Bakın şimdi, yapay zekâ tarafında herkes aynı tuzağa düşüyor. Model saçmaladı mı, hemen “daha çok düşünsün” diyoruz (evet, doğru duydunuz). Daha fazla zincirleme akıl yürütme, daha fazla doğrulama, daha fazla ajan, daha fazla katman (bizzat test ettim). Kulağa mantıklı geliyor, evet. Ama işin aslı şu ki bazen sorun düşünmemesi değil; yanlış anda düşünmesi. Tamamen farklı bir şey bu.
Ben bu mevzuyu ilk kez 2024 sonbaharında, Kadıköy’de bir müşteri toplantısından çıkıp notlarımı karıştırırken fark ettim. Bir LLM tabanlı destek botu kuruluyordu. Ekip sürekli “bir tür daha reasoning ekleyelim” diyordu. Botun cevabı kötüydü ama mesele çoğu zaman bilgi eksikliği değildi — modelin ne zaman durması gerektiğini bilmemesiydi (ciddiyim). Yani gaz pedalına basmayı biliyordu, fren yoktu. Hiç fren yoktu. İşte tam burada T-800 benzetmesi bayağı işe yarıyor.
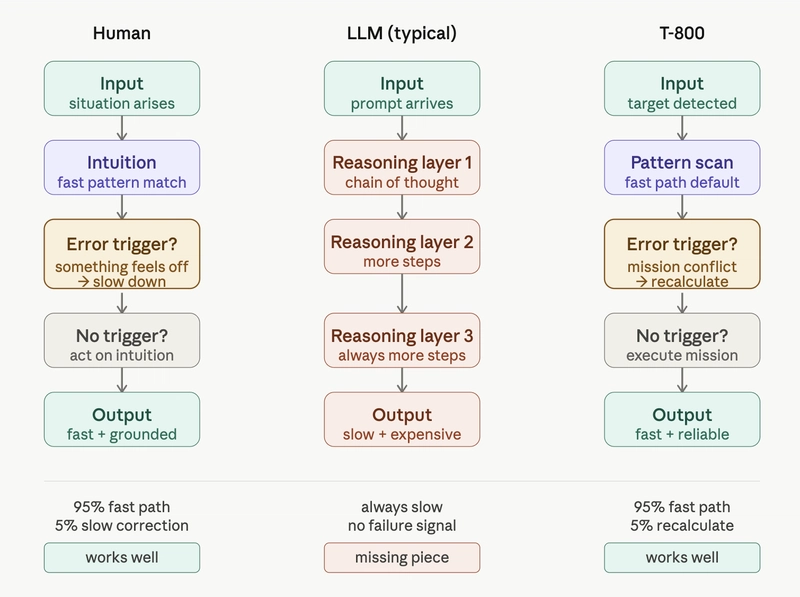
Terminatör’ü izleyenler bilir: T-800 ortalığı dağıtırken felsefe yapmaz. Durup varoluş krizi yaşamaz. Çevreyi tarar, örüntüyü yakalar, tehdit varsa tepki verir. Hızlıdır. Çünkü her hareketi baştan sona yeniden hesaplamaz; yalnızca düzen bozulunca, ancak o zaman geri adım atar. Büyük dil modellerinin de biraz böyle çalışması gerekiyor olabilir… hatta belki bayağı böyle.
Evet, doğru duydunuz.
Asıl Problem: “Daha Çok Akıl” Değil, “Ne Zaman Akıl?”
Yani, Bugün sektörde yaygın refleks şu: Model hata yaptıysa üstüne bir reasoning katmanı ekle. Halüsinasyon mu var? Zincir kur. Emin değil mi? Bir doğrulama ajanı köy. Cevap uzun ama zayıf mı? Bir katman daha ekle. Kağıt üstünde güzel duruyor; pratikte işe bazen üç zayıf fikri üst üste koyup tek sağlam cevap bekliyoruz (buna dikkat edin). Olmaz tabii.
