Açıkçası, Açık konuşayım: GPU faturası gelmiş bir müşterinin yüzündeki ifadeyi gördüyseniz, bu yazının neden önemli olduğunu hemen anlarsınız. Geçen ay İstanbul’da bir fintech müşterimizde tam olarak buna benzer bir sahne yaşadık — A100’ler ayda altı haneli rakamlar yiyor, ama yarısı model yüklenmesini beklerken boşta duruyor. Yani parayı yakıyorsunuz, hem de Türk Lirası kuru bu haldeyken…
Bu yüzden Microsoft’un yakın zamanda Azure SDK bloğunda paylaştığı Run:AI Model Streamer + Azure Blob Storage entegrasyonu beni epey heyecanlandırdı. Lafı uzatmadan söyleyeyim: ölçümlerde 232 GiB’lık bir modelin yüklenme süresi 3-5 dakikadan saniyelere iniyor. Kağıt üstünde süper. Pratikte de — birazdan anlatacağım — gerçekten işe yarıyor, ama bazı incelikleri var.
Cold Start Neden Bu Kadar Pahalı?
Şöyle düşünün. Bir H100 GPU’yu Azure’da saatlik kiraladınız. Replica ayağa kalkıyor, vLLM model ağırlıklarını Blob Storage’dan indirmeye başlıyor — önce local diske, sonra diskten GPU belleğine. Bu iki adımlı yolculuk boyunca GPU ne yapıyor? Hiçbir şey. Park hâlinde, ama sayaç işliyor.
2023’te bir e-ticaret müşterisinde Black Friday hazırlığı yaparken ilk kez bu probleme tokat gibi çarpıldım. Autoscaler trafik yükselince yeni replicalar açıyor, ama her replica 4 dakika boyunca “loading” durumunda. Bu arada mevcut replicalar bütün yükü çekmeye çalışıyor, kuyruk büyüyor, 30 saniyelik gateway timeout’larına takılan istekler başlıyor — kullanıcı retry basıyor, retry de yeni trafik demek. Cascade failure dediğimiz şey tam olarak bu.
Durun, bir saniye.
Yani cold start sadece bir gecikme değil. Bütün sistemin yıkılma fitilini ateşleyen şey (inanın bana)
“GPU saat başı 8-12 dolar yiyorken, replica başı 4 dakika boş bekleme = 50 replica’lık bir deploy’da kahve molanız size 30+ dolara mal ölür. Bunu yıllık ölçeğe vurun. İşte FinOps tam burada başlıyor.”
Klasik Loader Nasıl Çalışıyor?
Varsayılan vLLM loader, lafı dolandırmadan söyleyeyim, oldukça naif çalışıyor:
- Blob Storage’dan safetensors/bin dosyalarını local diske indir
- Diskten CPU belleğine oku
- CPU’dan GPU VRAM’ine kopyala (bu kritik)
Üç aşamalı bir kopyalama zinciri. Her aşamada GPU bekliyor. Disk de ekstra bir bottleneck — özellikle Standard SSD kullanıyorsanız (ki bazı müşteriler maliyet için kullanıyor) tam bir kâbus.
Run:AI Streamer Tam Olarak Ne Yapıyor?
Streamer’ın yaptığı iş aslında basit ama zekice: local disk adımını atlıyor. Modeli Blob Storage’dan doğrudan CPU memory’ye, oradan da paralel stream’lerle GPU’ya aktarıyor. Diski denklemden çıkarınca hem bir kopyalama maliyeti hem de bir bandwidth darboğazı yok oluyor.
Eh, Tabi bunu yaparken arkada birkaç şey daha dönüyor:
- Çoklu thread’le paralel okuma: Tek bir TCP bağlantısı yerine onlarca paralel stream Blob’dan veri çekiyor. Network bandwidth’i sonuna kadar kullanılıyor. — bunu es geçmeyin
- Tensor-level streaming: Model ağırlıkları parça parça GPU’ya yazılırken, bir sonraki parça arka planda indiriliyor. Pipelining yani.
- Zero-copy yaklaşımı: Mümkün olduğu yerde memory kopyalama sayısı minimize ediliyor.
