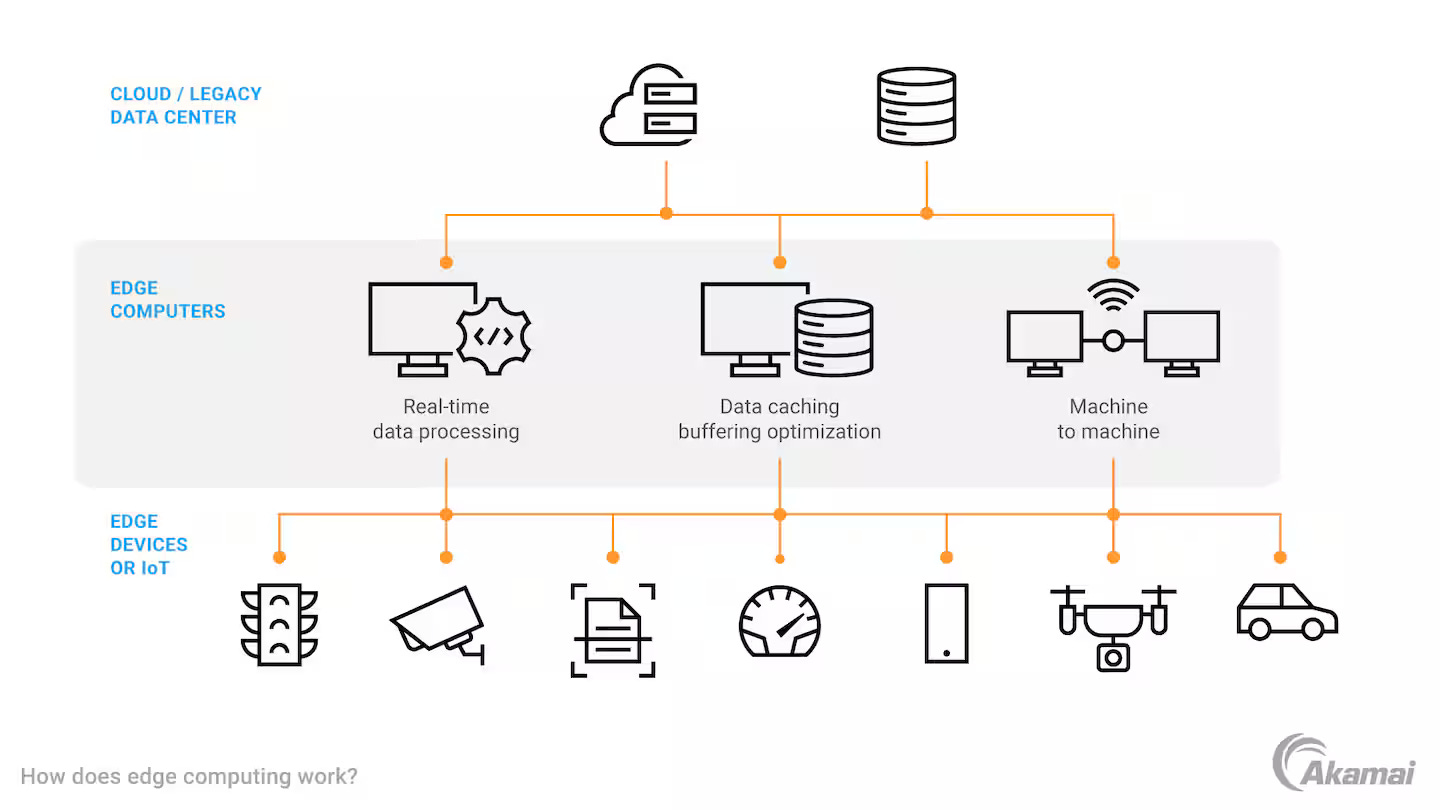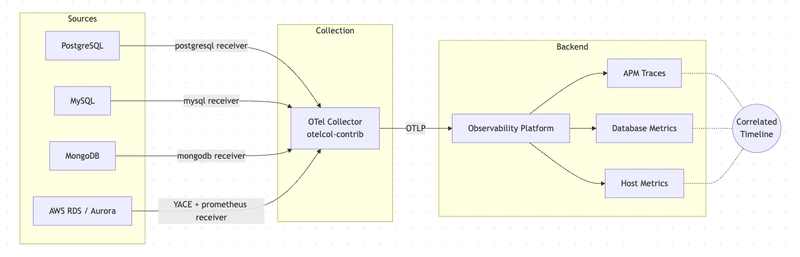
Küçük bir detay: Geçen ay İstanbul’da bir ekip toplantısındaydım. Yine o cümle: “Grafikler var ama neden yavaşladığını kimse söyleyemiyor.” Hmm, biliyorum bu his’i. Veritabanı tarafında sorun çoğu zaman tek bir alarmla gelmiyor çünkü — MySQL ayrı bir şey söylüyor, PostgreSQL başka bir hikâye anlatıyor, MongoDB Atlas işe bambaşka bir ekrandan göz kırpıyor, sanki birbirleriyle konuşmuyorlar hiç. Ortada veri var gibi duruyor ama aralarında ilişki yok. İşte problem tam da bu.
