Geçen ay, bir salı sabahı Kadıköy’deki editör masasında tam bu konuyu konuşurken kendimi gülümserken buldum. Claude Code’u kapatıyorsunuz, ertesi gün açıyorsunuz… ve sanki dün hiç yaşanmamış gibi davranıyor. Cursor tarafında da tablo çok farklı değil. Araçlar güçlü, evet. Ama hafızaları balık gibi — kısa, seçici ve biraz da nazlı.
İşin aslı şu: bu “unutkanlık” tek kişinin canını sıkmıyor. Takım çalışmasında daha da kötü bir hâl alıyor. Bir mühendis auth servisini debug ediyor, not alıyor, hatta bir iki çıkarım yapıyor; öbür mühendis pazartesi günü aynı duvara tosluyor. Benzer bir sahneyi 2023 sonbaharında Beşiktaş’ta küçük bir SaaS ekibiyle test ederken bizzat görmüşbüyük çoğunluk — herkes iyi niyetliydi. Ajanlar adeta ayrı adalarda yüzüyordu, birbirinden habersiz.
Ajanların hafızası neden bu kadar kısa?
Şimdi gelelim temel meseleye. Claude Code ya da Cursor gibi ajan tabanlı araçlar çoğu zaman o anki bağlamı iyi taşıyor ama kalıcı bilgi konusunda zayıf kalıyor. Yani kodu okuyorlar, dosyalar arasında geziyorlar, öneri veriyorlar… sonra oturum kapanınca her şey sıfırlanıyor. Bu durum bazen fayda bile sayılabilir; kirli belleği temizliyorsunuz sonuçta. Ama ekip işi büyüyünce dezavantaj ağır basıyor.
Bunu biraz açayım.
Ben bunu ilk kez kendi denemelerimde fark ettim. Geçen yıl Mart ayında Ankara’da uzaktan yürüttüğümüz bir projede, aynı repo üzerinde iki farklı ajan kurmuştuk — biri migration kararlarını çözmüş, diğeri üç saat sonra aynı konuyu yeniden keşfetmeye çalışmıştı ve bu ikinci ajan ilkinin vardığı sonuçtan tamamen habersizdi. Açık konuşayım, biraz sınır bozucuydu. Çünkü sorun aslında teknikten çok organizasyonel görünüyordu: Bilgi vardı ama dolaşmıyordu (ilk duyduğumda inanamadım)
Bu yüzden “ajan amnezisi” lafı boşuna söylenmiyor. Her yeni oturumda sıfırdan başlamak zorunda kalan sistemler insanlara sürekli tekrar yaptırıyor. Mesela bir servis neden kırılgan, hangi endpoint neden yavaşlıyor, deploy öncesi hangi uyarılar var… bunların hepsi ayrı ayrı anlatılıyor, yine de unutuluyor (yanlış duymadınız). Hani klasik ofis toplantısı gibi — biri çıkıp “bunu geçen hafta konuşmamış mıydık?” diyor ya… işte tam o his.
Tek kişilik kullanımda idare eder, takımda çuvallayabiliyor
Bireysel kullanımda bu eksikliği belki tolere edersiniz (bizzat test ettim). Küçük bir task açarsınız, birkaç komut çalıştırırsınız, iş biter gider. Ama beş kişilik ekipte? Orada iş değişiyor. Aynı hatanın üç kere incelenmesi zaman kaybı demek; bazen de para yakmak demek. Ciddi fark var.
Bir şey dikkatimi çekti: Küçük startup senaryosunda bu durum özellikle acı veriyor. Ekip zaten az kişiyle dönüyor, her saatin bir bedeli var (şaşırtıcı ama gerçek). Enterprise seviyede işe mesele güvenilirlik. Denetlenebilirlik oluyor — kim neyi ne zaman öğrendi, hangi bilgiye dayanarak karar verildi, kimin onayıyla ilerlendi? Bunları bilmeden ilerlemek pek sağlıklı değil.
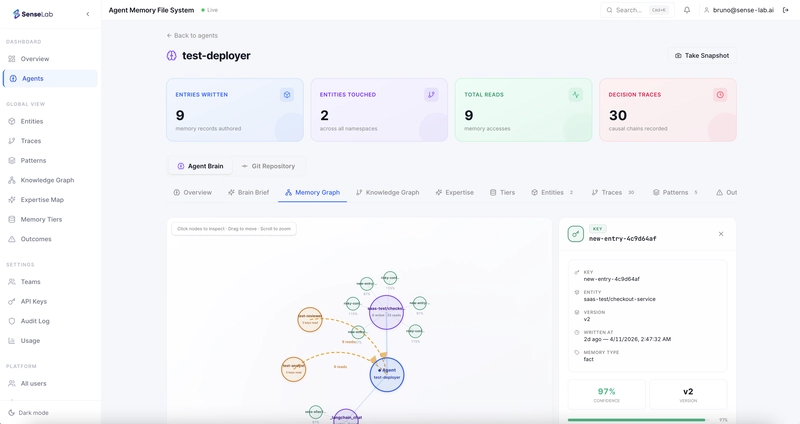
AMFS ne yapıyor da işleri toparlıyor?