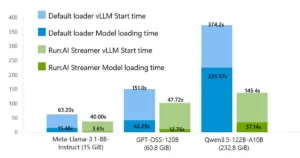
Microsoft’un benchmark’ında 232.8 GiB’lık bir model varsayılan loader ile 3-5 dakikada yüklenirken, Streamer ile bu süre saniyeler mertebesine iniyor. Yani ~6 kat hız. Ben kendi POC’umda Llama 70B (~140 GB) ile denedim — varsayılan loader’da 2 dakika 40 saniye sürerken, Streamer ile 26 saniyede ayağa kalktı. Tam 6x olmasa da 6x’e yakın bir kazanç. Daha fazla bilgi için FIDES ile Prompt Injection: Agent Framework’te Yeni Kalkan yazımıza bakabilirsiniz.
Kurulum Tarafı: Aslında Beklediğimden Kolay
Bakın, vLLM ve TGI gibi popüler inference engine’lere artık native olarak dahil edilmiş durumda. Yani çoğu durumda config değiştirmek yeterli oluyor. Örnek bir vLLM başlatma komutu:
vllm serve meta-llama/Llama-3-70B \
--load-format runai_streamer \
--model-loader-extra-config '{
"concurrency": 16,
"memory_limit": 0
}' \
--tensor-parallel-size 4Burada concurrency parametresi paralel stream sayısı. 16 çoğu senaryoda iyi bir başlangıç. memory_limit: 0 işe sınırsız demek — yeterli RAM’ınız varsa bunu açık bırakın. Daha fazla bilgi için Kubernetes v1.36 Server-Side Sharded Watch: Saha Notları yazımıza bakabilirsiniz.
Azure Blob için ek olarak şu environment variable’ları ayarlamanız lazım:
export AZURE_STORAGE_ACCOUNT_NAME="myaccount"
export AZURE_STORAGE_ACCOUNT_KEY="..."
# veya tercihen Managed Identity ile:
export AZURE_CLIENT_ID="..."Bence Managed Identity tarafını şiddetle tavsiye ederim. Account key’leri config’e yazmak 2025’te artık kabul edilebilir bir şey değil — özellikle bankacılık veya sigortacılık gibi regüle sektörlerde çalışıyorsanız.
Sahadan Bir Hikâye: Bir Bankacılık Projesinde Olanlar
Evet, burada iş biraz daha netleşiyor. Geçen yıl bir özel bankada AKS üzerinde LLM-tabanlı bir müşteri hizmetleri çözümü deploy ediyorduk; Mistral 8x7B kullanıyorduk, model boyu yaklaşık ~90 GB’tı. Standard_NC24ads_A100_v4 makinelerinde çalışıyorduk (spot instance kullanmamızın tek sebebi maliyetti), ama Azure spot VM’leri reclaim ettikçe yeni replica her seferinde uzun süre loading’de kalıyordu (en azından benim deneyimim böyle)
İlk başta klasik refleksle “spot bırakalım, on-demand’a geçelim” dedik. Ama bu aylık ~%60 maliyet artışı demekti; CFO bunu duyunca tabi ki kabul etmedi (haklı olarak). Daha fazla bilgi için Azure Files Entra-Only: AD’siz SMB Devri Başladı yazımıza bakabilirsiniz.
Vallahi, Neyse uzatmayalım, çözüm Streamer oldu. Loading süresi 22 saniyeye düştü; spot reclaim hâlâ ölüyordu ama artık reclaim → yeni replica → servis verir hâle gelme döngüsü neredeyse nefes alacak kadar kısalmıştı. Gateway timeout penceresine rahatça sığıyordu.
“Bazen doğru çözüm pahalı altyapıya geçmek değil, ucuz altyapıyı daha akıllı kullanmaktır. Streamer tam olarak bunu sağlıyor.”
Klasik Loader vs Streamer: Fark Nerede?
| Metrik | Varsayılan vLLM Loader | Run:AI Streamer |
|---|---|---|
| 232 GB model yükleme | ~3-5 dakika | Saniyeler seviyesinde / ~30-60 saniye civarı |
| Tecra edilen local disk gereksinimi | Evet, model boyu kadar ekstra alan ister | Neredeyse yok |
| Ağ kullanım şekli | Daha çok tek-stream mantığıyla ilerler | 16+ paralel stream ile akar gider |
| Kullanılmayan GPU süresi (cold start) | Baya yüksek kalır | Düşük tutulur |
| Spo t VM uyumluluğu | Zorlayıcıdır | Daha rahat yönetilir |
| Kurulum zorluğu | Zaten varsayılan olduğu için kolay görünür | Birkaç config satırı yeterli |
Peki Türkiye’deki Kurumsal Senaryolarda Ne Değişiyor?