Geçen martta Maslak’ta küçük bir SaaS ekibiyle konuşurken bunu net gördüm. Ekip müşteri e-postalarını sınıflandıran bir sistem kurmuştu. Ilk sürümde model gereksiz yere her şeyi “kritik” sanıyordu. Mühendis arkadaş hemen “daha derin prompt yazalım” dedi. Sonra test ettik. Aslında modelin sorunu derinlik değildi; yanlış örneklerle beslenmişti ve hata sinyalini hiç almıyordu. Hiç.
Çok konuştum, örnekle göstereyim.
Ne yalan söyleyeyim, Yani standart LLM’lerin temel problemi çoğu zaman yetersiz muhakeme değil (evet, doğru duydunuz). hata yaptığını anlayamaması. İnsanlarda da benzer durum var ama bizde en azından içten içe bir tedirginlik beliriyor: “Burada bir gariplik var.” İşte o küçük alarm çalınca yavaşlıyoruz. Model için böyle bir alarm yok — ya da çok zayıf kalıyor.
LLM’i güçlendiren şey sadece daha çok hesaplama değil; ne zaman duracağını bilen bir hata sinyali.
İnsan Beyni Bunu Zaten Yapıyor
Kahneman’ın anlattığı Sistem 1 ve Sistem 2 ayrımı burada hâlâ çok kullanışlı. Sistem 1 hızlıdır; sezgisel çalışır, örüntü görür, anında karar verir. Sistem 2 işe ağırdır — bilinçli düşünür, tartar biçer, enerji yer bitirir. Ve açıkçası insan da önü pek sevmez, mümkünse kaçar.
Peki neden?
Yani, Ama kritik nokta şu: İnsan beyni Sistem 2’ye rastgele geçmiyor. Önce Sistem 1’den bir sinyal geliyor — bir şey uyumsuz geliyor, ortamda pürüz hissediliyor, beklenti ile gerçek çakışıyor… sonra frene basılıyor. Önce sinyal, sonra yavaşlama. Bu sıra önemli.
Bunu kendi editör masamda da defalarca yaşadım. Mesela geçen yıl Beşiktaş’taki ofiste AI haberleri arasında gezerken bir modelin verdiği cevap bana ilk bakışta düzgün gelmişti. Içinde tarihler kaymıştı; küçük bir detay gibi görünüyordu fakat hikâyenin tamamını bozuyordu. O an aklımdan şunu geçirdim: Eğer bu sistemde “bir dakika burası ters” diyen mekanizma yoksa, kullanıcıya güven vermesi zor. Çok zor. neden ile ilgili önceki yazımız yazımızda bu konuya da değinmiştik.
T-800 benzetmesi neden tutuyor?
T-800’ün gücü her şeyi çözmesinde değil; doğru anda doğru moda geçmesinde yatıyor. Aslında güçlü tarafı bu olduğu için biraz unutuluyor. Normalde hızlı ilerliyor, ama yeni bir durum çıkınca yeniden değerlendiriyor. Dür, bak, karar ver.
Bu yapı bize şunu söylüyor: İyi sistem her şeyi sürekli hesaplayan sistem değildir. İyi sistem gerekli olduğunda yavaşlayabilen sistemdir. Basit ama gözden kaçıyor. Daha fazla bilgi için The Kaiser fragmanı: Schumacher efsanesinin perde arkası yazımıza bakabilirsiniz.
LLM’lerde Eksik Parça Nerede?
Bence eksik parça oldukça net: eşik mantığı yok, ya da nazikçe söyleyeyim, zayıf var. Model çoğu durumda kendi çıktısının ne kadar güvenilir olduğunu ayırt edemiyor. Ya da bunu yeterince sert biçimde sinyale çeviremiyor. İkisi de sorun aslında.
- Hızlı yol: Kolay ve tanıdık işleri çabuk çözer.