AMFS’in fikri aslında bayağı net. Ajanların öğrendiği bilgiyi tek seferlik sohbet çıktısı olmaktan çıkarıp kalıcı hafızaya dönüştürüyor. Üstelik düz bir not defteri gibi değil — sürümlü kayıt sistemiyle çalışıyor ve her yazının arkasına “kim yazdı, hangi bağlamda yazdı” gibi izler bırakıyor.
Bana sorarsanız burada en önemli detaylardan biri provenance, yani köken bilgisi. Çünkü sadece “ne söylendi” yetmez; “kim söyledi”, “hangi görevde söyledi”, “sonuç doğru çıktı mı” kısmı da lazım ölür zamanla. Aksi hâlde hafıza bir süre sonra düzensiz wiki sayfalarına dönerdi — herkese açık, kimseye yararlı değil. Bu konuyla ilgili Roblox’ta Yaş Doğrulama: 9 Yaş Sınırı Neyi Değiştiriyor? yazımıza da göz atmanızı tavsiye ederim. Daha fazla bilgi için Roblox’ta Yaş Kilidi: Yeni Hesap Katmanları Ne Getiriyor? yazımıza bakabilirsiniz.
Çok konuştum, örnekle göstereyim. Daha fazla bilgi için PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza bakabilirsiniz.
Ajanların gerçekten işe yarayan hafızası varsa hız artar; yoksa aynı soru tekrar tekrar sorulur ve üretkenlik sessizce erir.
Eh, Sistemin hoş tarafı şu: bilgiyi yalnızca depolamıyor, aynı zamanda değerlendiriyor. Başarıyla biten işler bazı girdilerin güven skorunu yukarı çekiyor, başarısızlıkla sonuçlanan işlerse aşağı indiriyor. Yani ajan yanlış yaptığında sistem önü ödüllendirmiyor; tersine öğrenme kasını biraz geriyor. Güzel bir mekanizma bu.
Kopyala-yapıştır değil, versiyonlu hafıza
AMFS’in copy-on-write yaklaşımı burada kritik rol oynuyor. Önceki kayıt silinmiyor; yeni sürüm ekleniyor. Bu bana veri tabanı dünyasındaki temkinli yaklaşımı hatırlatıyor: bir şeyi dümdüz ezmek yerine geçmişini korumak daha akıllıca çoğu zaman, özellikle de “neden böyle karar verdik?” sorusunu ileride sormak zorunda kalacaksanız. Daha fazla bilgi için Apple’ın Akıllı Gözlüğü: Tasarımda Sessiz Devrim Yaklaşıyor yazımıza bakabilirsiniz. Daha fazla bilgi için Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza bakabilirsiniz.
Bi saniye — Neyse, uzatmayalım. Bu tasarımın pratik sonucu şu oluyor: sonradan geriye dönüp bakabiliyorsunuz.
| Özellik | Klasik ajan oturumu | AMFS destekli yapı |
|---|---|---|
| Bellek süresi | Oturum boyunca | Sürümlü ve kalıcı |
| Ekip paylaşımı | Zayıf / yok | Var |
| Köken takibi | Sınırlı | Ayrıntılı provenance |
| Ders çıkarma | Zor | Otomatik skor güncelleme ile daha kolay |
| Karmaşıklık | Düşük başlangıç eşiği | Daha fazla kurulum gerektirir |
MCP katmanı burada neden önemli?
MCP’yi kaba hâliyle şöyle düşünebilirsiniz: ajanın dış dünya ile konuştuğu standart kapı gibi davranıyor — bir tür adaptör. AMFS de bu kapıya bağlanınca Claude Code ya da Cursor fark etmeksizin aynı bilgi havuzuna erişebiliyor. Bu ne anlama geliyor? Basit fikir ama pratikte önemli (şaşırtıcı ama gerçek)
Editör masasında bunu ilk görünce hemen merak ettim doğrusu. Çünkü yıllardır tool entegrasyonlarında asıl darboğaz hep standardizasyon olurdu — farklı araçlar farklı format istedikçe süreç şişer, ortadaki adam yorulurdu. Hmm, bu sefer biraz daha temiz görünüyor en azından kâğıt üstünde (evet, doğru duydunuz)
Ajanın çağırdığı araçlar ne işe yarıyor?
