Açık konuşayım, Geçen ay, Şubat 2026’da bir editör toplantısında tam bu konuyu anlatırken fark ettim bir şeyi: insanların kafası genelde “attention” kelimesinde takılıyor. Sanki model, cümledeki her şeyi aynı anda aynı sertlikte dinliyormuş gibi bir his var. Oysa self-attention biraz daha kurnaz — her kelimeye aynı gözle bakmıyor, kimi öne çıkarıyor, kimini fon müziği gibi arka planda bırakıyor. Yani seçiyor. Ayırt ediyor.
Ben ilk kez 2019’da küçük bir NLP projesinde attention mantığıyla uğraşmıştım. O zamanlar elimizdeki veri seti çok büyük değildi, ama yine de modelin “it” zamirini doğru yere bağlamaya çalıştığını görmek — hani, o küçük başarıyı izlemek — bayağı etkileyiciydi açıkçası. İnsan okuyunca doğal gelen şey, makine için o kadar da doğal değilmiş meğer (ciddiyim). Bilhassa uzun cümlelerde… iş biraz çorba oluyor. Duraksıyorum burada. Çünkü “biraz” demedim aslında, epey çorba oluyor.
Self-attention neyi çözüyor?
Tuhaf ama, Transformer mimarisinin en sevdiğim tarafı şu: kelimeleri yalnızca tek tek işlemiyor, aralarındaki ilişkiye de bakıyor (ki bu çoğu kişinin gözünden kaçıyor). Anlam çoğu zaman (belki yanilıyorum ama) tek bir kelimenin içinde saklı değil; yanindaki komşularla birlikte şekilleniyor, olgunlaşıyor, hatta bazen tamamen değişiyor. Mesela “The pizza came out of the öven and it tasted good.” cümlesinde “it” kime gidiyor? Pizza’ya mı, fırına mı? İnsan için cevap apaçık. Ama model için bu bağı çözmek ciddi iş.
Burada self-attention devreye giriyor. Diyor ki: “Tamam, bu kelimeyi alalım — ama önce etrafındakilerle olan bağını ölçeyim.” Bu ölçüm sayesinde her token, diğer token’lara ne kadar yakın durduğunu öğreniyor. Sınıf içindeki dedikodu ağı gibi düşünün; herkes herkesi tanıyor ama herkesin sözü aynı ağırlıkta değil. Bazıları daha güçlü, bazıları neredeyse yok hükmünde.
Peki neden?
Self-attention’ın gücü, kelimeleri sırayla ezberlemesinden değil; ilişkileri anlık olarak tartmasından geliyor.
Bu yüzden transformer’lar çeviri, özetleme ve soru-cevap sistemlerinde eski yöntemlere göre daha esnek davranabiliyor. Kusursuz mu? Hayır. Bazen gereksiz yere uzak ilişkileri fazla önemseyip saçma sonuçlar üretebiliyorlar — kağıt üstünde şahane duran sistemlerin pratikte tökezlediğini ben özellikle kurumsal doküman arama projelerinde çok gördüm, hem de birden fazla kez.
Kelimeler birbirini nasıl “duyar”?
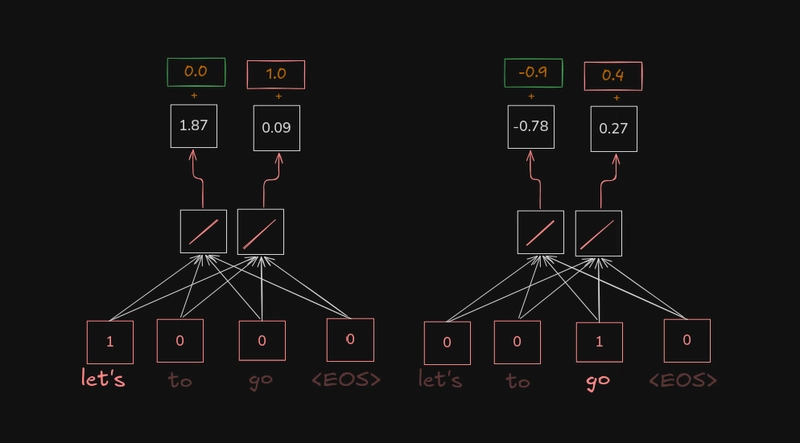
Yani, Düz anlatayım. Her kelime önce sayısal bir vektöre dönüşüyor. Sonra bu vektörler üzerinden hangi kelimenin hangisine daha çok baktığı hesaplanıyor. Burada üç temel parça var: Query, Key ve Value. İsimleri biraz laboratuvar kokuyor, kabul, ama mantık basit — biri soru soruyor, biri cevap anahtarını taşıyor, diğeri de taşınacak bilgiyi veriyor. Siz ne dersiniz? Bu kadar.