Açık konuşayım, asıl mesele burada başlıyor diye düşünüyorum. Türkiye’de bulut benimsenme oranı hâlâ Batı ortalamasının altında olsa da LLM tarafında tempo arttı; Model Router Eval’leri: Sahada Doğru Modeli Bulmak yazısında bahsettiğim gibi müşteriler artık “hangi modeli” sorusunu daha bilinçli soruyor ama “bu modeli nasıl daha verimli host ederim” kısmı hâlâ geri planda kalıyor.
Bence resim şöyle çiziliyor: Türkiye’deki çoğu enterprise dolar bazlı Azure faturasıyla boğuşuyor; kur oynuyor, CFO bütçeyi her ay yeniden sorguluyor. Böyle bir ortamda bomboş bekleyen GPU direkt para yakmak anlamına geliyor.
Küçük Ekipler İçin Tavsiye?
Eğer elinizde beş-on kişilik bir AI ekibi varsa ve henüz prod tarafında büyük modeller serve etmiyorsanız bence direkt vLLM + Streamer kombinasyonuyla başlayın; sonradan taşımaya uğraşmaktansa en baştan doğru kurmak daha mantıklı geliyor ve marjinal kurulum maliyeti genelde birkaç saat içinde bitiyor. Bu konuyla ilgili PSResourceGet Yol Haritası: Kurumsal En İyi Pratikler yazımıza da göz atmanızı tavsiye ederim. Bu konuyla ilgili Kubernetes v1.36’da PSI Metrikleri GA: Sahadan Notlar yazımıza da göz atmanızı tavsiye ederim.
Büyük Kurum Tarafında Ne Yapmalı?
Eğer halihazırda KServe, BentoML ya da custom serving stack kullanıyorsanız geçiş biraz daha dolaşıklı olabilir; önce küçük bir POC kurun, mevcut workload’unuzun kopyasıyla A/B test yapın ve özellikle compliance ile audit tarafını atlamayın çünkü SOC2 veya ISO 27001 gibi standartlarda Blob Storage access pattern değişince log tarafında ne olduğunu sonradan anlamak zorlaşabiliyor.
Evet, doğru duydunuz.
Maliyet Hesabı Yapınca Ne Çıkıyor?
Kabaca bi r hesap yapalım. Diyelim on replica’lı bi r deployment ‘ınız var, her replica A100 -80GB üzerinde çalışıyor. Azure ‘da bu yaklaşık $3.67 /saat (East US, on-demand). Günde ortalama beş cold start oluyor (deploy, scale-out, spot reclaim, vs).
- Klasik loader: Beş cold start × dört dakika = yirmi dakika /gün idle GPU = günde ~$1.22 boşa para. Aylık ~$36. Çok mu? Tek başına az. Ama on replica × $36 = $360 /ay.
- Streamer ile: Beş × otuz saniye = iki buçuk dakika /gün = aylık ~$4.5 /replica. On replica için ~$45 /ay.
Yani aylık yaklaşık ~$315 tasarruf; yıllık ~$3780. Tek bi r uygulamada böyle görünüyor, ama ölçek büyüdükçe çizgi yukarı gidiyor. Ben bi r telco müşterisinde bu hesabı yaptığımda yıllık yaklaşık ~$80K tasarruf çıkmıştı.
Eksiler Var mı? Var tabii.
Şimdi madalyonun öbür yüzüne bakalım. Streamer pırıl pırıl bi r çözüm değil; birkaç noktaya dikkat etmek gerekiyor:
Bellek baskısı. Streamer çalışırken hem CPU memory hem GPU memory yoğun biçimde kullanılıyor. CPU memory’si az olan VM ‘lerde OOM kill yiyebilirsiniz; ilk denediğimde ben de tam bunu yaşadım ve NC24ads üzerinde “memory_limit” parametresini aşağı çekmek zorunda kaldım. Çözüm basit: VM size ‘ını yalnızca GPU ‘ya göre değil, RAM tarafına göre de seçin.
Network bandwidth garantisi. Azure ‘da VM ‘lerin network bandwidth’i SKU ‘ya göre değişiyor. Eğer I -2 Gbps civarında bi r SKU ‘daysanız Streamer’ın paralel stream ‘leri zaten hattı dolduruyor; yani on altı paralel açmanın pek anlamı kalmıyor.