- Tetikleyici: Şüphe varsa modeli yavaşlatır veya ekstra kontrol ister.
| Sistem | Güçlü Yani | Zayıf Yani |
|---|---|---|
| T-800 / hızlı mimarı | Düşük gecikme, net aksiyon | Sapma algısı iyi tasarlanmazsa körleşebilir |
| Klasik LLM + çoklu reasoning | Daha ayrıntılı açıklama üretir | Maliyet artar, hata zinciri uzayabilir |
| Eşik tabanlı hibrit yapı | Denge sağlar, gerektiğinde derinleşir | Tasarımı zor ve ölçümü dikkat ister |
Açık konuşayım: bugünkü birçok ürün gereksiz yere “her soru doktora teziymiş gibi” davranıyor. Basit soruya uzun muhakeme dökmek bazen kalite hissi veriyor, tamam, anlıyorum o cazibeyi — ama hız ölduruyor. Üstelik güveni de otomatik artırmıyor. Aksine bazen şüphe uyandırıyor. Bu konuyla ilgili Apple’ın Yeni Gözlük Planı: Meta’ya Sessiz Bir Meydan Okuma yazımıza da göz atmanızı tavsiye ederim. Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik.
Küçük startup ile enterprise aynı dertte mi?
Kısmen evet ama etkisi farklı oluyor. Startup tarafında maliyet hemen can yakıyor çünkü her gereksiz token doğrudan faturaya yazılıyor. Acı acı.
Kurumsalda işe sorun başka yerde patlıyor: gecikme ve operasyonel karmaşa büyüyor. Bir banka ya da telekom projesinde iki saniye fazladan beklemek bile kabul edilmeyebiliyor. “İki saniye ne ki” demeyin.
Neyi ölçmeden iyileştirmeye kalkıyoruz?
Yüzde yüz emin değilim ama sahada en sık gördüğüm hata şu oluyor: takımlar önce çözümü büyütüyor, sonra ölçüm aracı arıyor. Oysa önce yanlış pozitif oranını, belirsizlik skorunu, cevap süresini ve insan onayı ihtiyacını ayrı ayrı görmek lazım. Yoksa elimizde sadece pahalı bir tahmin makinesi kalıyor. Maalesef.
# Basit tetikleyici mantığı
if confidence < threshold or contradiction_detected:
run_deeper_reasoning()
else:
return fast_answer()Tetikleyici Mantığı Pratikte Nasıl Kurulur?
Garip gelecek ama, Lafı gevelemeden söyleyeyim: Burada sihir yok, mühendislik var. İlk adım güven skoru üretmek — modelin kendi cevabına ne kadar güvendiğini sayısallaştırmak gerekiyor. Öyle havada bırakmayacağız işi. Somut sayı lazım.
- Düşük güven puanı görünce ikinci aşamaya geç;
- Cevap içinde çelişki varsa kontrol et; (bence en önemlisi)
- Kullanıcı talebi kritikse insan onayı işte;
- Konu yeni veya veri eksikse hızlı yanittan vazgeç;
E tabi bazı takımlar burada aşırıya kaçıyor ve her şeyi trigger’a bağlıyorlar. Bu sefer de sistem hantallaşıyor. Benim gördüğüm dengeli yaklaşım şu: basit sorulara hızlı cevap, riskli sorulara kontrollü yavaşlama (şaşırtıcı ama gerçek). Kedi gibi davranmak lazım aslında — boşuna koşmazsın ama ses duyunca kulak dikersin!
Error trigger neye benzeyebilir?
Belirsizlik sinyali = düşük confidence + konu dışı sıçrama + kullanıcı düzeltmesi
Aksiyon = hızlı cevap / yeniden dene / insana yönlendir / derin analiz
Bu formül elbette tek başına mucize yaratmaz. Ama ürün takimina net çerçeve verir. Bilhassa de sağlık, finans ya da hukuk gibi alanlarda tetikleyici mantık neredeyse zorunlu hâle geliyor çünkü yanlış özgüven ucuz kaçmıyor. Hiç ucuz kaçmıyor. Daha fazla bilgi için PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımıza bakabilirsiniz.
Neden Sadece CoT Yetmiyor?
Hani, Zincirleme düşünme teknikleri kötü demiyorum. Yanlış anlaşılmasın. Bayağı faydalılar, hatta bazı görevlerde şart. Ama tek başlarına ilaç değiller. Çünkü problemin kökü çoğu zaman muhakemenin uzunluğu değil; neye dayanarak başladığıdır.
Bir model yanlış varsayımla başladıysa, üstüne beş sayfa gerekçe yazması o yanlışı parlatır sadece. Bu kısmı özellikle sevmedim açıkçası — kağıt üzerinde zekice görünen şey, gerçekte hayal kırıklığı yaratabiliyor. Baya can sıkıcı bir durum bu.