Ben buna yıllardır “üç panelli körlük” diyorum. 2023’te Ankara’daki küçük bir SaaS projesinde bunu birebir yaşadık — uygulama tarafında hata görünmüyordu, CloudWatch sakın, Prometheus yarı uykuda; meğer p99 gecikme yavaş yavaş şişiyormuş. Kullanıcılar sayfayı yeniliyor, sistem işe “ben iyiyim” havasında geziyordu. Sonunda bir missing index yüzünden geceyi sabaha bağladık. Eğlenceli değildi.
Bir dakika — bununla bitmedi.
Database observability dediğimiz şey de zaten burada devreye giriyor. Sadece eşik aşınca öten alarmlar değil; sorgu süresi, bağlantı baskısı, cache hit oranı, disk I/O ve uygulama davranışını aynı hikâyede buluşturmak lazım. Yani lafı gevelemeden: ölçmek başka şey, anlamak başka şey.
Neden klasik izleme yetmiyor?
Klasik monitoring genelde şunu yapıyor: CPU yükseldi mi? Disk doldu mu? Bağlantı sayısı arttı mı? Tamam güzel. Ama bu soruların hiçbiri tek başına “neden” sorusuna cevap vermiyor — veritabanlarında asıl dert çoğu zaman birkaç sinyalin birlikte bozulmasıdır, mesela bağlantılar artarken cache hit düşüyor, arkasından p95/p99 fırlıyor. Sen hâlâ hangi dashboarda bakacağını bilemiyorsun.
Bir de şu var. Farklı veritabanları farklı dil konuşuyor. PostgreSQL’in istatistik sistemi ile MySQL’in statüs — ki bu tartışılır — değişkenleri aynı mantıkta değil; RDS ya da Aurora kullanıyorsanız üstüne bulut sağlayıcısının kendi metriklerini de ekliyorsunuz. Sonuç? Tek bakışta görülemeyen bir karmaşa.
Geçen sene Berlin’de uzaktan çalıştığım bir fintech ekibiyle yaptığım incelemede bunu net gördüm. Dört ayrı dashboard vardı ve her biri kendi başına düzgün görünüyordu — güzel renkler, yeşil ışıklar, her şey tamamdır havası. Ama ödeme akışı yavaşlayınca kök neden bulmak için 20 dakikadan fazla ekran değiştirdik. Açık konuşayım, o an grafikler bilgi değil gürültü üretiyordu.
Gözlemlenebilirlik sadece metrik toplamak değildir; metrikleri birbirine bağlayıp olayın zincirini kurabilmektir.
Hangi sinyaller gerçekten işe yarıyor?
Size bir şey söyleyeyim, Bak şimdi… yüzlerce metriğe bakıp kafayı yemek çok kolay. Pratikte işe birkaç tanesi işi kurtarıyor. Benim sahada en çok baktığım dört başlık var: gecikme dağılımı, bağlantı baskısı, cache sağlığı ve I/O davranışı. Hepsi. Bu kadar.
1) Latency dağılımı
Ortalama latency çoğu zaman aldatır. p50 iyi görünüyor diye sevinirsiniz ama p99 çığlık atıyorsa gerçek kullanıcı deneyimi zaten bozulmuştur — özellikle e-ticaret veya finans tarafında birkaç saniyelik sapma bile, kullanıcı yenile butonuna ard arda basmaya başladığında, sistemi retry fırtınasına sürükleyebilir ve işler katlanarak kötüleşir.
