Geçen sonbaharda, İstanbul’da bir ekip arkadaşımın prod’a attığı masum görünen bir deploy yüzünden p99 gecikme bir anda zıpladı. Grafana açık, Jaeger açık, loglar yağmur gibi akıyor… ama kimse “tam olarak hangi metod patladı?” sorusuna net cevap veremiyor (bu konuda ikircikliyim). İşin sınır bozucu kısmı da buydu zaten: herkes bir şeyler görüyor, kimse bütün resmî görmüyordu.
Bilmem anlatabiliyor muyum, İşte tam bu noktada küçük ama bayağı zekice bir fikir dikkatimi çekti: deploy ile method-level performans değişimini yan yana koyan, üstelik terminalden diff alınabilen hafif bir araç. Açık konuşayım, ben bu tarz araçlara önce temkinli yaklaşırım — kağıt üstünde süper durur, pratikte ya fazla gürültü çıkarır ya da kurulumu can sıkar. Ama burada hikâye biraz farklı. Çünkü amaç gösteriş değil, doğrudan teşhis.
Durun, bir saniye.
Neden böyle bir araca ihtiyaç var?
Bakın şimdi… Performans problemi çıktığında ilk refleks hep aynı oluyor. Önce dashboard’a bakılıyor, sonra tracing açılıyor, ardından loglarda anahtar kelime aranıyor. Bazen commit diff’i de işin içine giriyor — hepsi tek tek mantıklı, sorun şu ki bunları insan eliyle birbirine bağlamak, özellikle de olay üretimdeyse. Bu ne anlama geliyor? Kullanıcı şikâyeti gelmişse, ciddi zaman yiyor.
Dürüst olmak gerekirse, Birkaç yıl önce Ankara’daki küçük bir SaaS projesinde benzerini yaşamıştım. Deploy sonrası ödeme akışı normal görünüyordu ama sipariş oluşturma tarafında sessizce şişen bir gecikme vardı. O gün tam 40 dakika boyunca yanlış servise baktığımızı hatırlıyorum. Meğer asıl dar boğaz çok sıradan görünen createOrder yolundaymış (yanlış duymadınız). Böyle anlarda insan şunu düşünüyor: “Bunu bana niye daha hızlı söyleyen bir şey yok?”
Bu tıp araçların değeri tam burada başlıyor. Mesele sadece gözlemlemek değil; gözlemi aksiyona çevirmek. Neden önemli bu? Eğer sistem sana “şu metod 14 ms’den 91 ms’ye çıktı” diyebiliyorsa, artık kahve fincanını kapıp rastgele kazı yapmazsın.
Klasik izleme neden yetmiyor?
Klasik APM çözümleri kötü demiyorum… Hatta çoğu durumda fazlasıyla işe yarıyorlar. Gel gelelim, dağıtılmış sistemlerde problem genelde mikro düzeyde başlıyor. O mikro kırılmayı bulmak için iyi niyet yetmiyor. Yetmiyor işte.
- Grafana: trendi gösteriyor, suçluyu genelde göstermiyor.
- Tracing: güzel iz bırakıyor ama her çağrıyı tek tek okumak yorucu.
- Loglar: ayrıntılı evet, ama gürültü de tam o kadar.
- Commit diff: kod değişikliğini anlatıyor, etkisini her zaman anlatmıyor.
Bence en büyük eksik tam burasıydı zaten: deploy ile davranış değişimi arasındaki köprünün zayıf olması.
Araç ne yapıyor, nasıl çalışıyor?
Söz konusu yaklaşım Spring ekosistemine yaslanıyor ve işi mümkün olduğunca görünmez hâle getiriyor. Uygulamadaki servisler otomatik olarak sarılıyor; yani business code içine gidip her metoda elle ölçüm koymanız gerekmiyor. Bu iyi haber. Kötü haber? Her şey sihir gibi görünse de altında epey disiplin var — proxy’ler, AOP katmanı, async kayıt mekanizması ve commit bazlı ayrıştırma gibi parçalar birlikte çalışıyor. Daha fazla bilgi için Claude Code ile Hata Düzeltmeyi Otomatikleştirmek: PR’a Giden Yol yazımıza bakabilirsiniz.
Hmm, bunu nasıl anlatsamdı… Bu konuyla ilgili Razer’ın İki Kulaklığı: Benzer Görünüp Ayrılan İnce Çizgi yazımıza da göz atmanızı tavsiye ederim.
