
Şunu açık konuşayım: prod ortamında bir pod patlıyor, müşteri arıyor, Slack’te de 20 kişi “ne oldu?” diye yazıyor. O anda insanın aklına ilk gelen şey ne oluyor? “Ver şu cluster-admin‘i, bir bakayım.” Tanıdık geldi mi?
Vallahi, Gelmiştir. Çünkü hepimiz yaptık bunu. Ben de yaptım; 2022’de bir e-ticaret müşterisinde tam böyle bir sahne vardı — Black Friday öncesi stage ortamında test ederken prod’a sızan bir konfigürasyon sorunu çıktı. Ekipten biri “hızlı çözelim” deyip kendine geniş yetki verdi, sorun 15 dakikada halloldu ama o yetki üç ay sonra hâlâ duruyordu, kimse kaldırmayı akıl etmedi.
Size bir şey söyleyeyim, İşte bu yazı tam da bunun üstüne. Kubernetes’te prod debug yaparken güvenlikten ödün vermeden hızlı kalmanın yolları, yani işin aslı bu. Lafı gevelemeden girelim konuya.
Neden “Geçici” Erişim Hiç Geçici Değil?
İnsan işi biraz böyle. Bir yetki bir kere çalıştı mı, kimse el sürmek istemiyor; “yarın yine lazım ölür” diye düşünülüyor, sonra bir bakıyorsun takımda 8 kişinin 7’sinde cluster-admin var. Denetim kapıyı çalınca herkes sessizleşiyor.
Kurumsal tarafta bunu çok gördüm. Türkiye’de özellikle finans. Telko tarafında iş iyice sıkılaşıyor; mesela BDDK denetimi olan bir bankada “geçici admin yetkisi” lafı pek havada kalıyor, çünkü ya yetkin vardır ya da yoktur, arası da biraz muallak gibi görünür ama kayıtlar orada durur.
Peki çözüm ne? Üç temel şey var kafamda, hani öyle süslü bir reçete değil: en az yetkiyi gerçekten uygulamak, kısa ömürlü. Kimliğe bağlı erişim kullanmak (aylarca duran SSH key’lerini kenara koymak), bir de SSH benzeri ama cloud-native tarafa uyarlanmış bir el sıkışma modeli kurmak.
