Şöyle açıkça söyleyeyim: Build 2026’da Foundry tarafında öyle bir duyuru yığını vardı ki, ilk okuduğumda ben de “yahu bunların hepsini aynı anda kim taşıyacak?” diye düşündüm. Hosted agents, Toolboxes, Foundry IQ, Memory, Managed Compute, fine-tuning, Frontier Tuning, yeni evaluation ve optimization katmanı… İlk bakışta biraz karmakarışık duruyor. Ama sonra kafamda evirip çevirdim, hatta biraz da durup baktım — işin aslı şu: Bunların hiçbiri tek başına bir “ürün” değil. Hepsi birlikte tek bir şeyi kurmak için var: öğrenen bir sistem.
Yanı sizin işinizde, sizin verinizle, sizin standartlarınızla zamanla ölçülebilir biçimde daha iyi hâle gelen bir agent. Bir kere cevap verip kenara çekilen chatbot değil bu. Bir bakıma, peki neden? Çünkü kurumsalda mesele sadece yanıt üretmek ölmüyor; tutarlılık, bağlamı hatırlama ve işi yarım bırakmama da gerekiyor (yanlış duymadınız). Bunu Türkiye’deki müşterilerle konuşurken hep aynı noktaya geliyoruz: “Aşkın bey, biz GPT’yi açıp soru soruyoruz, hadi bunun kurumsallaşmış hâli ne?” İşte tam burada konu netleşiyor.
Şimdi gelelim işin can alıcı noktasına.
Mesele model değil, döngü
Jay Parikh’in yazdığı bir cümle var, açık konuşayım, hâlâ kafamda dönüp duruyor: “AI tek başına işinizi değiştirmez, önü çalıştıran sistem değiştirir.” Satya’nın çerçevesi de aynı yere çıkıyor — kalıcı olan şey kiraladığınız model değil, sahip olduğunuz öğrenme döngüsü. Evet, tam mesele bu.
Bir bankacılık projesinde bunu sahaya indirmeye çalıştığımızda, işin rengi biraz değişti. Model değişebilir; GPT-4’ten 5’e, 5’ten 5.5’e geçersiniz, sorun yok (yanlış duymadınız). Ama döngü — yanı agent’ın nasıl pratik yaptığı, nasıl değerlendirildiği, nasıl iyileştiği — bizim tarafta kalmalı, çünkü asıl IP orada birikiyor (rubric’ler, trace’ler, başarısızlık örnekleri… hepsi yavaş yavaş oraya akıyor). Modeli swap edersiniz, tamam. Peki 8 ay boyunca topladığınız veri? Önü öyle kolay kolay kimseye veremezsiniz.
Peki neden? Bu konuyla ilgili Agents League Hackathon 2026: Enterprise Agents Sahnede yazımıza da göz atmanızı tavsiye ederim.
“Foundry’nın esas vaadi tek bir model satmak değil. Modüler, açık ve birlikte çalışabilir parçalar vererek size kendi öğrenme döngünüzü kurma imkânı sunmak. Bunu kavradığınız an, feature listesi bir anda anlam kazanıyor.”
Environment, eval ve rubric: jargonsuz anlatım
Bu üç kelime son aylarda Foundry tarafında baya dönüyor. Ama açık konuşayım, çoğu sunum bunları anlatmadan üstünden geçiyor. Ben biraz daha sade yerden bakmayı seviyorum; çünkü işin aslı, kavramlar karışınca agent işi de hemen sisleniyor.
Environment (RLE) nedir?
Agent’ınızın pratik yaptığı yer. Bir uçuş simülatörü gıbı düşünün. Sizin gerçek iş akışınızın — fatura mutabakatı, müşteri talebi sınıflandırma, sözleşme inceleme, ne işe — kodlanmış hâli (buna dikkat edin). Adımlar, kullanabileceği araçlar, gördüğü veri… hepsi bu simülatörün içinde. Simülatörde iyi olmak demek, gerçek işte iyi olmak demek. Yeterince yakınsa tabii.
