Geçen ay İstanbul’daki bir fintech ekibinin test ortamında tam da bunu gördüm — ufak çaplı ama aynı hikâye. “Bağlantı zaman aşımı var, hadi max_connections’ı artırıp geçelim” dediler. Kulağa makul geliyor, değil mi? Ama işin aslı şu ki veritabanında bağlantı sayısını şişirmek çoğu zaman sorunu çözmüyor; tam tersine sistemi boğazına kadar tıkıyor, CPU %100’e vuruyor, disk kuyruğu uzuyor ve sonunda herkes birbirine bakıp kalıyor.
Bu konu bana hep market kasası örneğini hatırlatıyor. Dört kasanız var, dört kasiyer çalışıyor; insanlar sıraya girince iş akar gider. Ama 200 kişi aynı anda o dört kasaya abanırsa kasiyerler ürün okutmak yerine sürekli dönüp durur — ve kimse alışverişini bitiremiyor. Veritabanı da biraz böyle davranıyor. Aslında dür, şöyle anlatayım: sorun sadece “kaç kişi geldi” değil, o insanların aynı anda ne kadar gürültü çıkardığı.
Neden “daha çok bağlantı” ilk bakışta cazip geliyor?
Bakın şimdi, üretimde timeout görmek insanı hemen paniğe sürüklüyor. Uygulama loglarında hata akıyor, kullanıcılar bekliyor, yöneticiler de doğal olarak “limit artarsa rahatlarız” diye düşünüyor. Ben de 2023 yazında Ankara’da bir SaaS projesinde buna benzer bir tablo görmüştüm; ekip önce bağlantı limitini yükseltmek istedi, ama ölçüm yapınca mesele başka çıktı. Asıl darboğaz CPU değilmiş gibi görünüyordu — meğer context switching yüzünden işlemci nefes alamıyormuş. Şaşırdık açıkçası.
Evet, doğru duydunuz.
Burada küçük ama kritik bir ayrım var. Eşzamanlılık ile paralellik aynı şey değil. Veritabanınız 200 bağlantıyı kabul edebilir; bu onların 200 tanesini gerçekten verimli şekilde işleyebileceği anlamına gelmiyor. Hani kalabalık bir kafede tek barista varsa. Herkes aynı anda sipariş vermeye kalkarsa ölür ya — sistem var ama akış yok. İşte tam öyle.
Asıl suçlu kim? Context switching ve disk kavgası
İlk büyük bela context switching. CPU çekirdeği aynı anda tek işi gerçekten yapıyor; diğer işleri sırayla alıp bırakıyor (en azından benim deneyimim böyle). Siz 4 çekirdekli makinede 150-200 açık bağlantı tutarsanız işletim sistemi sürekli “şimdi bunu durdurayım… yok bunu başlatayım… cache’i temizleyeyim…” diye zıplayıp duruyor. Bu arada gerçek iş? Arka planda bekliyor işte.
Şunu fark ettim: Bazı sistemlerde bu geçişlerin maliyeti fena hâlde büyüyor — özellikle kısa sorgularınız varsa, mesela basit okuma işlemleri yapıyorsanız, CPU’nün hatırı sayılır kısmı işe değil bağlam değiştirmeye gidiyor. Bir projede bunu canlıda test ettiğimde (Mart 2024, Frankfurt’taki bir AWS kurulumunda) grafikte garip bir şey gördük: QPS artarken latency de artıyordu. Normalde tersini beklersiniz. Ama fazla bağlantıda resmen kendi kuyruğunuzu yiyorsunuz.
İşin garibi, İkinci bela disk tarafında çıkıyor. Veritabanları sıralı okumayı seviyor; SSD bile olsa düzenli erişim daha iyi — bence çok yerinde bir karar —. Fakat yüzlerce bağlantı aynı anda okuma-yazma yapmaya başlayınca desen bozuluyor ve işler rastgele I/O’ya kayıyor — disk kuyruğu şişiyor, buffer cache etkisini kaybediyor, sonra performans düşüşü domino taşı gibi geliyor.
Şimdi gelelim işin can alıcı noktasına.
| Senaryo | Küçük yük | Aşırı bağlantı | Sahadaki etki |
|---|---|---|---|
| CPU | Dengeli kullanım | Sürekli context switching | %100’e yaklaşan kullanım ama az iş |
| Disk | Sekansiyel erişim | Rastgele I/O baskısı | Kuyruk uzar, gecikme artar |
| Cache | Etkili hit oranı | Sık bozulan yerleşim | Daha çok miss, daha çok bekleme |
| Kullanıcı deneyimi | Sorunsuz akış | Zaman aşımı ve donma hissi | Müşteri memnuniyeti düşer |
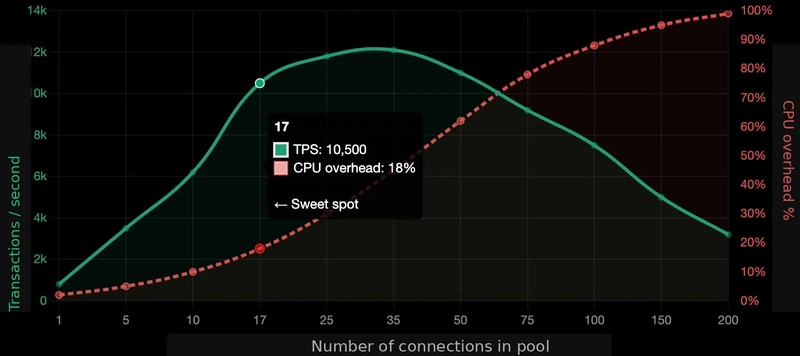
“Daha fazla bağlantı” çoğu zaman “daha fazla kapasite” demek değildir; bazen sadece daha fazla sıra demektir.