- amfs_set_identity: Ajan kimliğini ve görevi kaydediyor.
- amfs_briefing: Oturum başında özet bilgi getiriyor.
- amfs_search: Hafızada hibrit arama yapıyor. (bence en önemlisi)
- amfs_read: Belirli bir kaydı okuyup kökenini koruyor.
- amfs_write: Yeni bilgiyi sürümlü biçimde yazıyor. (bence en önemlisi)
- amfs_commit_outcome: Görev sonucuna göre güven puanlarını güncelliyor.
Şöyle söyleyeyim, Bence en kullanışlı parça briefing mekanizması olabilir. Ajanın her sabah sıfırdan hayat hikâyesi anlatmasını engelliyor — hızlı başlama sağlıyor bu. Ama şunu da ekleyeyim: yanlış etiketlenmiş eski bilgilerle beslenirse briefing de yaniltıcı olabiliyor. Yani sihir değil bu. Çöp girerse çöp çıkar, klasik.
Peki gerçek hayatta nerede işe yarar?
Küçük startup tarafında fayda çok somut görünüyor çünkü ekip genelde hem ürün hem altyapı hem müşteri desteğini aynı anda taşıyor. Bir arkadaşım İzmir’de çalışan altı kişilik bir ekipte benzer mantığı manuel notlarla denemişti — sırf operasyon bilgisini canlı tutmak için bile ciddi vakit kazanmışlardı, haftalar içinde fark hissettirmişti. AMFS bunun otomatikleşmiş hâli gibi duruyor (inanın bana). Tabi kurulumu elle yapılacak kadar sade olmayabilir, önü da söyleyeyim.
Büyük kurumsal tarafta işe başka dertler devreye giriyor. Denetim izi gerekiyor mu? Verinin sınırı ne? Hangi ajan hangi bilgiye erişti? Burada AMFS’in read tracking yaklaşımı güzel görünüyor fakat güvenlik politikaları açısından hâlâ dikkat ister — metin kutusu değil sonuçta, veri katmanı olunca iş ciddileşir.
Peki eksisi yok mu?
Tabi var. İlk eksi karmaşıklık — her memory engine güzel görünür ama önü sisteme düzgün yerleştirmek ayrı bir uğraş. İkincisi yanlış güven hissi yaratma riski. Ajan geçmiş deneyime fazla yaslanırsa yeni durumu kaçırabiliyor. E tabi performans konusu da var: hibrit arama, graf ilişkileri, tiered storage kulağa hoş geliyor ama düşük bütçeli ortamda ekstra yük getirebilir. Kağıt üstünde süper. Tahmin eder mısınız? Pratikte ölçmeden konuşmak zor.
Benden çıkan pratik okuma listesi gibi düşünün
# Basit akış örneği
agent = "cursor-dev-17"
task = "auth-flaky-debug"
set_identity(agent_id=agent, current_task=task)
brief = amfs_briefing(entity_path="service/auth")
findings = amfs_search(query="flaky login", entity_path="service/auth")
write_entry(key="suspected_cause", value="token cache race condition", confidence=0.72)
commit_outcome(result="success")
print("Hafıza güncellendi")
Bilmem anlatabiliyor muyum, Böyle bir akışta asıl olay komut satırı değil, mantık düzeni bence. Sistem sadece cevap vermiyor — düşünülen şeyi saklıyor, üstüne bir de puanlıyor. Bunu 2024 sonunda kendi test ortamımda ilk kez gördüğümde şaşırdım açıkçası. Iyi kayıt tutulunca debugging refleksleri baya iyileşiyor, bu fark gerçek (kendi tecrübem)
Sıkça Sorulan Sorular
AMFS tam olarak nedir?
”
“AMFS, yapay zekâ ajanları için kalıcı bellek sağlayan açık kaynak bir memory engine’dür. Claude Code veya Cursor gibi MCP uyumlu istemcilere bağlanarak ortak bilgi havuzu oluşturur.”Takım içinde gerçekten paylaşılır mı?”
Evet, doğru kurulduğunda paylaşılan bellek olarak çalışır. Böylece farklı geliştiricilerin ajanları aynı dersleri tekrar tekrar keşfetmek zorunda kalmaz.”Güven skoru neden önemli?”
“Çünkü her bilginin değeri eşit değildir. Başarılı görevlerden gelen kayıtlar güçlenirken, hatalı tahminler zayıflar; böylece sistem zamanla daha isabetli hâle gelir.”Kaynaklar ve İleri Okuma
Model Context Protocol Resmî Sitesi

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