Kendi deneyimimden konuşuyorum, Bir arkadaşım Nişan 2025’te Londra’da çalışan ekiplerinde bunu test etti: çok adımlı akıl yürütme eklediler, sonuçların açıklaması güzelleşti ama doğruluk artışı sınırlı kaldı. Hatta bazı vakalarda performans düştü çünkü hatalar ara adımlarda yayıldı. Tam da beklediğim gibi.
Bak şimdi, Neyse uzatmayalım: iyi mimarı önce erken uyarı ister, sonra derine iner. Bu sıra değişirse sonuç değişiyor.
Kendi Ürününde Bunu Nasıl Kullanırsın?
- Basit işleri hızlı katmanda çöz.
- Bilinmeyen ya da riskli girdileri işaretle.
- Tetikleyici oluşunca ekstra doğrulama çalıştır.
- Sistem çıktılarını düzenli olarak insan örnekleriyle karşılaştır. (bence en önemlisi)
Kendi projenizde bunu deniyorsanız küçük başlayın derim. Önce tek metrik seçin: örneğin confidence eşikleri veya çelişki sayısı. Sonra kullanıcıya hangi noktada yavaşladığınızı gösterin ki ekip içi tartışma soyut kalmasın. Somutluk şart.
Size bir şey söyleyeyim, Ben bu yaklaşımı geçtiğimiz kasımda İzmir’den gelen bir fintech demosunda tekrar gördüm; ekip önce büyük multi-agent plan kurmuştu, sonra iki basit trigger ile problemi yarıya indirdiğini fark etti — inanılır gibi değildi açıkçası. Bazen az araçla daha temiz sonuç alıyorsun; fazlası sadece gürültü. Gerçekten sadece gürültü.
Ha bu arada içeriğin AI verimlilik tarafıyla ilgileniyorsanız Yapay Zekâya Akıl Kiralamadan Bakmanın İki Sağlam Yolu yazısına da göz atabilirsiniz.
Şimdi gelelim en önemli ayrıntıya: enterprise tarafta bunu ürün seviyesinde standartlaştırmak gerekirken, küçük ekiplerde elle yönetilen kurallar bile iş görebilir. İkisi aynı reçete değil. E peki, sonuç ne oldu? Aynısını herkese satmaya çalışmak biraz pazarlama numarası ölür.
Nerede İşe Yarar, Nerede Patlar?
| Kullanım Alanı | Neler Kazandırır? | Nerede Zorlanır? |
|---|---|---|
| Müşteri desteği botu | Daha az gereksiz muhakeme sayesinde hız kazanır | Nadir durumları kaçırabilir |
| Kod yardımcıları | Basit görevler hızlanır, performans artar | Çok bağlam isteyen işlerde yetmez |
Durun bir saniye — burada tablo biraz kaba kaldı, farkındayım. Ama fikir önemli olan, format değil. Bazı ürünlerde hız önceliklidir; bazılarında yanlış cevabın bedeli yüksek olduğu için tetikte olursunuz. Mesela e-ticarette öneri motoru hatası can sıkıcıdır. Ama medikal sınıflandırmada cidden problem çıkarır. Ciddi problem.
Bir de şu var: modeli ne kadar zeki yaparsanız yapın, yanlış hedef fonksiyonu kullanıyorsanız sonuç yine yamuk çıkar. Bu kısmı atlamayın.
Sıkça Sorulan Sorular
Error trigger nedir?
Error trigger, modelin kendinden şüphe duymasını sağlayan mekanizma gibi düşünebilirsiniz…
Cevap belirsizse veya veriyle çelişiyorsa sistem ekstra kontrole geçer.
Llm’lere neden hep more reasoning ekleniyor?”>
Ama asıl sorun çoğu zaman yanlış anda düşünmek veya hiç durmadan düşünmek oluyor.
Küçük ekipler için bu yaklaşım uygun mu?
Evet, hatta bazen daha uygun oluyor çünkü maliyet kontrol altına giriyor.
Basit kurallar ve birkaç eşik bile ciddi fark yaratabiliyor.
“Kaynaklar Ve İleri Okuma”

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.