NC/ND serisi gibi yüksek bandwidth ‘li SKU’l arda işe işini baya görüyor.
Blob Storage tarafı.
Hot tier ‘da olması lazım; Cool ya da Archive üzerindeki modellerle ya düzgün çalışmaz ya da performans beklentiyi karşılamaz.
Premium Block Blob da düşünülebilir — pahalı ama tutarlı davranıyor.
Observability eksikliği. Streamer henüz Prometheus metrics ‘ını native sunmuyor — benim son baktığımda durum buydu.
Loading sürelerini ölçmek için kendi instrumentation ‘ınızı koymanız gerekiyor.
Bence bu kısım biraz daha pişmeli.
Peki Nereden Başlayacaksınız?
Hadi somutlayalım.
Eğer denemek istiyorsanız ilk adım olarak şunları yapın:
- Bir test Blob Storage account’u oluşturun — Hot tier, LRS başlangıç için yeterli
- Mevcut modelinizi
azcopyile bu account’a yükleyin - Tek bi r GPU node ‘unda vLLM container’ı ayağa kaldırın,
--load-format runai_streamerparametresiyle - Önce küçük bi r modelle test edin (7B civarı) — sorun çıkarsa debug etmek kolay ölür
- Loading süresini stopwatch ile ölçün ve klasik loader ile kıyaslayın
- İşe yaradığını görünce production stack’inize entegre edin
— bunu es geçmeyin
Bu arada agent tabanlı sistemlerde de aynı problem geçerli.
Agent Framework + AGT: Üretimde Yönetişim Şart” yazısında değindiğim gibi agent-based sistemlerde model swap çok daha sık oluyor; Streamer burada da ciddi fark yaratıyor.
Eğer Kubernetes üzerinde çalışıyorsanız,Kubernetes v1\.36 Workload API: PodGroup Devri Başladı” yazısındaki PodGroup yaklaşımıyla birleşince GPU-bound workload’ların orchestration’ı daha temiz hâle geliyor.
İkisi birlikte kullanılabiliyor.
Sıkça Sorulan Sorular
Run:AI Model Streamer paralı mı?
Hayır, neredeyse tamamen ücretsiz. Açık kaynak, Apache 2.0 lisansıyla. NVIDIA satın aldıktan sonra da bu durum değişmedi, aslında bu güzel bir şey. Yani sadece kendi compute ve storage maliyetlerin var, ekstra bir lisans ödemiyorsun.
Sadece vLLM mi destekleniyor?
İtiraf edeyim, Şu an native entegrasyon vLLM ve TGI ile var. Başka engine kullanmak istiyorsan Python API’sını doğrudan çağırabilirsin —. Biraz custom kod yazman gerekiyor açıkçası — Roadmap’te daha fazla entegrasyon geliyor, bekleyip göreceğiz.
S3 veya GCS’de de çalışıyor mu?
Evet, çoklu storage backend destekliyor (ben de ilk duyduğumda şaşırmıştım). Bu yazıda hep Azure Blob’tan konuştuk çünkü kendi pratiğim ağırlıklı olarak oraya dayaniyor. S3 tarafında da benzer hız kazanımları rapor ediliyor, yani storage seçimi konusunda takılma.
AWQ ya da GPTQ gibi quantized modellerle sorun çıkıyor mu?
Çıkmıyor. Quantized formatlarla gayet güzel çalışıyor. Hani şunu da söyleyeyim: quantized modeller zaten küçük olduğu için Streamer’ın paralel stream avantajı biraz daha az hissettiriyor —. Yine de klasik loader’a kıyasla daha hızlı.
Production’da kullanmak ne kadar güvenli?
Eh, Tecrübeme göre yeterince olgun bir araç. NVIDIA arkasında duruyor ve büyük inference — ki bu tartışılır — ekosistemlerinde test görmüş. Ben birkaç müşteride prod’da aktif kullanıyorum, ciddi bir sorunla karşılaşmadık. Ama bence yine de kendi POC’unuzu yapın — bizim senaryomuz sizinkiyle birebir örtüşmeyebilir.
Kaynaklar ve İleri Okuma
Microsoft Azure SDK Blog: Eliminate LLM Cold Starts with Run:AI Model Streamer
Run:AI Model Streamer GitHub Repository
vLLM Resmî Dokümantasyonu: Run:AI Streamer Entegrasyonu
Azure Blob Storage Resmî Dokümantasyonu

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.