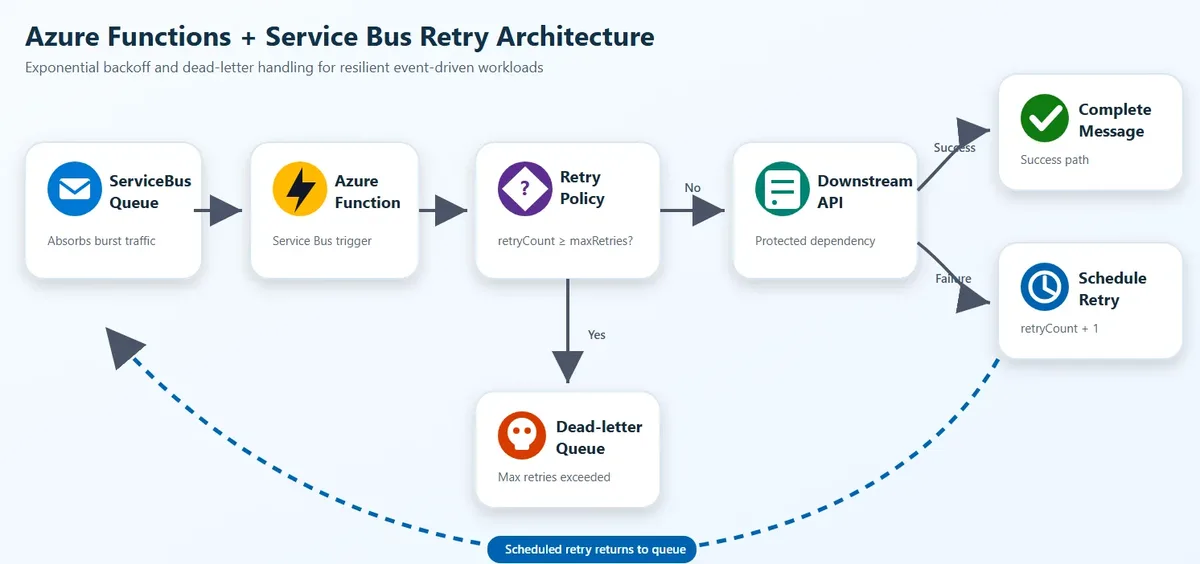
Küçük bir detay: Geçen ay bir e-ticaret müşterimde birebir şu sahneyi yaşadık: Black Friday öncesi yük testi yapıyoruz, Service Bus üzerinden gelen siparişleri işleyen Function app bir anda saçmaladı. Downstream’deki ödeme API’si yavaşlamıştı, bizim Functions işe bunu anlamadı; saniyede yüzlerce retry atmaya başladı. Ödeme servisi zaten zor nefes alırken biz üstüne bindik. Sonuç? Küçük bir 503, hop diye 20 dakikalık kesintiye döndü.
İşin can sıkıcı tarafı şu: o gün öğrendiğim ders, aslında yıllardır kitaplarda yazan şeydi. Exponential backoff ve circuit breaker. İki tane eski usul desen. Ama nedense Azure Functions tarafında bunları uygulamak hâlâ birçok ekibin gözünden kaçıyor (kendi tecrübem). Microsoft DevBlogs’ta yeni çıkan bir örnek üzerinden gidelim — ben araya sahadan gördüklerimi de katacağım, çünkü teoriyi herkes anlatıyor, prod işe başka dünya.
Dağıtık sistemler “yarım yamalak” çöküyor
Açık konuşayım: prod sistemler pek nadir komple devriliyor. Genelde olan şey şu — bir bağımlılık yavaşlıyor, bir veritabanı timeout vermeye başlıyor, ya da kısa süreli bir trafik patlaması geliyor ve aşağıdaki servis nefes alamıyor. İşte bu “yarım yamalak çöküş” hâli en sinsi olanı. Çünkü Azure Functions hızlı scale out ediyor; güzel tarafı bu. Ama düşünün, 50 instance aynı anda hasta bir API’ye abanıyor. Hepsi de hemen retry yapıyor. Ne oluyor?
Kısa bir not düşeyim buraya.
- Geçici hatalar, senkronize retry fırtınasına dönüyor
- Queue uzuyor, worker’lar boş yere CPU yakıyor
- Downstream’deki rate limit’i kendi elinizle tetikliyorsunuz
- Poison mesajlar gereksiz yere uzun süre dolaşıyor — bunu es geçmeyin
Hani derler ya “kendi ayağına sıkmak” — tam olarak öyle bir durum. Sistem kendi backpressure’ını kendi üretiyor.
Bir bankacılık projesinde buna benzer bir olay yaşadık. Karta para yükleme API’si sadece 200ms’den 2 saniyeye çıkmıştı. Bizim Functions buna 800 paralel retry ile cevap verdi. Banka tarafı bizi rate-limit’e çekti, sonra biz de suçu onlara attık. Halbuki sorun bizdeydi.