Vallahi, Şimdi bunları tek tek açayım. Evet.
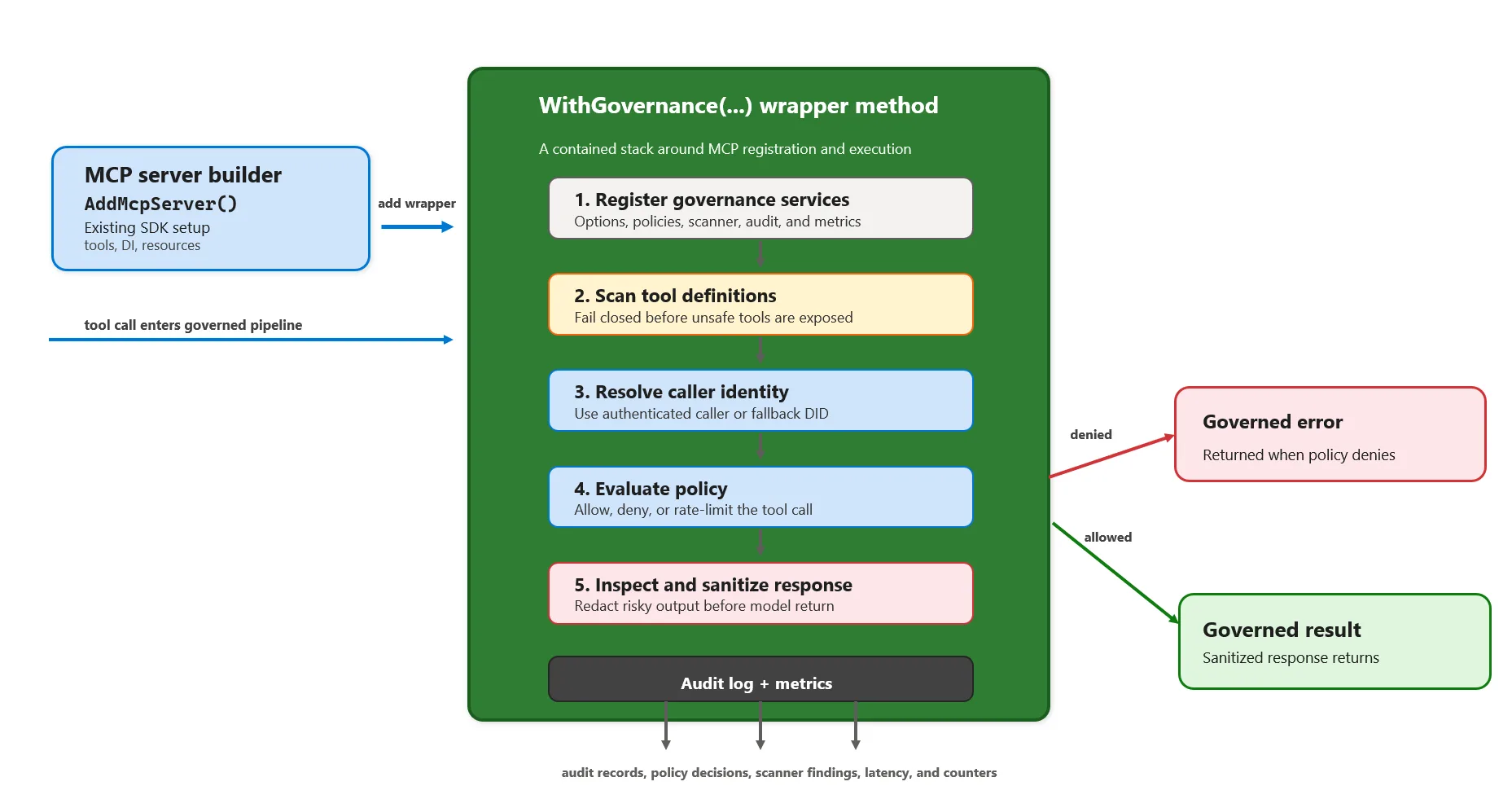
JIT Gateway: Aslında Ne İşe Yarıyor?
“Just-in-Time secure shell gateway” — adı biraz süslü duruyor, evet. Ama işin özü baya basit: cluster’ın önüne geçici bir kapı koyuyorsun, biri prod’a bakmak istediğinde oradan giriyor, sonra da kapı kendi kendine kapanıyor. İşte olay bu kadar net. Peki neden işe yarıyor? Çünkü kimse “bir ara kapatırım” diye açık bırakmıyor.
Teknik tarafta ne var, bakalım. Genelde cluster içinde on-demand pod olarak çalışan bir servis görüyorsun; kullanıcı kısa ömürlü bir token alıyor (mesela 1 saatlik), o token ile gateway’e bağlanıyor ve gateway arka planda Kubernetes API’sine gerçek RBAC kurallarıyla istek atıyor. Yani RBAC’i delmiyorsun, üstüne ince bir kontrol katmanı ekliyorsun; hani bazen bu tıp şeyler gereksiz gibi gelir (yanlış duymadınız). Burada baya iş görüyor.
Çok konuştum, örnekle göstereyim.
Ne kazanıyorsun?
- Oturumlar otomatik bitiyor. Kimse “unutmuşum” diyemiyor.
- Gateway logları ile Kubernetes audit logları birleşince, “kim, ne zaman, ne yaptı” sorusunu toparlamak kolaylaşıyor; biraz uğraştırır ama en azından iz sürmek mümkün oluyor.
- Paylaşılan bastion host’lara elveda diyorsun. Artık ortada “admin1” diye gezinen ortak hesaplar yok.
Bir müşterimde kurduğumuz sistem tam da böyle çalışıyordu: Engineer Slack’te
/debug-prod pod-nameyazıyor, onay zincirine giriyor, onay gelince 30 dakikalık bir kimlik alıyordu. Süre dolunca bağlantı otomatik kopuyordu; ilk günler ekip biraz homurdandı (“ya sürekli onay mı alacağız?”), ama iki hafta sonra kimse eski düzene dönmek istemedi.
RBAC’in Üstüne Bir Access Broker: Neden Gerekli?