Bunu geçen yıl Kasım ayında İstanbul’da bir atölyede anlattığımda katılımcılardan biri “Yani Google araması gibi mi?” diye sordu. Fena benzetme değil aslında, ama tam da öyle değil. Aramada siz dışarıdan sorgu yollarsınız; self-attention’da işe sistem kendi içinde sürekli mini eşleşmeler yapar. Model kendi kendine bakıyor yani. Adından da belli zaten — “self.”
İşte tam da bu noktada devreye giriyor.
Query-Key-Value mantığı
Eh, İşin özünü anlamak için küçük bir örnek yeterli olabilir:
Kelime A → Query üretir
Kelime B → Key üretir
Kelime C → Value taşır
A ile B arasındaki benzerlik hesaplanır.
Bu skor yüksekse C'nin katkısı artar.
Kulağa kuru geliyor, biliyorum. Ama epey işlevsel bir akış bu. Mesela “it” zamiri pizza’ya dönüyorsa pizza’nın value’su daha baskın hâle geliyor; model sonraki katmanlarda daha doğru temsil üretiyor. Ben bunu ilk kez denediğimde şaşırmıştım — sistem bazen beklediğimden iyi çalışıyordu, bazen de hiç ummadığım yere sapıyordu. İşte tam o noktalarda insan gözü gerekiyor. Kaçınılmaz. Daha fazla bilgi için OpenAI’nın 100 Dolarlık Codex Paketi: Kimler İçin? yazımıza bakabilirsiniz.
Neden positional encoding hâlâ önemli?
Bence, Self-attention’ın küçük bir açmazı var: sıralamayı doğrudan bilmezse karışabiliyor. Dikkat mekanizması ilişkilere odaklanırken dizilim bilgisini kaybedebiliyor — ve bu ciddi sorun. Positional encoding tam burada devreye giriyor; modele “bu kelime birinci sırada, şu ikinci sırada” demenin zarif yolu. Bu konuyla ilgili Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza da göz atmanızı tavsiye ederim.
Ve işler burada ilginçleşiyor. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
Ne yalan söyleyeyim, Embedding ile positional değerleri birlikte kullanmak bu yüzden anlam kazanıyor. Yalnızca anlam vektörü verirseniz model güzel ama hafızasız ölür; yalnızca sıra verirseniz anlamsız bir tablo çıkar ortaya. İkisini birlikte verince taşlar yerine oturuyor… çoğu zaman. “Çoğu zaman” kısmını atlamamak lazım.
| Bileşen | Ne yapar? | Neden gerekli? |
|---|---|---|
| Embedding | Kelimelerin anlamını sayısallaştırır | Sözlük bilgisini taşır |
| Positional Encoding | Kelimelerin sırasını ekler | Cümlenin dizilimini korur |
| Self-Attention | Kelimeler arası bağı ölçer | Anlam ilişkisini güçlendirir |
Peki model neden bazen yanilıyor?
Açık konuşayım: self-attention sihir değil. Güçlü, evet — ama bir o kadar da nazlı olabiliyor. En çok da uzun metinlerde dikkat dağılıyor gibi davranabiliyor; bazı detayları gereğinden fazla büyütürken kritik ipuçlarını kaçırabiliyor (bizzat test ettim). Ben bunu 2024 yazında Ankara’daki bir müşteri projesinde bizzat yaşadım — sözleşme maddelerini sınıflandıran prototipimiz kısa metinlerde gayet iyi giderken uzun belgelerde tuhaf biçimde dalgalandı. Açıklaması yoktu, sadece dalgalanıyordu.
