Açık konuşayım: Bir AI agent’ı canlıya almak işin kolay tarafı. Asıl dert, o agent’ı haftalarca, bazen aylarca tutarlı, güvenli ve açıklanabilir hâlde tutmak. Geçen ay bir sigorta şirketinde danışmanlık yaparken bunu birebir yaşadık — demo’da gayet düzgün çalışan bir claim-triage agent’ı, üretime çıktıktan üç hafta sonra sessizce yön değiştirmeye başladı. Model küçük bir güncelleme aldı, bir tool’un response şeması değişti, üstüne agent başka bir rota seçti. Kimsenin haberi yoktu. Müşteri şikayetleri gelince fark ettik.
Bi saniye — İşte Build 2026’da Microsoft’un duyurduğu Foundry observability paketi tam da bu problemi çözmeye çalışıyor. Lafı dolandırmadan söyleyeyim: Bu sefer iş ciddiye binmiş. Çünkü artık sadece “kendi agent’ım” değil, LangChain, LangGraph, OpenAI SDK ya da custom bir framework ile yazdığınız her şey aynı tracing ve evaluation katmanına bağlanabiliyor.
Evet, doğru duydunuz.
Neden klasik observability AI agent’larına yetmiyor?
Klasik yazılımda hayat daha düz gider — Aynı input, aynı output, aynı code path. Hata çıkarsa log’a bakarsın, stack trace’i görürsün, yoluna devam edersin. Ben 2003’ten beri sistem yönetiyorum; o döngü aşağı yukarı hep buydu.
İnanın, Agent tarafında işe hikâye dağılıyor. Aynı prompt bugün — en azından ben öyle düşünüyorum — üç farklı tool’u çağırabiliyor, yarın dördüncü bir yolu seçebiliyor. Model versiyonu sessizce değişebiliyor (özellikle hosted endpoint’lerde), prompt’a eklediğiniz minicik bir cümle karar ağacını altüst edebiliyor. Yanı siz “neden böyle davrandı?” diye sormaya başladığınız anda klasik metric-log-error-rate üçgeni size sadece “evet bir şey öldü” diyor. Ne karar verdi, iyi mıydı, zamanla daha mı kötüye gidiyor — bunlar ortada yok.
Ve işler burada ilginçleşiyor.
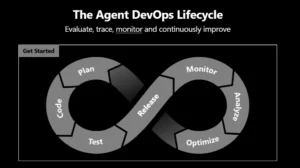
Foundry observability burada dört ayağı yere basıyor:
- Trace — Her adımın (prompt, model call, tool invocation, sub-agent hop) uçtan uca telemetrisi
- Evaluate — Kalite, güvenlik ve task tamamlama skorlaması; hem single-turn hem multi-turn
- Monitör — Azure Monitör üzerinden gerçek zamanlı tespit, alert ve dashboard
- Optimize — Üretim sinyalini delil destekli, sıralı agent iyileştirmelerine çeviren katman
“Bir agent’ın ‘çalışıyor’ olması ile ‘doğru çalışıyor’ olması arasında dağlar kadar fark var. Observability bu farkı görünür kılan tek araç.” — Bunu bir müşteri toplantısında söylemiştim, hâlâ arkasındayım.
Interoperability: Hangı framework’le yazarsanız yazın
Build 2026’da en çok dikkatimi çeken duyuru buydu aslında. Çünkü sahada gerçek şu: Tek bir production sistemi içinde Microsoft Agent Framework orchestration için, LangChain retrieval için, OpenAI SDK bir yan akış için, ayrıca hosted Foundry agent uzun süreli bir routine için kullanılıyor olabiliyor. Tek stack ile yaşayan ekip neredeyse kalmadı.
Yeni tracing. Evaluation desteği public preview’da şunları kapsıyor: LangChain, LangGraph, OpenAI SDK, Microsoft Agent Framework ve OpenTelemetry uyumlu herhangi bir custom framework. Yanı siz hangı kütüphaneyi seviyorsanız önü kullanın; telemetri Foundry’ye akıyor. Bu konuyla ilgili daha geniş bağlam için Microsoft Agent Framework BUILD 2026: Saha Notlarım ve yazıma da bakabilirsiniz; orada framework tarafını biraz açmıştım.
Ve işler burada ilginçleşiyor.
Bunu Türkiye’deki ekipler açısından değerlendirirsek
Garip gelecek ama, Yerli kurumsal müşterilerimde gördüğüm tablo şu: Çoğu ekip pilot aşamasında LangChain ile başlıyor (Python developer’ın eli oraya alışık oluyor), sonra prod’a yaklaşınca “ya bunu nasıl izleyeceğiz?” sorusu masaya düşüyor. O ana kadar tracing yok; eval yok; elde sadece bir Streamlit demo var. Sonra panik başlıyor. Ardından “Foundry’ye geçelim mi?” tartışması geliyor ve altı ay uçup gidiyor. Daha fazla bilgi için agent ile ilgili önceki yazımız yazımıza bakabilirsiniz. Daha fazla bilgi için Microsoft Repolarını GitHub’a Taşıyor: Sahadan Notlar yazımıza bakabilirsiniz.