2) Bağlantı sayısı ve limit ilişkisi
Bak şimdi, PostgreSQL’de numbackends ile max_connections karşılaştırılır; MySQL tarafında Threads_connected ile max_connections ilişkisine bakılır. Ama mesele sadece limiti aşmak değil (ki bu çoğu kişinin gözünden kaçıyor). Limite yaklaşırken kuyrukların büyümesi de sıkıntıdır. Ciddi sıkıntı.
3) Cache hit oranı
Cache hit oranını düşük görmek bazen doğrudan tablo tasarımına işaret eder, bazen de yanlış sorgu desenine — nasıl desem, ikisini birbirinden ayırt etmek zor oluyor ilk bakışta (ki bu çoğu kişinin gözünden kaçıyor). PostgreSQL’de yüzde 95 altını ben riskli kabul ediyorum; yüzde 99 civarı daha rahat hissettiriyor, tabii iş yüküne göre değişir. MySQL/InnoDB tarafında buffer pool’un ne yaptığına dikkat etmek lazım. Xiaomi 18 Pro Sızdı: Leica Kamerada Oyun Değişiyor yazımızda bu konuya da değinmiştik. CISA’dan Ivanti EPMM Uyarısı: Hafta Sonu Bitmeden Yama yazımızda bu konuya da değinmiştik.
4) Disk I/O ve bekleme süreleri
Bir kez İzmir’deki bir lojistik projesinde şöyle bir şey yaşadım: indeks eksikliğini fark etmeden önce diskin küçük rastgele okumalarda nefes nefese kaldığını gördüm, sistem suçu uygulamaya atmıştı ve herkes birbirine bakıyordu. Sorgu iyi yazılmış olabilir. Altyapının alt katmanı sürünüyorsa — özellikle yoğun yazma alan sistemlerde — bunu bulmak vakit alıyor.
| Sinyal | Neyi gösterir? | Kötüleşince ne ölür? |
|---|---|---|
| P99 latency | Kullanıcının hissettiği uç gecikmeler | Zaman aşımı ve retry artışı |
| Aktif bağlantılar | Baskı seviyesi | Kuyruklanma ve kilitlenme riski |
| Cache hit ratio | Bellek verimliliği | Daha fazla disk erişimi |
| I/O wait | Saklama katmanındaki tıkanıklıklar | Tüm isteklerin ağırlaşması |
SQL, NoSQL ve cloud database aynı sepette nasıl okunur?
Vallahi, Küçük bir startup için durum genelde daha basit — tek ana veritabanın var, olayları nispeten hızlı bağlıyorsun. Ama büyüdükçe tablo değişiyor. Bir gün PostgreSQL ana işlemci olurken ertesi hafta MongoDB yan koleksiyonları taşır hâle geliyor, sonra RDS gelip masaya oturuyor ve herkes biraz farklı dashboard istiyor. Tanıdık geldi mi? Day Öne’ın Yeni Gold Planı: Yapay Zekâ Günlük Tutmayı Değiştiriyor yazımızda bu konuya da değinmiştik.
NoSQL tarafında semantik biraz kayıyor çünkü “slow query” kavramını SQL kadar düz okuyamıyorsun. MongoDB Atlas güzel telemetri veriyor. Orada da şunu sormak lazım: replikasyon gecikmesi mi var yoksa uygulama deseni mi kötü? İkisi çok farklı dertler.
Kurumsal projelerde ben genelde şöyle ilerliyorum:
- Uygulama katmanı için trace topluyorum; — ciddi fark yaratıyor
- Baz seviyesinde sorgu örneklerini açıyorum; (bu kritik)
- Bulut sağlayıcısının native metriklerini ayrı tutmuyorum;
- Aynı olay için tek alarm yerine korelasyon kuralları kuruyorum.
Küçük ekipte öncelikler
Yani, Ekip üç-beş kişiyse detaylı APM kurmadan önce temel sağlık sinyalleri yeterli olabilir. Her tabloya distributed tracing dökmek zorunda değilsiniz. Bazen sade panel daha iyi çalışıyor çünkü kimse ikinci monitörde kaybolmuyor — bu küçük ama önemli bir fark.