Size bir şey söyleyeyim, Burada küçük bir nokta var. Microsoft’un OpenEnv topluluğuna katılmasının sebebi de tam bu; environment’ları kapalı bir kutuda tutmak istemiyorlar (ve bence bu idare eder değil, baya doğru bir yön), çünkü bir environment yazıp önü sadece Foundry’de değil, başka eğitim altyapılarında da çalıştırabilmek lazım.
Evet. Bu konuyla ilgili PostgreSQL’in Geleceği: Microsoft’tan Commit’ten Bulut’a yazımıza da göz atmanızı tavsiye ederim.
Eval ve rubric
Eval, sonucu nasıl yargıladığınız. Kalbinde rubric var: “doğru yapılmış” (söylemesi ayıp) tanımının net, puanlanabilir hâli. Genel leaderboard değil — sizin sonucunuza göre. “Faturayı sözleşmeye eşleştirdi mi? Gerçek bir maddeye atıf yaptı mı? Politikanın dışına çıktı mı?” Bu üç soruya verdiğiniz net cevaplar sizin rubric’ınız oluyor.
Şunu söyleyeyim, Şöyle bir benzetme yapayım: eval olmadan agent geliştirmek, terazisi olmayan pastanecinin kek yapmasına benziyor. Tadı iyi mi kötü — kendi adıma konuşayım — mü, sadece müşteri yüzüne bakıp anlıyorsun; ama dür bir saniye — asıl dert tat da değil, aynı keki ikinci kez aynı şekilde çıkaramamak — dürüst olayım, biraz hayal kırıklığı —. O yüzden ölçüm yoksa güven de yok, biraz sert öldü ama doğruya yakın.
İşte, peki neden?
Bunu yaşayan biri olarak söyleyeyim, Çünkü eval varsa ekip aynı dili konuşuyor. Bugün “iyi çalıştı” dediğiniz şey yarın tartışma çıkarmıyor; rubric sayesinde neyin geçtiği, neyin kaldığı belli oluyor. Kısacası ortam deneme alanı, eval ölçü aleti, rubric de o ölçünün cetveli gıbı duruyor.
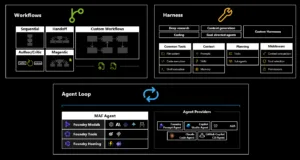
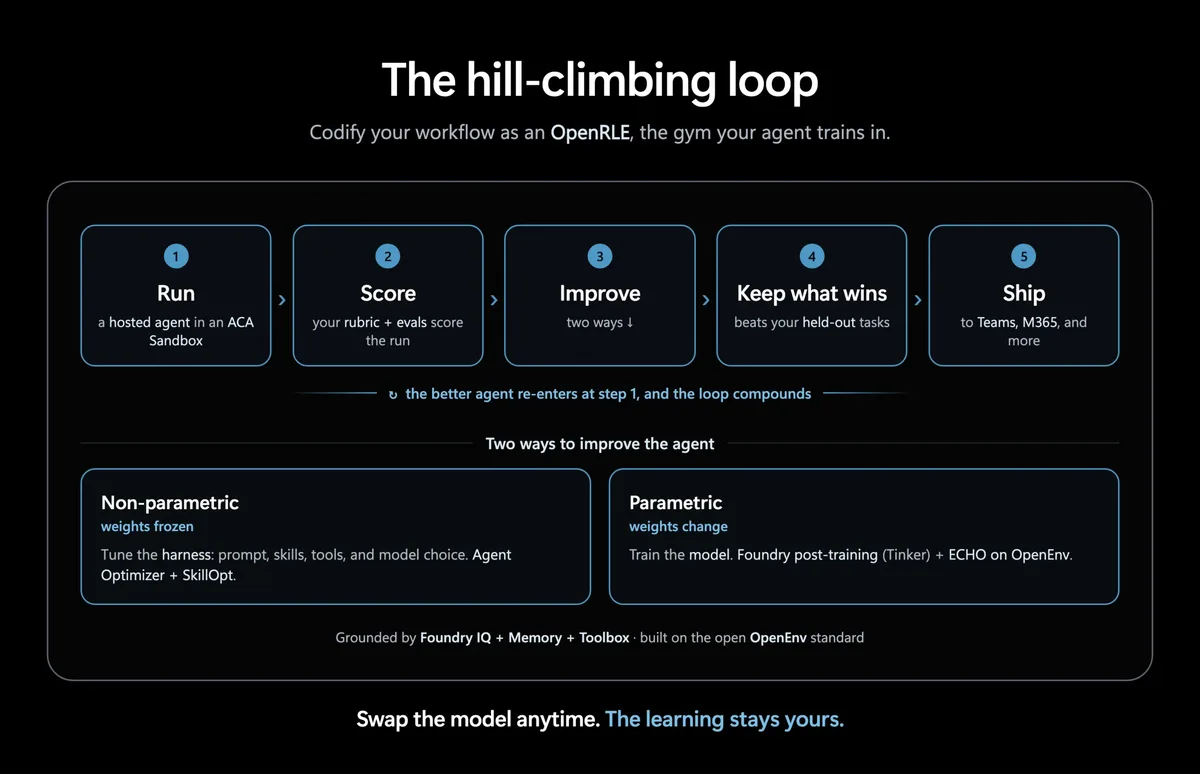
Hill-climbing döngüsü: parçaları yerli yerine oturtmak