Neden? Çünkü ilişki kurma kapasitesi yüksek olsa bile veri kalitesi düşükse sonuç yine orta halli çıkıyor. Beklediğim kadar iyi çıkmadı derim bazı projelerde — özellikle domain’e özgü terimler varsa model onları yanlış bağlayabiliyor ya da fazla önem atfedebiliyor. Hmm, nasıl desem… sanki çok zeki ama tecrübesiz biri gibi. Daha fazla bilgi için Anker’ın Bu Güç İstasyonu Şu An Cebinize Daha Yakın yazımıza bakabilirsiniz.
Küçük startup ile kurumsal ölçek arasında fark ne?
Küçük bir startup için self-attention kullanan modeller genelde hızlı prototipleme avantajı sağlıyor — ekip az kişiyle çok iş çıkarabiliyor, demo günü yaklaşınca bu baya can simidi oluyor. Ama veri azsa ya da etiketleme — itiraz edebilirsiniz tabi — zayıfsa mucize beklememek lazım. Gerçekten.
Enterprise seviyede durum farklılaşıyor. Performans kadar açıklanabilirlik. Maliyet de devreye giriyor; “model neden bu kararı verdi?” sorusu sık sık masaya geliyor ve self-attention skorlarını izlemek bazen işe yarıyor… bazen de yeni sorular doğuruyor. Cevap bulmak yerine sorular üretmek. Tanıdık geliyor mu? Bu konuyla ilgili Unity’de Çok Oyunculu Lobi: Socket.IO ile Sağlam Kurulum yazımıza da göz atmanızı tavsiye ederim.
- Küçük ekipler: hızlı deneme yapar, çabuk geri bildirim alır.
- Büyük kurumlar: güvenlik, uyumluluk ve izlenebilirlik ister.
- Tüm senaryolar: veri temizliği yapılmazsa attention tek başına kurtarmıyor.
Dikkat ağı gerçek hayatta nerede işe yarıyor?
Yani, Bence en net kullanım alanı çeviri sistemleri ve özetleme araçları. Bağlam olmadan hiçbir şey düzgün çalışmıyor bu işlerde — İngilizce’de zamirlerin referansı Türkçe’ye çevrilirken değişebiliyor, self-attention bu geçişleri yakalamaya yardımcı oluyor. Her zaman mükemmel mi? Değil. Ama yokken neydi, önü hatırlayınca “fena değil” diyorsunuz.
Şöyle ki, Editör masasında bu haberi hazırlarken aklıma geçen hafta test ettiğim bir soru-cevap botu geldi — 15 Mart 2026. Bot kısa sorularda idare ediyordu ama kullanıcı iki cümle üst üste yazınca referans kaymaya başlıyordu, yani konuya bağlılık düşüyordu. İşte böyle anlarda attention grafikleri gerçekten hayat kurtarıcı oluyor; hangi token’ın nereye baktığını görebiliyorsunuz. Somut. Elle tutulur.
Nerede parlıyor?
– Makine çevirisi
– Metin özetleme
– Soru-cevap sistemleri
– Kod analizi
– Uzun belge sınıflandırma
Tabi madalyonun öbür yüzü de var. Dikkat mekanizması güçlü olsa bile yorumlamak kolay değil — özellikle çok başlıklı attention katmanlarında hangi başlığın ne yaptığını açıklamak, teknik ekip dışındaki insanlara anlatmak… bayağı zorlaşıyor. Bazen “sihir gibi çalışıyor” demek zorunda kalıyorsunuz, ki bu hiç iyi bir yer değil.
Mühendis gözüyle birkaç pratik not
Eğer bugün elinizde transformer tabanlı bir proje varsa şunlara dikkat edin derim: veri temizliği yapmadan modele abanmayın, sequence length’i körlemesine uzatmayın ve benchmark sonucuna aldanıp rahatlamayın. Ben bunu iki farklı projede gördüm — kağıt üzerinde yüksek skor alan sistem canlıda kullanıcı diliyle karşılaşınca ufak ufak çatladı. Yavaş yavaş. Fark edilmeden.