Enterprise tarafta iş büyür
Büyük organizasyonda işe veritabanı katmanı yalnızca teknik konu değil; maliyet konusu da oluyor, güvenlik konusu da oluyor, operasyon konusu da oluyor —. Hepsi aynı anda patlamayı seviyor, Murphy yasası bu işte. Orada RBAC olmadan veri toplamak riskli, ayrıca log saklama politikası yoksa inceleme yapmak neredeyse imkansız hâle geliyor.
Korelasyon olmadan observability eksik kalır mı?
Aslında, Kısacası evet. Hem de bayağı eksik. Tekil metrikler sadece semptom verirken korelasyon size hikâyeyi anlatıyor:
# Basit korelasyon mantığı
if p99_latency > threshold and active_connections > connection_limit * 0.8:
check_slow_queries()
inspect_index_usage()
review_disk_io()
else:
watch_cache_hit_ratio()Bunu ilk kez kendi test ortamımda denediğimde şunu fark ettim: en faydalı uyarılar en parlak grafikten gelmiyor. İki-üç zayıf sinyalin aynı anda kıpraşmasından geliyor. Mesela bağlantılar normal görünürken cache hit düşüyorsa altında sessizce büyüyen bir regresyon olabilir. Ya da tam tersi — latency sıçrar ama CPU yerinde sayar. İşte o an şunu soruyorsunuz: darboğaz nerede? Daha fazla bilgi için PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza bakabilirsiniz.
E sonra? Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik.
İnanın, Cevabı bulmak için tek grafik yetmiyor (ki bu çoğu kişinin gözünden kaçıyor). Yetmez.
Peki nasıl başlanır?
Neyse, uzatmayalım. İyi haber şu ki sıfırdan mükemmel sistem kurmanız gerekmiyor — zaten kimse kuramıyor, dürüst olalım. Önce en can alıcı veritabanlarını seçin, sonra her biri için ortak birkaç KPI belirleyin (buna dikkat edin). Ben olsam şu sırayla giderdim:
- P99 latency’yi ölç;
- Aktif bağlantıları izle;
- Error rate ile slow query log’u eşleştir;
- Bulut servislerinin native metric setini merkezî sisteme çek;
- Daha sonra trace ve event correlation ekle.
Bugün editör masasından bakınca bana en mantıklı yol hâlâ bu geliyor. Herkesin hayalî tüm dünyayı izlemek oluyor ama pratikte ihtiyacınız olan şey yalnızca doğru anda doğru şeyi görmek — kulağa basit geliyor, uygulamak işe bambaşka bir iş.
Hmm, bunu nasıl anlatsamdı…
Bir arkadaşımın Frankfurt’taki şirketinde bunu kurduklarında ilginç biçimde alarm sayısı azaldı fakat incident çözme süresi yarıya indi. Düşünün bunu. Daha az gürültü, daha hızlı çözüm.
Bu küçük fark büyük para demek oluyor.
Evet, ciddi söylüyorum.
Sıkça Sorulan Sorular
Database observability ile monitoring arasındaki fark nedir?
Monitoring size belirli eşikleri gösterir; observability işe olayların nedenini anlamaya yardım eder.
Yani biri “ne oldu?” derken diğeri “neden oldu?” sorusunu hedefler.
P99 latency neden bu kadar önemli?
P99 ortalama kullanıcı deneyimini değil uç vakaları gösterir.
Gerçek sıkıntılar çoğu zaman o uç vakalarda ortaya çıkar çünkü timeout ve retry zinciri oradan başlar.
Küçük ekipler de observability kurmalı mı?
Evet, ama abartmadan.
Önce birkaç kritik metrikle başlayın; sonra ihtiyaç varsa trace ve log korelasyonu ekleyin.NoSQL veritabanlarında hangi sinyaller önemlidir?Latenzy dağılımı, replika gecikmesi, write amplification ve bellek/disk dengesi önemli.
Servise göre ayrıntılar değişir ama temel fikir aynıdır: kullanıcıya etkisi olan noktaları takıp edin.
}
Kaynaklar ve İleri Okuma
Azure Well-Architected Framework: Observability
Azure Monitor Metrics (metrikler)
OpenTelemetry Specification (gözlemlenebilirlik için standart)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.