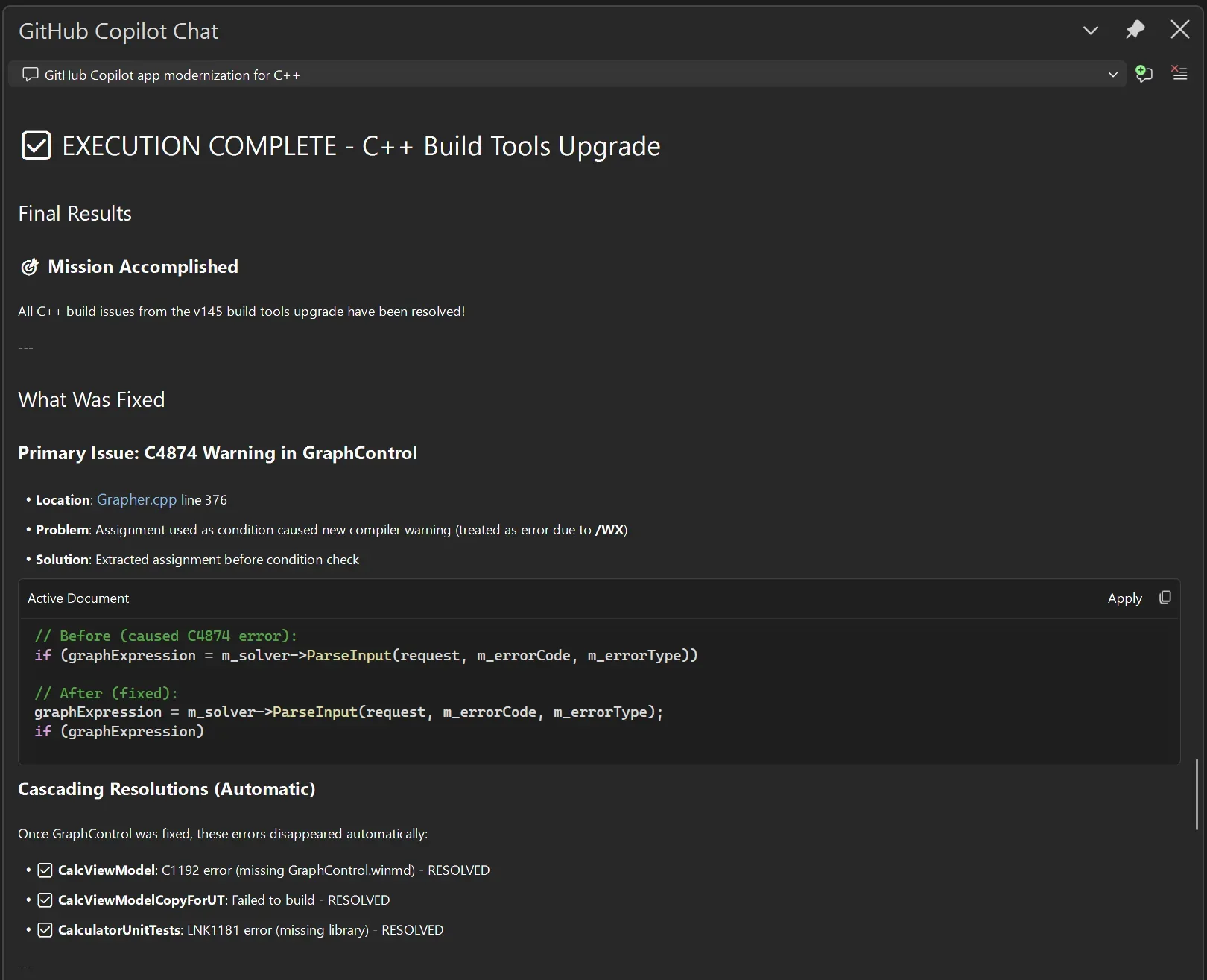
İtiraf edeyim, Editör masasındayken bunu test ettiğimde — geçen hafta Kadıköy’deki ofiste — ilk merak ettiğim şey şu oldu: “Bu kadar az kurulumla gerçekten anlamlı veri çıkacak mı?” Şaşırdım açıkçası. Uygulama açılırken ortamdan commit hash okuyor ve ölçülen süreleri yerel SQLite veritabanına atıyor; sonra iki deploy’u karşılaştırırken farkları direkt listeliyor.