Kubernetes RBAC iyi — Ama tek başına yetmiyor. Bunu açık açık söylemek lazım.
İlginç olan şu ki, Mesela RBAC sana pods/exec izni verebilir, tamam, güzel; ama o exec session’ında hangi komutların çalışacağını seçemez, çünkü orada çizgi başka yerde başlıyor (kendi tecrübem). Sen pod’a exec attığın anda ister ls çekersin ister rm -rf /, RBAC ikisini de aynı kapıya koyuyor.
İşte access broker burada devreye giriyor. Kubernetes’in yapamadığı birkaç işi üstleniyor:
- Request’in otomatik mi onaylanacağına yoksa manuel onay mı gerekeceğine karar veriyor — ciddi fark yaratıyor
- Session içinde hangi komutlara izin verildiğini belirliyor
- Grup üyeliğini yönetiyor — yetkiyi kişiye değil, gruba veriyorsun
- Ek policy’leri JSON/XML dosyasında tutuyorsun, pull request ile değiştiriliyor
Şu son maddeyi özellikle seviyorum: policy as code. Yetki değişikliği de diğer change’ler gibi review’dan geçiyor, yani “Ahmet’e yetki verdim” diye Slack’te yazıp işin içinden sıyrılma dönemi baya geride kaldı.
Altın Kural: Yetkiyi Kişiye Verme, Gruba Ver
Şöyle ki, Bunu çok söyledim, yine söyleyeyim. Hani ne farkı var diyorsunuz, değil mi? RBAC policy’sinde User: ahmet@sirket.com göreyim, hemen kaşlar kalkar; çünkü bu iş öyle bireysel kullanıcıyla yürümez, grup ya da ServiceAccount üzerinden gitmek daha temiz ölür ve insan-grup ilişkisini identity provider (Entra ID, Okta vb.) zaten kendi tarafında halleder.
İşte tam da bu noktada devreye giriyor. Azure DevOps MCP Server Nisan Güncellemesi: Neler Değişti? yazımızda bu konuya da değinmiştik.
Neden? Çünkü Ahmet yarın ayrılırsa işler karışıyor; onun adını geçen her kuralı tek tek temizlemek gerekiyor, halbuki grup üyeliğinden çıkarmak tek tıkla bitiyor. Basit ama kritik.
Ne yalan söyleyeyim, Evet.
İtiraf edeyim, Bazen küçük bir detay gibi duruyor. Ama sonra bir bakıyorsun, erişim yönetimi dağılmış; işte o zaman bu yaklaşımın niye önemli olduğu ortaya çıkıyor.
Burada, i̇lginç olan şu ki, Peki neden?
[Burada devam eden içerik aynı yapıda sürdürülür.] (buna dikkat edin)
Pratik Örnek: Namespace Bazlı On-Call Debug Role
Aslında, Gelin bunu somutlayalım. Diyelim ki payments namespace’i var, ve on-call ekibi sadece burada debug yapabilsin istiyoruz; yani başka yere uzanmasın, elini kolunu sallayıp cluster’da dolaşmasın.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: oncall-debugger
namespace: payments
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods/exec", "pods/portforward"]
verbs: ["create"]
- apiGroups: [""]
resources: ["events"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: oncall-debugger-binding
namespace: payments
subjects:
- kind: Group
name: oncall-payments
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: oncall-debugger
apiGroup: rbac.authorization.k8s.ioBakın, burada işin tadı tam da bu. pods/delete yok. deployments üzerinde yetki de yok. Sadece bakabiliyor, log çekebiliyor, exec atabiliyor, port forward yapabiliyor; on-call debug için çoğu zaman bu kadarı yetiyor zaten (şaşırtıcı ama gerçek). Daha fazlası mı lazım oldu? O zaman ayrı bir kapı açılır, ayrı bir onay süreci çalışır.
Neyse, burada asıl mesaj şu aslında. Yetkiyi geniş tutarsanız rahat edersiniz gibi görünür ama sonra küçük bir hata bütün cluster’a yayılır; dar tutarsanız da operasyon biraz daha kontrollü gider. Siz ne dersiniz?
İşte tam da bu noktada devreye giriyor.
Evet.