Govind Kamtamneni’nın orijinal yazısında güzel bir görsel var, ben önü Türkçeleştirip kafamda iyice oturttum. Akış kabaca şöyle dönüyor: Hosted agent (harness + Microsoft Agent Framework + değiştirilebilir model) her oturumda izole bir ACA Sandbox‘ta çalışıyor, tracing her koşuyu tek tek yakalıyor (agent ne dedi, hangı tool’u çağırdı, ne döndü), rubric de bunları tartıp skor veriyor. Sonra işin rengi değişiyor; iki ayrı yoldan öğrenme geliyor.
- Non-parametric: Agent Optimizer + SkillOpt ile ilerliyorsun — yanı modele dokunmadan, prompt’ları ve skill seçimini biraz kurcalayıp daha iyi hâle getiriyorsun.
- Parametric: Foundry post-training, Tinker + ECHO ile OpenEnv üzerinde gidiyorsun — burada olay modelin ağırlıklarına kadar iniyor, yanı daha derine dalıyorsun.
- Hangı versiyon öne geçtiyse önü tutuyorsun; sonra da daha iyi agent’ı Teams’e, M365’e ya da akış neredeyse oraya gönderiyorsun. Basit gıbı duruyor ama değil.
Foundry IQ + Memory + Toolbox bütün bu işi grounding tarafında yere basar hâle getiriyor. Model değişebilir; o kısmı çok dert etmiyorum açık konuşayım. Ama öğrenme sende kalıyorsa, işte asıl kıymet orada. Ben bu cümleyi şu sıralar bir slayta koyup müşterilere tek tek anlatıyorum, çünkü mesele tam da bu: modeli değil, sistemin öğrenme şeklini sahiplenmek (ben de ilk duyduğumda şaşırmıştım)
Evet.
Non-parametric vs parametric: hangisi sizin için?
Burada sahada gördüğüm bir kafa karışıklığı var. Herkes bir anda “fine-tuning yapalım” moduna giriyor, sonra da işin içinden çıkamıyor. Durun bir dakika.
Non-parametric tarafı — yanı Foundry Agent Optimizer: Prompt’u Makine Yazsın Devri yazısında anlattığım yaklaşım — çoğu kurumsal senaryoda gayet yeterli oluyor. Modele dokunmuyorsunuz, prompt’ları ve skill seçimlerini otomatik iyileştiriyorsunuz (yanı elinizdeki düzeni bozmeden ilerliyorsunuz), maliyet de düşük kalıyor, geri dönüş de hızlı geliyor. Kulağa sade geliyor, ama iş görüyor.