# Örnek kullanım mantığı
export GIT_COMMIT_HASH=$(git rev-parse --short HEAD)
./gradlew bootRun
curl http://localhost:8080/actuator/lofi/a3f9c1
curl "http://localhost:8080/actuator/lofiDiff?base=a3f9c1&head=d82e04"
Hani, Aslında — dür bir saniye, önce şunu söyleyeyim. Böyle araçlarda “zero-config” lafını çok severler ama çoğu zaman mutfağa girince kablo dökülür çıkar — itiraf edeyim, beklentimin üstündeydi —. Burada işe temel vaat makul görünüyor; dependency ekle, actuator’ı aç, commit bilgisini ver ve gerisini sisteme bırak. Basit. Postgres LISTEN/NOTIFY Debugging’i Nihayet Rahatlatan Yöntem yazımızda bu konuya da değinmiştik. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
| Metod | Önce | Sonra | Fark |
|---|---|---|---|
OrderService.createOrder() |
14.23ms | 91.00ms | +76ms civarı |
UserService.findById() |
3.xx ms | bayağı yakın değerler | sorun yok gibi |
Neyi bilerek ölçmüyor?
Bence bu kısım önemli. Araç her şeyi ölçmeye kalkmıyor ve doğru yapıyor da denebilir. Spring internals’ı pas geçmesi mantıklı; yoksa kendi kalbini dinleyen garip bir doktor gibi olurdu işte. Servlet filter zinciriyle kavga etmemesi de hoş, çünkü güvenlik katmanlarında proxy-on-proxy karmaşası insanı çileden çıkarabiliyor.
@aspect sınıflarını dışarıda bırakması da ayrıca iyi düşünülmüş. Benzer çatışmaları geçen yıl İzmir’de kurumsal bir projede yaşamıştık; aspect zinciri uzadıkça nerede neyin kaç kere sarıldığını takıp etmek eziyete dönüyordu. JDK dynamic proxy kullanan repository tarafını ayrıca kovalamaması işe pratik bir karar, çünkü zaten üst servis çağrısı üzerinden toplam süreyi görmek yeterli olabiliyor.
Kurulum kolaylığı mı, operasyon rahatlığı mı?
Lafı gevelemeden söyleyeyim: bu tür ürünlerde asıl başarı kurulum ekranının kısa olması değil, operasyon sırasında kafa yormaması. Bir startup için bu çok kritik; çünkü ekipte iki backend mühendisi varsa biri feature yazarken diğeri observability panelleriyle boğuşamaz. Boğuşamaz, ciddi söylüyorum. Daha fazla bilgi için Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımıza bakabilirsiniz.
Küçük ekip senaryosunda avantaj net: tek komutla devreye giren ölçüm, lokal SQLite üzerinde saklanan veriler, terminalden alınan diff… Bunlar düşük bütçeli ekiplerin sevdiği şeyler. Şahsen benim hoşuma giden taraf da buydu; abartılı platform bağımlılığı yok, ağır ajan yükleme zorunluluğu yok. Sade.
Vallahi, E tabi enterprise tarafta tablo biraz değişiyor. Orada merkezî loglama, uzun süre saklama, RBAC, veri erişim politikaları devreye giriyor. Yerel dosya tabanlı depolama ilk aşamada fena değil. Büyüdükçe sınırlarına dayanabiliyor — bu da doğal, küçük araçların kaçınılmaz kaderi biraz.
Peki eksikleri yok mu?
Var elbette. Beklediğim kadar kusursuz bulmadığım birkaç nokta var. Mesela yerel depolama yaklaşımı küçük ortamda şahane iken yoğun trafik altında yönetim yükü yaratabilir. Ayrıca metod seviyesinde regresyon görmek çok faydalı olsa da bazen gerçek sebep metodun kendisi değildir; cache bozulmuştur, DB bağlantısı sıkıntıya girmiştir ya da dış API yavaşlamıştır. Araç bunu sana söyleyemez.
“Metod yavaşladı” demek çoğu zaman başlangıç noktasıdır; son söz değildir.
Bir başka deyişle, teşhis hızlanıyor ama analiz ihtiyacı bayağı ortadan kalkmıyor.
Yine de açıkçası, çoğu ekip için bu bile büyük rahatlık.
Nerede gerçekten parlıyor?