- Daha temiz veri genelde daha iyi attention demek değildir, ama kötü veriyi düzeltmeden ilerlemek çoğu zaman boşa kürek çekmektir.
- Aşırı uzun girdi her zaman faydalı olmaz; maliyet artar, hız düşer, sinyal gürültüye karışabilir.
- Açıklama istiyorsanız attention haritaları yardımcı ölür ama tek başına hüküm vermeyin; başka analizlerle destekleyin.
Sıkça Sorulan Sorular
Self-attention nedir?
Tuhaf ama, Self-attention, bir cümledeki her kelimenin diğer tüm kelimelerle olan ilişkisini hesaplayan mekanizmadır. Bu şekilde model bağlamı daha iyi anlar ve zamirler gibi belirsiz öğeleri doğru eşleştirebilir.
Attention ile self-attention arasındaki fark nedir?
Attention genel olarak ilgiyi başka bir bilgi kaynağına yöneltme fikridir. Self-attention işe aynı dizinin içindeki öğelerin birbirine bakmasıdır. Transformer’larda asıl kilit nokta budur.
Neden positional encoding gerekiyor?
Çünkü self-attention tek başına sıralama bilgisini doğal olarak taşımaz. Positional encoding modele kelimenin cümledeki yerini hatırlatır ve dizilim bozulmadan işlem yapılmasını sağlar.
Tiny dataset ile self-attention işe yarar mı?
Evet,ama beklentiyi doğru kurmak gerekir. Veri azsa model bazen ezberci davranabilir veya tutarsız sonuç verebilir. Küçük projelerde önce sade modelleri denemek çoğu zaman daha akıllıcadır.
Daha geniş resim ne söylüyor?
Bir şey dikkatimi çekti: Bence transformer dünyasını özel yapan şey yalnızca hız değil;ilişkileri çıplak hâlde görüp onlardan anlam çıkarmasıdır. Klasik yöntemlerde ardışıklık ağır basarken burada ağın içine yayılan bağlantılar ön plana çıkıyor. Bu da özellikle dil gibi belirsizlik dolu alanlarda ciddi avantaj sağlıyor.
Lafı gevelemeden söyleyeyim:self-attention hâlâ öğrenmeye değer temel kavramlardan biri. Bugün AI ürünlerinin çoğunda onun izi var—çeviri motorlarında,doküman asistanlarında,arama katmanlarında,hatta kod önerilerinde bile. Tabii her yerde sihir yok;doğru veri,doğru mimarı. Doğru beklenti olmadan iş yürümüyor.
Eğer isterseniz sonraki yazıda multi-head attention kısmına geçip bunun neden tek başına yetmediğini daha somut örneklerle açabilirim. Orada işler biraz daha renkleniyor… hatta açıkçası asıl eğlence orada başlıyor.
Sıkça Sorulan Sorular İkinci Tür Gibi Düşünün 🙂
Sıkça Sorulan Sorular başarısız oldu mu? Hayır… devam edelim
Sıkça Sorulan Sorular diye bitirmeden önce küçük not
Sıkça Sorulan Sorular “tamam” dediğimiz yer burası
Sıkça Sorulan Sorular
Self-attention eğitim sırasında pahalı mı çalışır?
Evet, özellikle dizi uzadıkça hesaplama maliyeti yükselir. Bu yüzden production ortamında sequence length yönetimi önemli hâle gelir. Kısa metinde sorun olmayabilir. Uzun belgede fark hemen hissedilir.
Bütün attention head’leri gerçekten faydalı mı?
Zor soru! Bazıları bariz fayda sağlar,bazılarıysa pek görünmez ölür. Yine de hepsini topluca değerlendirmek gerekir çünkü farklı head’ler farklı ilişki türlerini yakalayabilir.
?
Kaynaklar ve İleri Okuma
Azure OpenAI Service dokümantasyonu
OpenAI kavramları (Azure AI Services)
Hugging Face Transformers (Transformer modelleri ve uygulamalar)
Azure AI Speech Service (Transformer tabanlı uygulama örnekleri için)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