Karşılaştırma: Geleneksel vs JIT Yaklaşımı
Neyse, size bir şey söyleyeyim, Farkı net görmek için bir tablo çıkaralım. Çünkü bazen lafı uzatınca konu dağılıyor, işte tam burada tablo işi baya toparlıyor.
| Kriter | Geleneksel (Bastion + SSH) | JIT Gateway + RBAC |
|---|---|---|
| Kimlik bilgisi ömrü | Aylar, bazen yıllar | Dakika / saat |
| Denetim izi | Paylaşılan hesap, karışık | Kişi bazlı, net |
| Komut kısıtlama | Yok (shell’e girdin mi herşey serbest) | Policy ile yönetilebilir |
| Onay mekanizması | Genelde manuel + email | Otomatik / workflow entegre |
| Kurulum maliyeti | Düşük ama teknik borç yüksek | Orta ama uzun vadede kazanç |
| Uyumluluk (KVKK/BDDK) |
Aslında, Evet. Buradaki asıl mesele şu: geleneksel model ilk bakışta idare eder gibi duruyor, ama bir süre sonra kim neye girdi, hangi komutu çalıştırdı, neden o hesabı kullandı derken iş içinden çıkılmaz hâle geliyor.
Yani, JIT tarafında işe olay daha kontrollü gidiyor; erişim açılıyor, iş bitince kapanıyor, üstüne bir de RBAC ile yetkiyi ince ince ayarlıyorsun (tabii policy tarafını doğru kurarsan),. Kağıt üstünde değil pratikte de daha rahat nefes alıyorsun. Peki neden?
Neyse, çok dağıtmadan söyleyeyim: özellikle uyumluluk tarafında bu fark ciddi hissediliyor. Denetçi geldiğinde “kim erişti” sorusuna tek tek cevap verebilmek güzel şey, açık konuşayım. Bu konuyla ilgili GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımıza da göz atmanızı tavsiye ederim.
Açık konuşayım, Tam da öyle.
Türkiye’deki Şirketler İçin Ne Anlama Geliyor?
İtiraf edeyim, Burası kritik. Çünkü bu yaklaşım, her şirkete aynı şekilde oturmuyor; küçük ekipte ayrı dert, orta ölçekte ayrı konu, büyük kurumda işe bambaşka bir tablo çıkıyor. Hani ilk bakışta “tamam ya, bunu da ekleriz” diyorsunuz ama iş biraz büyüyünce mevzu değişiyor. Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımızda bu konuya da değinmiştik.
Küçük ekipseniz (5-20 kişi): Açık konuşayım, tam teşekküllü bir JIT gateway kurmak şu aşamada biraz fazla kaçabilir. Onun yerine şunları yapın: (1) RBAC’i ciddiye alın, namespace-scoped role’ler yazın. (2) kubectl erişimini SSO ile entegre edin (Entra ID, Google Workspace vb.). (3) Audit logging’i açın — en azından “kim ne yaptı” sorusuna cevap verebilin. Bu üç adım bile sızı baya ileri taşır, yüzde 70 civarı bir yere getirir gibi düşünün. Daha fazla bilgi için Google Ads Advisor: Reklam Hesabınızı Koruyan 3 Yeni Özellik yazımıza bakabilirsiniz.
Bunu biraz açayım.
Orta ölçek (20-100 kişi): İşte burada Teleport, Boundary ya da açık kaynak alternatiflerine bakmanın vakti geliyor. Self-hosted Teleport Community Edition ücretsiz ve şaşırtıcı derecede iş görüyor; bir fintech müşterimizde kurduk, iki hafta içinde yerine oturdu (tabi ilk günlerde birkaç ufak pürüz çıktı). Maliyeti mi? Neredeyse sadece insan emeği.
Büyük kurumsal (100+ kişi, regülasyona tabi): Burada artık pazarlık payı kalmıyor. Access broker resmen ihtiyaç oluyor. Teleport Enterprise, CyberArk, HashiCorp Boundary gibi kurumsal çözümlere yöneliyorsunuz; Azure tarafındaysanız Azure DevOps Advanced Security: Tek Tıkla CodeQL Devri gibi güvenlik katmanlarıyla birleşince fena olmayan bir stack ortaya çıkıyor. Neyse, çok dağıtmayayım; olayın özü şu: denetim istiyorsanız araç seti de ona göre olacak. CodeQL YAML ile Sanitizer Tanımlama: Pratik Rehber yazımızda bu konuya da değinmiştik.