Bence en güçlü olduğu yer release sonrası hızlı triage aşaması (ki bu çoğu kişinin gözünden kaçıyor). Bilhassa CI/CD ritmi yüksek takımlarda her deploy’dan sonra “acaba ne bozuldu?” sorusu hiç bitmiyor; bu aracı kullanınca sorgu listesi kısalıyor, hatta bazen tartışma bile sona eriyor. Konforlu. Gerçekten konforlu.
Tersinden bakarsak, performans mühendisliği yapan biri için bunun anlamı daha derin: regresyonu commit’e bağlayıp method bazında kıyaslayınca hipotez kurmak kolaylaşıyor. Mantıklı değil mi? Ben buna eski usul dedektiflikten modern kriminal laboratuvara geçmek gibi bakıyorum; büyüteci elinizde tutuyorsunuz, masanın üstünde delil kaybolmuyor.
Bunu kim kullanmalı?
Küçük startup’lar için cevap net: evet, denenir (ciddiyim). Hele Java / Spring Boot hattında koşuyorsanız, düşük sürtünmeli gözlemleme ciddi vakit kazandırabilir. Kurumsal tarafta işe bence ilk soru teknik değil yönetsel ölür: veriyi nereye koyacaksınız, retention politikası ne olacak, güvenlik incelemesinden geçecek mi? Bunlar tamam işe araç bayağı iş görebilir.
- MVP ekibiyseniz: hızlı kazanım sağlıyor.
- SRE ağırlıklı çalışıyorsanız: daha dar regresyon analizi sunuyor.
- Kurum içi platform takimiysanız: sisteme uyarlamak için ekstra entegrasyon gerekebilir.
- Düşük trafikliyse: daha az maliyetle görünürlük veriyor.
- Aşırı regülasyon varsa: bölgesel veri saklama ve erişim kontrolünü ayrıca düşünmek gerekiyor.
Sıkça Sorulan Sorular
Deploy sonrası p99 neden bir anda zıplar?
Genelde tek bir endpoint veya tek bir kritik metodun maliyeti artar; bu da kuyruk gecikmesini (p99) hemen etkiler. Dashboard’lar çoğu zaman trendi gösterir ama “hangi metod değişti?” sorusuna doğrudan cevap vermez. En pratik yaklaşım, deploy öncesi/sonrası metod düzeyinde metrik farkını hızlıca görmek.
Grafana ve Jaeger varken neden ekstra bir “metod fark” aracı gerekir?
Grafana trend verir, Jaeger de akışın izini sürer; ama ikisi de çoğu zaman teşhis süresini uzatır. Tracing’de her çağrıyı tek tek okumak yorucu, loglarda arama işe gürültüye takılabiliyor. Benzer bir süreçte “herkes bir şey görüyor ama kimse net değil” durumunu yaşadığım için, metod bazında farkı terminalde görmek gerçekten hız kazandırıyor.
Bu tarz araçlar “tahmin” yerine nasıl teşhis yapıyor?
Temel fikir şu: deploy sonrası performans değişimini tahminle değil, metrik farkıyla yakalamak. Yani “şu metod 14 ms’den 91 ms’ye çıktı” gibi doğrudan karşılaştırma sunarsan, suçluyu aramak yerine doğrulama yaparsın. Böyle olunca incident süresi ciddi şekilde kısalıyor.
Kurulum/operasyon yükü çok ölür mu?
Her araçta olduğu gibi bir miktar kurulum gerekir ama hedef, “fazla gürültü” üretmeyen hafif bir akış kurmak. Terminalden diff alabilmek ve deploy sonrası metod performansını hızlı karşılaştırmak, günlük operasyon yükünü azaltır. Benim gördüğüm en iyi senaryo, aracı sadece “deploy sonrası teşhis” anında kullanıp sürekli çalıştırmamak oluyor.
Spring ekosistemine dayanmak ne kazandırır?
Spring tarafında metod çağrılarını ve uygulama içi davranışı izlemek daha standardize olabilir; bu da araçların daha tutarlı sinyal üretmesini sağlar. Böylece “hangi handler/metod etkilenmiş” sorusuna daha düzgün yanit alınır. Özellikle prod ortamında hızlı kök neden bulma hedefi olan ekipler için bu yaklaşım pratik oluyor.
Kaynaklar ve İleri Okuma
Azure Application Insights ile performans izleme
Zipkin (Jaeger/Tracing ekosistemiyle ilgili) GitHub

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.