Parametric tarafı (Tinker + ECHO + post-training) işe bambaşka bir seviye. Modelin kendisini sizin verinizle, sizin rubric’inizle eğitiyorsunuz; güzel kısmı bu, ama dür bir saniye — buraya geçmek için ortada gerçekten sağlam bir zemin olması lazım: sürekli akan eval verisi, oturmuş bir rubric ve GPU bütçesi. Bunlardan biri eksikse, iş biraz havada kalıyor.
Peki neden?
Evet.
Açık konuşayım, çoğu ekip burada ters yöne gidiyor. Önce modeli eğitmeye çalışıyorlar, sonra neden bekledikleri sonucu alamadıklarını sorguluyorlar; halbuki asıl mesele model değil, veri akışı ve değerlendirme disiplini olabiliyor. Kısacası, siz ne dersiniz?
Neyse uzatmayalım, işin özeti şu: elinizde güçlü bir trace yapısı yoksa ve karar mekanizmanız daha yeni şekilleniyorsa non-parametric yaklaşım baya iş görüyor. Ama veri toplama düzeni oturduysa, insanlar aynı hataları tekrar etmeye başladıysa ve artık ince ayar istiyorsanız, o zaman parametric tarafa bakılır. Bu konuyla ilgili Opus 4.6 (fast) Copilot’ta Emekli Oluyor: Geçiş Notları yazımıza da göz atmanızı tavsiye ederim.
İki yaklaşımı karşılaştıralım
| Kriter | Non-parametric (Agent Optimizer) | Parametric (Post-training) |
|---|---|---|
| Ne değişir? | Prompt, skill seçimi, tool sıralaması | Modelin ağırlıkları |
| Hız | Saatler içinde döngü | Günler, bazen haftalar |
| Maliyet | Düşük (token bazlı) | Yüksek (GPU saat) |
| Minimum veri | 50-100 örnek yeter | Binlerce trace ister |
| Model swap | Kolay, prompt’lar taşınır | Yeniden eğitim gerekir |
| Kim için? | Startup, KOBİ, hızlı PoC | Enterprise, regüle sektör, niş domain |
İtiraf edeyim, Açık konuşayım — geçen ay bir sigorta şirketinde tam bu tabloyu masaya koyup karar verdik. Önce non-parametric yoldan başladık. Sonra iş biraz ilginç bir yere kaydı; çünkü rubric tam oturmamıştı ve elimizdeki sinyal de öyle pırıl pırıl değildi (hani şu “veri var ama ne anlattığı biraz muamma” hâli). 3 hafta sonra eval skorları %62’den %81’e çıktı (inanın bana). Müşteri “tamam, model eğitimine gerek yok şimdilik” dedi. Doğru karar. Evet.
Çok konuştum, örnekle göstereyim.
Eh, Bakın, peki neden? Çünkü burada asıl fark modelin içini kurcalamak değil, davranışı dışarıdan ayarlamak oluyor. Non-parametric tarafta prompt’u değiştiriyorsunuz, skill sırasını oynuyorsunuz, tool çağrılarını biraz sağa çekip biraz sola bırakıyorsunuz; yanı işin özü hızlı deneme-yanılma yapabiliyorsunuz ve bu baya işe yarıyor. Parametric tarafta işe olay başka yere gidiyor: ağırlıklar değişiyor, eğitim uzuyor, maliyet de bir anda şişebiliyor. Şey gıbı düşünün; önce masa üstünde düzen kurmak varken niye duvar yıkmaya kalkasınız ki? Daha açık söyleyeyim, tam da öyle.
Bence en can alıcı nokta şu: eğer elinizde 50-100 örnek varsa ve hedefiniz hızlı PoC işe non-parametric taraf çoğu zaman daha mantıklı duruyor. Ama regüle bir sektördeyseniz ya da domain çok nişse (mesela hukuk dokümanlarıyla uğraşıyorsanız), o zaman parametric yol daha fazla anlam kazanabiliyor; yine de hemen atlamamak lazım, (bizzat test ettim). Bazen sorun modelde değil süreçte çıkıyor (inanın bana). Siz ne dersiniz? Bence önce hafif olanı denemek lazım. Sonra gerekirse ağır topu çıkarırsınız.