Peki doğru sayı ne? Her makine için ayrı hesap lazım mı?
Klasik formüller burada işe yarıyor gibi görünse de sihirli değnek değiller. Mesela şu kaba yaklaşımı duymuşsunuzdur: (çekirdek × 2) + disk sayısı benzeri etkenler. Evet, fikir veriyor ama tek başına kutsal metin değil. Çünkü uygulamanızın sorgu tipi, transaction uzunluğu ve cache davranışı sonucu büyük ölçüde değiştiriyor.
# Basit düşünme modeli
# Düşük gecikmeli OLTP sistemleri için:
önerilen_bağlantı = (cpu_çekirdeği * 2) + etkin_disk_katkısı
# Ama pratikte şunlara da bak:
# — Sorgular kısa mı uzun mu?
# — Transaction'lar açık mı kalıyor?
# — Read/write oranı nasıl?
# — Uygulama tarafında connection leak var mı?
Açık konuşayım, “tek satırlık formül” sevenlere biraz temkinli yaklaşıyorum ben. Çünkü kurumsal tarafta iki sunucu da aynı görünür ama biri ödeme trafiği taşır, diğeri raporlama yapar; biri kısa sorgu döndürürken öbürü ağır join’lerle sürünür (kendi tecrübem). Aynı limit ikisine de uymaz. Bu kadar basit.
Ve işler burada ilginçleşiyor. Bu konuyla ilgili Asus ROG Xbox Ally: Windows Cebinde Ne Kadar Rahat? yazımıza da göz atmanızı tavsiye ederim.
Küçük startup ile enterprise arasında fark ne?
Bilmem anlatabiliyor muyum, Küçük bir startup’ta genelde işler daha yalındır. Birkaç servis var, trafik yeni yeni büyüyor ve sorun çıktığında elle müdahale etmek mümkün oluyor. Böyle ortamlarda connection limitini abartmadan tutmak çoğu zaman yeterli — karmaşıklık düşük, yönetilebilir.
Kurumsal projede işe manzara değişiyor. Orada onlarca mikroservis var, her biri kendi pool’unu açmış durumda ve siz fark etmeden toplam bağlantı sayısı patlıyor. Bir bankacılık projesinde buna benzer bir yapı gördüğümde en komik şey şuydu: uygulama katmanındaki her servis kendini “ufak tefek” sanıyordu ama toplamda veritabanını traktörle eziyorlardı. Kimse farkında bile değildi.
Vallahi, İşte burada proxy veya pool yönetimi devreye giriyor (buna dikkat edin)
PgBouncer ve RDS Proxy neden bu kadar önemli?
Şöyle söyleyeyim, Neyse uzatmayalım — modern mimaride çözüm genelde veritabanının önüne akıllı bir katman koymak oluyor. PgBouncer ya da RDS Proxy gibi araçlar binlerce uygulama bağlantısını alıp arkada sınırlı sayıda gerçek DB oturumuna çeviriyor (inanın bana). Yani uygulamalar konuşuyor gibi görünüyor ama arkadaki çekirdek kaynak kontrollü kullanılıyor. Daha fazla bilgi için Ambulanslar Neden Çevrildi: Hastaneyi Vuran Siber Saldırı yazımıza bakabilirsiniz.
Açık konuşayım, Bunu otobüs terminali gibi düşünebilirsiniz: yolcu sayısı çok olabilir. Perona çıkan otobüs sayısı sınırlıdır. Her yolcunun kendi otobüsü olursa kaos çıkar — hem yakıt biter hem alan yetmez hem de trafik kilitlenir. Proxy tam olarak bu kaosu azaltıyor.
- PgBouncer: PostgreSQL tarafında hafif ve yaygın bir çözüm.
- RDS Proxy: AWS kullanan ekiplerde yönetimi kolaylaştırıyor. — ciddi fark yaratıyor
- Uygulama pool’u: TCP yeniden kullanım sağlıyor ama ana yükü tek başına çözmüyor.