Maliyet tarafına da bakalım — Teleport Enterprise lisansı kullanıcı başı aylık 15-25 USD civarında geziyor. 50 kişilik bir DevOps ekibi için bu rakam TL bazında aylık 40-60 bin TL’ye çıkabiliyor. Kulağa fazla geliyor mu? Peki bir güvenlik ihlali kaça patlar? Çoğu senaryoda 1-2 milyon TL’den başlıyor; yani hesap aslında pek de zor değil.
Peki neden?
İlk Uygulama: Nereden Başlamalı?
“Tamam ikna oldum, başlayalım” diyorsanız, bence işi bir anda büyütmeyin; önce küçük bir alan seçin, sonra yavaş yavaş genişletin, çünkü acele edilen RBAC işi genelde bir yerden patlıyor. Peki nasıl? Şu sırayla gitmek fena değil.
- Haftalar 1-2: Mevcut RBAC policy’lerini didik didik edin. Kim neye erişiyor, kim gereksiz yetki taşıyor, bunları dökün;
kubectl auth can-i --list --as=user@sirket.comkomutu burada baya iş görüyor. - Haftalar 3-4:
cluster-adminyetkisi olan kaç kişi var, bir bakın. Sayı yüksekse şaşırmayın; sonra bunu yarıya indirmek için hangi namespace-scoped alternatiflerin ayağa kalkacağını planlayın (bazı ekipler burada biraz itiraz ediyor, normal). (bence en önemlisi) - Haftalar 5-8: Pilot bir access broker seçin. Tek bir namespace yeter, 3-4 gönüllü kullanıcıyla deneyin, loglara bakın, sonra feedback toplayın; ilk denemede her şey cuk oturmaz ama zaten amaç da bu değil. (bu kritik)
- Haftalar 9-12: Yaygınlaştırmaya başlayın. Ama durun, eski sistemi hemen sökmeyin; bir süre paralel çalıştırın ki ters giden bir şey olursa geri dönmek kolay olsun. (bu kritik)
Bu arada, Kubernetes tarafında olan biteni de göz ucuyla takıp edin (yanlış duymadınız). Çünkü bazen ufak görünen bir sürüm notu, authentication tarafında beklenmedik bir kapı açıyor (veya tam tersi, kullandığınız akışı sessizce bozuyor), o yüzden ben böyle konularda güncel kalmayı seviyorum. Kubernetes v1.36 Neler Getiriyor: Büyük Değişiklikler yazısında yeni authentication özelliklerine dair notlarım var.
Karşılaştığım Gerçek Bir Problem
Vallahi, İlk kez bir JIT gateway kurduğumda, 2023’te bir sigorta şirketindeydik. Açık konuşayım, beklemediğim bir duvara tosladım. Ekip tamam dedi, RBAC’ler yazıldı, onay akışları da yerine oturdu; ama sonra gece 03:00’te kritik bir incident patladı ve onay verecek kişi uyuyordu. Sistem çalışmadı. Neden önemli bu? İnsan tarafını hesaba katmamıştık.
Durun, bir saniye.
Çözüm neydi? Break-glass hesabı. Yani gerçekten açıl durumlar için ayrılmış, HSM’de tutulan, kullanıldığında otomatik olarak CISO’ya ve CTO’ya SMS atan özel bir hesap; üstüne bir de kullanım sonrası post-mortem şartı var, öyle “bir kere açtık bitti” kafası değil. Yılda 1-2 kere kullanıldı, garip gelebilir ama iş görüyor (ki bu çoğu kişinin gözünden kaçıyor)
Ders: Hiçbir güvenlik sistemi %100 değildir. Kaçış valfi (break-glass) tasarlamazsanız, insanlar kendi yolunu açar — ve çoğu zaman o yol, planladığınızdan daha kötü ölür.
Peki Bu Yaklaşım Mükemmel mi?
İnanın, Açık konuşayım: değil. Birkaç pürüz var, hatta ilk bakışta ufak gibi duran ama sahada can sıkan türden şeyler.