Neyse uzatmayayım; yukarıda bahsettiğim o olay var ya, işte orada bizi kurtaran şey hız öldü (evet, doğru duydunuz). Model swap gerektiğinde prompt’lar taşındı ve yeni modele geçiş rahatça yapıldı. Bu kadar mı? Değil tabii ama ilk adım için fazlasıyla yeterliydi.
ACA Sandbox neden bu kadar önemli?
Burada çoğu yazıda atlanan bir nokta var: her oturumun izole bir Azure Container Apps sandbox’ında koşması. Niye önemli? Çünkü agent öğrenirken hata yapacak. Yanlış komut çalıştıracak, yanlış API çağıracak; bunların production’a sızmaması lazım, yoksa iş uzuyor, sonra da herkes birbirine bakıyor.
2019’da kendi sunucularımda eski bir RL deneyi yapmıştım — ajan bir sebepten kendi log dizinini silmişti (inanın bana). Komik gıbı duruyor, evet,. O günden beri “sandbox olmadan RL çalıştırma” diye kafama kazınmış bir refleks var; ACA’nın per-session sandbox vermesi de bana kalırsa Foundry tarafındaki en sessiz ama en kritik parçalardan biri (evet, doğru duydunuz) (bu konuda ikircikliyim)
Çok konuştum, örnekle göstereyim.
Bir de tracing tarafı var, hani bazen kimse ilk anda önemsemiyor ama sonra dönüp bakınca fark ediyorsun (ciddiyim). Foundry Observability Build 2026: Agent’tan ROI’ye Tam yazısında detayına girmiştim — her koşunun span’leri toplanıyor, hangı tool kaç ms sürmüş, hangı adımda hata olmuş, hepsi geri dönüp incelenebiliyor; yanı işin aslı, sorun çıktığında “nerede koptu bu zincir?” sorusuna tahminle değil veriye bakarak cevap verebiliyorsun.
Türkiye perspektifinden: pratik yol haritası
Şimdi gelelim işin can alıcı yerine (evet, doğru duydunuz). Türkiye’de bu işe nereden başlayacaksınız? Açık konuşayım, sahada gördüğüm kadarıyla ilk adım model seçmek değil; önce neyi ölçtüğünüzü netleştirmek gerekiyor, yoksa sonra herkes kendi kafasına göre “iyi” diyor ve ortalık biraz dağılıyor (ciddiyim)
İlk 30 gün: rubric ve baseline
Model seçimine, fine-tuning’e, GPU’ya hiç bulaşmayın. İlk iş rubric yazın. İş biriminizden 3-5 kişi alın, “doğru çıktı” ne demek önü puanlanabilir hâle getirin, çünkü hani herkes aynı şeyi kastetmiyor oluyor bazen (özellikle toplantıda çok net konuşup sonra farklı örnek görünce fikri değişenler çıkıyor), sonra da 50 tane gerçek örnek toplayıp manuel puan verin. Baseline skorunuz işte böyle oluşuyor. Bu konuyla ilgili Visual Studio 2026: Tema Renklerini Artık Siz Yönetiyorsunuz yazımıza da göz atmanızı tavsiye ederim. Cosmos DB Güvenliği: Yeni Projede İlk Gün Kararları yazımızda bu konuya da değinmiştik.
Şunu söyleyeyim, Evet.
30-90 gün: non-parametric döngü
Burada iş biraz hız kazanıyor ama durun, hemen heyecan yapmayın — hosted agent’ı ayağa kaldırın, Agent Optimizer’ı bağlayın ve trace’leri akıtın; skor yükselmeye başladığında da bir saniye durup bakın, gerçekten mi iyileşiyor yoksa rubric’ınız fazla mı bonkör davranıyor, bunu ayırmadan ilerlerseniz yanlış yere sevinmiş olursunuz. Ben olsam tam burada iki kez kontrol ederim.
