tasarımıdır. Uzun prompt yalnızca talimat sayısını artırır; kontrol, doğrulama ve hata yönetimi getirmez.
Küçük projede verifier şart mı?
Eğer çıktı kullanıcıya doğrudan gidiyorsa evet, en azından hafif bir doğrulama katmanı şarttır. Çok karmaşık olmak zorunda değil; bazen birkaç deterministik kural bile büyük fark yaratır.
Tekrarlayan tool loop nasıl engellenir?
Retry limiti koyun, aynı aracın art arda kullanımını izleyin ve başarısız tekrar sonrası alternatif akış tanımlayın. Gerekirse insan onayına geçin; inat etmek pahalıya patlar.
Kaynaklar Ve İleri Okuma
İlgili okumalar olarak Agentic Kodlamada Yeni Kural Spec-Driven Dönemi Başlıyor, Claude’daki “Skills” Neden Prompt Değil Bağlam Tasarımıdır?, 2026’de Finans API’leri: MCP ve Agent Dönemi yazıları da iyi gider.
>

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.