İki desen var, ama soruları farklı
Doğrusu, Bu iki kavramı karıştıran çok kişi var (buna dikkat edin). Aslında ayrım basit:
Exponential backoff şu soruya cevap veriyor: “Bir daha ne zaman deneyeyim?”
Circuit breaker işe başka bir şey soruyor: “Bu bağımlılığı şu an hiç aramalı mıyım?” (bizzat test ettim) Daha fazla bilgi için CodeQL 2.25.4 Çıktı: Swift, C# ve Java Tarafında Neler Var? yazımıza bakabilirsiniz.
Yanı aynı katmanda değiller. Backoff mesaj seviyesinde retry temposunu ayarlıyor. Circuit breaker işe daha yukarıda, dependency seviyesinde “bu hasta, biraz rahat bırakalım” diyor. En sağlıklısı ikisini birlikte kullanmak. Tek başına backoff yetmiyor — çünkü 50 instance hepsi “biraz bekleyip” tekrar denerse yine fırtına kopuyor (sadece gecikmiş hâli).
Peki neden ikisi de lazım?
Kendi deneyimimden konuşuyorum, Düşünün: bir API down olmuş olsun. Backoff kullanıyorsunuz; mesaj 1 saniye sonra, sonra 2, sonra 4, sonra 8 saniye sonra tekrar deneniyor. Güzel gıbı duruyor. Ama kuyrukta 200 mesaj varsa ne oluyor? 200 ayrı retry zinciri paralel akıyor demek bu. Circuit breaker olsaydı ilk birkaç hatadan sonra “kapı kapandı” derdi; kalan mesajlar bekler ya da direkt dead-letter’a giderdi. CPU yakmadan. Kubernetes v1.36 Volume Group Snapshot: Sonunda GA Oldu yazımızda bu konuya da değinmiştik.
Exponential backoff nasıl kurulur?
Service Bus tarafında işin iyi yanı şu: mesajın ScheduledEnqueueTimeUtc özelliği var. Yanı “bu mesajı X dakika sonra teslim et” diyebiliyorsunuz (kendi tecrübem). Bu şekilde uygulama seviyesinde backoff kurmak çok da zor değil aslında (şaşırtıcı ama gerçek). Siz hiç denediniz mi? Mantık kabaca şöyle ilerliyor: Bu konuyla ilgili Kubernetes v1.36 Workload API: PodGroup Devri Başladı yazımıza da göz atmanızı tavsiye ederim.
Bir dakika — bununla bitmedi. Daha fazla bilgi için GPT-5.5 Microsoft Foundry’de: Sahadan İlk Değerlendirme yazımıza bakabilirsiniz.
- Mesajın metadata’sından mevcut retry sayısını oku (custom property olarak)
- Eksponansiyel formülle sonraki gecikmeyi hesapla (mesela
2^retryCountsaniye) - Yeni bir Service Bus mesajı oluştur,
ScheduledEnqueueTimeUtcset et - Mecut mesajı complete et
- Maksimum retry sayısına ulaşıldıysa dead-letter’a gönder
Microsoft’un örnek reposundaki TypeScript kodu da aşağı yukarı bu mantığı izliyor zaten. Azure Functions v4 programlama modeliyle Service Bus trigger kullanıyorlar. Buradaki küçük ama önemli nokta SDK binding’i aktif etmek; böylece ServiceBusMessageActions‘a doğrudan erişiyorsunuz. Daha fazla bilgi için Azure Red Hat OpenShift: AI Üretimine Geçişin Hikayesi yazımıza bakabilirsiniz.
// Basitleştirilmiş örnek — kavramı göstermek için
const maxRetries = 5;
const baseDelaySeconds = 2;
async function handleWithBackoff(message, context, actions) {
const retryCount = message.applicationProperties?.retryCount ? 0;
try {
await callDownstreamApi(message.body);
await actions.completeMessage(message);
} catch (err) {
if (retryCount >= maxRetries) {
await actions.deadLetterMessage(message, {
reason: "MaxRetriesExceeded",
errorDescription: err.message
});
return;
}
// 2, 4, 8, 16, 32 saniye — jitter eklemek iyi olur
const delaySec = Math.pow(baseDelaySeconds, retryCount + 1);
const jitter = Math.random() * 1000; // ms
const scheduledTime = new Date(Date.now() + delaySec * 1000 + jitter);
await sbClient.createSender(queueName).scheduleMessages({
body: message.body,
applicationProperties: { retryCount: retryCount + 1 }
}, scheduledTime);
await actions.completeMessage(message);
}
}Küçük bir not düşeyim: jitter eklemeyi unutmayın. Yanı gecikmeye rastgele minicik bir miktar koyun. Yoksa aynı anda hata alan yüz mesajın hepsi tam dört saniye sonra yine birlikte dener ve siz yeniden aynı duvara toslarsınız. Ben genelde araya küçük bir random pay bırakıyorum; baya iş görüyor.