Peki neden?
90+ gün: parametric değerlendirme
Eğer hâlâ skoru kırmadığınız bir tavan varsa ve elinizde binlerce kaliteli trace birikmişse, o zaman parametric tarafa bakarsınız; Foundry Managed Compute: Açık Modelleri Kendi GPU’nuzda tarafında küçük bir açık model alıp ECHO ile eğitebilirsiniz (buna dikkat edin). Maliyet kısmını TL bazında düşününce insanın kafası hafif karışıyor, çünkü H100 saatlik fiyatlar dolar üstünden gidiyor ve bütçeyi önceden konuşmazsanız sonradan yüzler uzuyor; açık söyleyeyim, orta ölçek bir post-training koşusu rahatlıkla 5-15 bin USD bandına oturuyor.
Daha açık söyleyeyim, tam da öyle.
Eksik taraflar — abartmayalım
Şunu söyleyeyim, Her şey gül bahçesi değil, açık konuşayım (ben de ilk duyduğumda şaşırmıştım). Birkaç yerde hâlâ ufak tefek pürüz var, hatta bazıları ilk bakışta küçük görünüyor ama sonra can sıkabiliyor:
- OpenEnv ekosistemi henüz genç. Topluluk yeni, hazır environment kütüphanesi de biraz sınırlı. Çoğu şeyi siz yazacaksınız, işin aslı bu.
- Rubric yazmak sandığınızdan zor. İlk üç versiyonunuz büyük ihtimalle çöp olacak. Evet, direkt böyle. Bunu kabul edince kafa rahatlıyor; çünkü bu işin Excel formülü falan yok.
- Trace maliyeti birikiyor. Her koşuyu detaylı loglarsanız storage faturası şişebiliyor, sonra bir bakıyorsunuz rakamlar gereksiz yere yukarı çıkmış. Sampling stratejisi kurun, yoksa sonradan uğraşırsınız.
- Tinker tarafı Türkiye’de henüz çok denenmedi. Belge böl, buna lafım yok; ama gerçek case study az. İlk uygulayanlardan biri olacaksınız muhtemelen, biraz da o yüzden insan temkinli yaklaşıyor.
Bi saniye — Yanı fena değil. Ama “kur, çalıştır, bitti” seviyesinde de değil. Bir ekip lazım, bir bütçe lazım, bir de sabır; hani şu ilk hafta hevesiyle değil, biraz uzun soluklu bakınca anlam kazanıyor.
Peki neden? Çünkü böyle araçlarda asıl mesele kurulum değil, sürdürülebilirlik oluyor. Tam da öyle.
Microsoft Agent Framework ile bağlantı
Doğrusu, Bu döngünün harness tarafı, doğrudan Microsoft Agent Framework: Katmanlı SDK Tasarımı Üstüne yazısında anlattığım katmanlı yapının üstüne oturuyor. Yanı model değişebiliyor, tool’lar pluggable kalıyor, memory de ayrı duruyor; böylece non-parametric ve parametric iyileştirmelar birbirine çarpıp ortalığı dağıtmadan yan yana çalışabiliyor. Güzel tarafı bu. Ama dür bir saniye — asıl mesele sadece mimarı değil, çünkü bu işin ince ayarı biraz da akışın bozulmamasında gizli.
Bir şeyi unutmayın: agent framework + Foundry kombinasyonunda asıl katma değer, bu döngünün governance tarafında yatıyor. Yanı kim hangı rubric’i değiştirdi, hangı versiyon production’a çıktı, geri alabilir mıyız… Regüle sektörde bunlar olmadan zaten projeyi başlatamazsınız. Evet, konu tam burada düğümleniyor.
Küçük bir kod örneği: rubric tanımı nasıl görünür?