Küçük bir detay: Ha bu arada küçük bir hayal kırıklığını da söyleyeyim. Proxy kullanınca her şey otomatik mucize olmuyor. Bazı transaction modlarında session pinning yüzünden beklediğiniz kadar yüksek kazanç alamıyorsunuz — kağıt üstünde süper, pratikte “göreceğiz artık” dediğiniz yer tam burasıdır işte.
Nerede parlıyorlar?
Eğer serverless mimarı kullanıyorsanız ya da mikroservisleriniz anlık patlamalar yaşıyorsa proxy hayat kurtarıyor diyebilirim. Çünkü app instance’ları gelip gidiyor; DB işe sabırlıdır ama sonsuz sabırlı değil. Bu araçlar özellikle connection storm dediğimiz anı saldırılarda sistemi ayakta tutuyor.
E tabi madalyonun öbür yüzü de var. Yanlış konfigüre edilmiş proxy bazen gizli darboğaz hâline geliyor. İzleme koymazsanız problemi sadece başka yere taşımış olursunuz — bu da pek iç açıcı değil. Bu konuyla ilgili Oppo’dan lüks saat hamlesi: Watch X3 Mini geliyor yazımıza da göz atmanızı tavsiye ederim.
Tuning yaparken nelere bakmalı?
Bi saniye — Lafın özü şu ki yalnızca max_connections’a bakmak yetmiyor. Ben olsam önce şu üç şeye göz atarım: aktif connection sayısı mı yüksek yoksa idle connection mu dolmuş? Uzun transaction var mı? Ve sorgular gerçekten yavaş mı yoksa sadece kuyruk mu oluşmuş?
- IDLE oturumları temizleyin: Boşta duran bağlantılar kaynak yiyor.
- Sorguları kısaltın: Büyük transaction zincirini kırın.
- I/O izlemesi yapın: Disk mı sınırda CPU mu sınırda, önce bunu anlayın.
- Aynalama yerine ölçüm: Tahmin ederek limit artırmayın.
Bence en sağlıklı yaklaşım önce gözlemlemek, sonra ayarlamak. Mesela pg_stat_activity, slow query log, OS seviyesinde vmstat, iostat gibi araçlar size hangi katmanın can çekiştiğini gösteriyor. Bunları görmeden yapılan her değişiklik biraz kumar — ve genellikle evi kaybeden siz oluyorsunuz.
Bana göre asıl ders ne?
Editör masasında bu konuyu ilk not aldığımda aklıma hemen eski usul su borusu analojisi geldi. Boruya suyu fazladan basarsanız debi artmıyor; tersine basınç yükseliyor ve sistem çatlıyor. Veritabanında da aynısı oluyor — daha çok giriş kapısı açınca binanın içine daha çok hava girmiyor. Aksine, kapı kalabalığı yaratıyorsunuz.
Mesele şu dengeyi bulmakta yatıyor bence: veritabanını hardware’in kaldırabileceği paralellik seviyesine göre şekillendirmek, uygulama katmanını gereksiz yere cömert davranmaktan vazgeçirmek ve gerektiğinde proxy ile tampon oluşturmak (bizzat test ettim). Çok kaba tabirle söylersem — az ama öz bağlantılar çoğu zaman daha iyi çalışıyor. Deneyin, görün.
Sıkça Sorulan Sorular
Neden fazla database connection performansı düşürür?
Size bir şey söyleyeyim, Çünkü CPU sürekli thread/connection arasında geçiş yapar ve gerçek işe daha az zaman kalır. Üstüne disk I/O karmakarışık hâle gelirse gecikme hızla büyür. Kısacası kapasite artmış gibi görünür ama sistem yorulur.
HelloWorld seviyesinde kaç connection normaldir?
Bunun tek cevabı yok; iş yüküne bağlıdır. Küçük bir API için onlarca bağlantı yeterliyken yoğun OLTP sistemlerinde dikkatle ayarlamak gerekir. En doğrusu ölçerek gitmektir.
PgBouncer her zaman gerekli mi?
Hayır, her senaryoda şart değil. Ama mikroservisleriniz çoksa veya serverless kullanıyorsanız ciddi fayda sağlar. Mesela de anı trafik sıçramalarında sistemi sakın tutar.
Aşırı connection yerine neyi optimize etmeliyim?
IDLE oturumları azaltın, uzun transaction’ları bölün, yavaş sorguları düzeltin. Indeksleri kontrol edin. Sonra OS seviyesinde CPU ile I/O takibini birlikte okuyun. Tek metrikle karar vermek genelde yaniltır.
Kaynaklar ve İleri Okuma
PostgreSQL Resmî Dokümantasyon — Connection Ayarları
AWS RDS Proxy Resmî Dokümantasyonu
İlgili okuma için ayrıca şu yazılara da göz atabilirsiniz:
Python JSON’da RAM Şişmesi: 2 GB’ı Nasıl Erittim?,
AI Kodunda Güvenlik Tuzağı Node.js İçin Sert Kurallar,
Windows 11’de Gizli Alanı Geri Almak Reserved Storage Rehberi.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.