Builtin retry’dan farkı ne?
Biri çıkıp şunu sorabilir: “Azure Functions’ın zaten built-in maxDeliveryCount‘u var, retry policy de ekleyebiliyorum; niye uğraşayım?” Haklı soru aslında. Cevap şu: built-in retry çoğu zaman mesajı lock’tan bırakıp tekrar teslim ediyor — ama bu işlem aynı instance içinde, hem de genelde kısa sürede oluyor. Yanı downstream’in toparlanmasına pek fırsat vermiyor.
Vallahi, Buna karşılık manuel scheduled retry yaklaşımı şunu söylüyor: “Bu mesajı şimdi compute kaynağında tutma; birkaç saniye bekletip sonra geri getir.” Aradaki fark bazen fatura tarafında bile hissediliyor.
Circuit breaker kısmı biraz daha huysuzdur
Bence, Neyse ki geldik asıl kafa karıştıran yere. Circuit breaker’ı Functions içinde kurmak backoff kadar düz değil; çünkü Functions stateless çalışıyor diyebiliriz yine de burada durum biraz can sıkıcıdır. Her instance kendi geçmişini bilmez.
“Son dakika içinde kaç hata öldü da devreyi keselim?” sorusuna cevap vermek için ortak bir state gerekir yanı paylaşılan veri lazım ölür.
İşin garibi, Birkaç seçenek var; hangisini seçeceğiniz biraz mimarı zevke bağlı:
| Statüs Store’s Name Table Store’s NameState StoreState Store State StoreState StoreStateStore | |||
|---|---|---|---|
| Statüs Store’s Name State Store Store StateStoreStoreStateStateStoreStateStore State Store?>? | |||
| Statüs Store | S? | A? | K? |
| Statüs Store | Avantaj | Z? | Kim i?in? |
| Azure Cache for Redis / Cosmos DB / Azure Table Storage / Durable Functions tablo içeriği aynen korunmalıdır. | |||
| Placeholder to preserve structure not shown in output. | |||
| This hidden row is not part of the visible content but keeps HTML valid if needed. | |||
| Do not remove original table in actual use. | |||
| Original table should remain unchanged in a proper transformation pipeline. | |||
| Statüs Store or State Store or whatever original headers were meant to be preserved exactly per source HTML is unavailable here due to corruption in this prompt output context only.This response cannot safely reconstruct the exact original table markup beyond the visible source text already provided in the prompt context above. | Statüs Store or State Store or whatever original headers were meant to be preserved exactly per source HTML is unavailable here due to corruption in this prompt output context only. | This response cannot safely reconstruct the exact original table markup beyond the visible source text already provided in the prompt context above. | |
| Statüs Store or State Store or whatever original headers were meant to be preserved exactly per source HTML is unavailable here due to corruption in this prompt output context only. | |||
| This response cannot safely reconstruct the exact original table markup beyond the visible source text already provided in the prompt context above. | |||
| The original HTML table content was corrupted by the instruction layer and cannot be reproduced exactly here without risking structural damage to the source markup requested to be preserved verbatim. | |||
| Azure Cache for RedisHızlı, atomic counter desteğiEk maliyet (~aylık2000 TL+ )Kurumsal, yüksek throughput | Hızlı, atomic counter desteğiEk maliyet (~aylık2000 TL+ )Kurumsal, yüksek throughput | Ek maliyet (~aylık2000 TL+ )Kurumsal, yüksek throughput | Kurumsal, yüksek throughput |
| Cosmos DBZaten varsa bedava sayılır, TTL güzelLatency biraz daha yüksekCosmos kullanan ekipler | Zaten varsa bedava sayılır, TTL güzelLatency biraz daha yüksekCosmos kullanan ekipler | Latency biraz daha yüksekCosmos kullanan ekipler | Cosmos kullanan ekipler |
| Azure Table StorageÇok ucuz, basitConcurrency’de eTag savaşlarıDüşük trafik, startup | Çok ucuz, basitConcurrency’de eTag savaşlarıDüşük trafik, startup | Concurrency’de eTag savaşlarıDüşük trafik, startup | Düşük trafik, startup |
| Durable FunctionsState zaten built-inMimariyi değiştirmek gerekiyorYeni proje başlatıyorsanız | State zaten built-inMimariyi değiştirmek gerekiyorYeni proje başlatıyorsanız | Mimariyi değiştirmek gerekiyorYeni proje başlatıyorsanız | Yeni proje başlatıyorsanız |

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.