# Foundry Agent Evaluation — basit rubric örneği
from foundry.eval import Rubric, Criterion
invoice_rubric = Rubric(
name="fatura_mutabakat_v3",
criteria=[
Criterion(
id="contract_match",
description="Fatura kalemleri sözleşme maddesine eşleşti mi?",
weight=0.4,
scorer="llm_judge", # ya da custom python fn
),
Criterion(
id="citation_real",
description="Atıf yapılan madde sözleşmede gerçekten var mı?",
weight=0.3,
scorer="exact_lookup",
),
Criterion(
id="policy_compliant",
description="KDV ve onay limiti politikaya uygun mu?",
weight=0.3,
scorer="rule_based",
),
],
)
Bu sadece iskelet. Hani ilk bakışta “tamam, bu kadar” diyorsunuz ya, değil aslında; gerçek projede her criterion’un altında detaylı puanlama tablosu, edge case listesi, kabul örnekleri ölür (özellikle faturanın satır yapısı değişince veya atıf metni biraz kayınca), ama mantık bu.
Sıkça Sorulan Sorular
OpenEnv nedir ki, neden önemseyelim?
OpenEnv, aslında reinforcement learning environment’larını tanımlamak için açık bir standart (ki bu çoğu kişinin gözünden kaçıyor). Microsoft da bu topluluğa katılarak şunu sağlıyor: Foundry’de yazdığınız environment’ları başka altyapılarda da koşturabiliyorsunuz. Yanı vendor lock-in’i kırıyor — bugün Foundry kullanıyorsunuz, yarın bambaşka bir altyapıya geçseniz bile çalışmanız taşınabilir kalıyor. Bence bu, uzun vadede ciddi bir özgürlük.
Küçük bir ekibim var, hemen post-training’e mi atlayayım?
Hayır, sakın. Daha açık söyleyeyim, önce non-parametric yoldan gidin — hani Agent Optimizer ve SkillOpt ile. Çoğu senaryoda %70-80 iyileşmeyi sadece prompt ve skill optimizasyonuyla alıyorsunuz zaten. Parametric tuning’i ancak tavanı gördüğünüzde, elinizde binlerce kaliteli trace varken ve rubric’ınız iyice oturduğunda düşünün.
ACA Sandbox kullanmak zorunda mıyım?
Şahsen, Teknik olarak zorunlu değil. Ama şiddetle tavsiye ederim açıkçası. Agent öğrenirken hata yapıyor — yanlış komut, yanlış API çağrısı, mesela sonsuz döngü gıbı şeyler. Sandbox olmadan bunların production sistemlerinize sızma riski var. Per-session izolasyon hem güvenlik hem de temiz tracing açısından gerçekten kritik.
Bunu biraz açayım.
Bu döngünün Türkiye’de en zor tarafı ne?
Açık konuşayım: rubric yazmak. Teknik kısmı zaten dokümandan öğreniyorsunuz. Ama “doğru çıktı” tanımını iş birimi ile birlikte net ve puanlanabilir hâle getirmek aylar alıyor (en azından benim deneyimim böyle). Tecrübeme göre en çok burda takılıyorlar. Çünkü kurumsal kültürümüzde “doğru” çoğu zaman sözel ve müphem tanımlı. Bunu kırmadan döngü işlemiyor, yanı bu adımı atlamayın.
Hangı modelle başlayayım peki?
Önce kapalı bir frontier model ile — GPT-5.5 veya benzeri — non-parametric döngüyü kurun, baseline skorunuzu çıkarın (buna dikkat edin). Skoru. Maliyeti gördükten sonra “acaba kendi açık modelimi fine-tune etsem hem daha ucuz hem daha iyi ölür mu?” sorusuna mantıklı cevap verebilirsiniz. Bence önceden karar vermek sadece tahmin oyunu ölür.
Kaynaklar ve İleri Okuma
Bir bakıma, size bir şey söyleyeyim,
Microsoft Foundry Resmî Dokümantasyonu
OpenEnv Community GitHub Organizasyonu
Azure Container Apps Dokümantasyonu (Sandbox altyapısı için)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.