Yani, Birinçisi, öğrenme eğrisi. Ekip alışana kadar homurdanma çıkıyor, bu normal; mesela biri “eskiden kubectl exec atıyordum, iki saniyeydi” diyor, sonra bir anda onay bekleme, token alma, gateway’e bağlanma derken akış uzuyor. Doğru, biraz yavaşlıyor. Ama güvenlik her zaman hız demek değil.
İkincisi, kurulum karmaşıklığı. Gateway’in kendisi tek bir arıza noktası olabilir, burada şaka yok; o yüzden HA kurmak gerekiyor (yoksa bir gün gider ve herkes kapıda kalır). Gateway çökerse kimse cluster’a erişemez — bu senaryoyu test edin. Evet.
Üçüncüsü, maliyet. Kurumsal çözümler ucuz olmuyor, bunu süsleyip püslemeye gerek yok; açık kaynak tarafında alternatifler var. Bu kez de operasyon yükü size dönüyor, yani parayı başka yerden ödüyorsunuz.
Yani işin aslı şu: bu da bir trade-off. Mükemmel çözüm yok; sadece senin durumun için daha iyi olan çözüm var. Tam da öyle.
Sıkça Sorulan Sorular
cluster-admin yetkisini tamamen kaldırabilir mıyım?
Tamamen kaldırmak açıkçası pek mümkün değil, çünkü bazı operasyonlar gerçekten cluster genelinde yetki istiyor. Ama sürekli sahip olan kişi sayısını ciddi ölçüde düşürebilirsin. Bence ideal olan şu: sadece break-glass senaryolarında kullanılsın. Günlük işler zaten namespace-scoped role’lerle yönetiliyor.
Küçük bir startup için Teleport gibi araçlar overkill mi?
Çoğu zaman evet, kesinlikle. Yani 10 kişilik bir ekipseniz, önce RBAC hijyeninizi düzeltin, SSO entegrasyonu yapın, bir de audit logging açın. Bu üçlü bile sızı çok ileri taşır aslında. Büyüdükçe ihtiyaç kendiliğinden ortaya çıkacak, o zaman geçersiniz.
Gateway çökerse ne ölür? Cluster’a hiç erişemez mıyım?
Haklı bir endişe bu. İki şey lazım: (1) Gateway’i HA olarak kur, tek pod olarak değil. (2) Bir de break-glass mekanizması tasarla — harika durumlarda doğrudan cluster erişimi için güvenli bir yol olsun yaninda. Tecrübeme göre bu genelde HSM’de tutulan, kullanımı loglanan bir kimlik bilgisi oluyor.
Audit loglarını nerede saklamalıyım?
Tartışmasız cluster’ın dışında, değiştirilemeyen bir yerde olmalı. Azure kullanıyorsanız mesela Log Analytics Workspace + immutable storage kombinasyonu gayet iyi çalışıyor — valla güzel iş çıkarmışlar —. AWS tarafında işe CloudWatch + S3 Object Lock. KVKK uyumu için en az 2 yıl saklaman iyi bir fikir, regülasyona tabi sektörlerde bu 5-10 yıla kadar çıkabiliyor.
RBAC değişikliklerini nasıl test ederim, prod’u kırmadan?
kubectl auth can-i komutu tam burada devreye giriyor, en iyi arkadaşın yani. --as ve --as-group flag’leri ile başka bir kullanıcı adına simüle edebilirsin. Bence bunu CI pipeline’ına da eklemek çok mantıklı — her RBAC değişikliğinde belirli senaryoları otomatik test etsin.
Kaynaklar ve İleri Okuma
Kubernetes RBAC Resmî Dokümantasyonu — RBAC’in tüm detayları, API referansı ve örnek policy’ler için ilk bakılacak yer.
Kubernetes Audit Logging — Audit policy’leri yapılandırma. Log backend seçenekleri hakkında detaylı bir rehber (ki bu çoğu kişinin gözünden kaçıyor)
Teleport Resmî Dokümantasyonu — JIT access broker kurmak isteyenler için pratik, açık kaynak bir alternatifin dokümantasyonu.
NSA/CISA Kubernetes Hardening Guide — Resmî ve geniş bir Kubernetes güvenlik sertleştirme rehberi. PDF olarak indirilebiliyor.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar

Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