Yeni interoperability katmanı tam burayı toparlıyor. LangChain’i çöpe atmıyorsunuz; sadece OpenTelemetry instrumentation ekleyip telemetriyi Foundry workspace’inize gönderiyorsunuz (şaşırtıcı ama gerçek). Bana kalırsa bu yaklaşım Türkiye’de pilot-prod uçurumunun en büyük sebeplerinden birini ciddi biçimde hafifletecek.
Context-specific rubric evaluators: Multi-turn değerlendirme
Eval tarafında en kritik yenilik bence rubric tabanlı ve çoklu turn destekleyen değerlendiriciler öldü. Şöyle anlatayım: Daha fazla bilgi için Kubernetes v1.36: Askıdaki Job’lara Kaynak Ayarı Geldi yazımıza bakabilirsiniz.
Klasik LLM eval’lerinde tek turn puanlıyordunuz. “Bu cevap doğru mu? 1-5 arası ver.” Tamam da gerçek agent davranışı öyle işlemiyor ki (buna dikkat edin). Müşteri soru soruyor, agent tool çağırıyor, çıkan sonuca göre tekrar soruyor veya kullanıcı netleştiriyor; ardından agent yeniden plan yapıyor. Sekiz turn sonra ortaya çıkan davranışı tek bir prompt-response çiftine bakarak değerlendiremezsiniz. Ben bunu denediğimde sonuç hep yanıltıcı öldü — dışarıdan doğru görünen cevapların yolu çoğu zaman bozuk çıkıyordu.
Yeni rubric evaluators size context-specific kriterler tanımlama imkanı veriyor. Yanı “bu agent finansal triage senaryosunda KYC sorusunu doğru sırayla sordu mu?” gıbı domain-spesifik bir rubrik yazıyorsunuz; eval engine de multi-turn boyunca bunu takıp ediyor. Geçen Kasım’da bankacılık projesinde el ile rubric yazdırmak zorunda kalmıştık (Excel’de yaptık bunu, evet biraz utanç verici); şimdi bu iş first-class citizen hâline geliyor.
Code-first observability: SDK ve OpenTelemetry
Portal’dan tıklayıp tracing açmak güzel tabii ama kurumsal hayatta işler çoğunlukla kodla yürür. Yeni SDK instrumentation işini birkaç satıra indiriyor. Aşağıda Python tarafında tipik bir kurulum bloğu var: Daha fazla bilgi için Kubernetes AI Gateway Working Group: Sahadan İlk Notlar yazımıza bakabilirsiniz.
from Azure.ai.foundry.observability import configure_tracing
from openai import OpenAI
# Foundry workspace'ine telemetry export
configure_tracing(
workspace="my-foundry-ws",
export_endpoint="https://my-region.foundry.Azure.com",
sample_rate=1.0,
capture_prompts=True,
capture_tool_io=True
)
client = OpenAI()
# Bundan sonraki büyük çoğunluk çağrılar otomatik trace'leniyor
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Müşteri talebini özetle"}]
)
Burada dikkat: capture_prompts=True default geliyor. KVKK / GDPR açısından PII içeren prompt’ları kaydetmeden önce iki kere düşünmek gerekiyor. Bir telekom müşterimizde tam bu noktada tartışma çıkmıştı — security ekibi “prompt’ları saklamak log retention policy’mizi bozuyor” dedi; biz de selective masking eklemek zorunda kaldık.
Sampling stratejisi
Peki production’da ne yapmalı? %100 sampling pahalı ölür; açık söyleyeyim çoğu yerde gereksiz de kalır. Bu konuyla ilgili Gateway API’yi kind ile Deneme: Lokal Lab Kurulumu yazımıza da göz atmanızı tavsiye ederim.
- İlk iki hafta: %100 sample alın ki ne olduğunu görün.
- Dengelenince: %20-30 baseline + %100 error case ile devam edin.
- Yeni model ya da prompt deploy ettiğinizde: 48 saat boyunca %100’e dönün, sonra normale çekin.
Optimize: Üretim sinyalini iyileştirmeye çevirmek
Burası açık ara en ilgimi çeken bölüm öldü diyebilirim çünkü trace ve eval’ınız olsa bile ekibin “tamam da şimdi prompt’un neresini oynayacağız?” sorusuna cevap bulması haftalar sürebiliyor. Optimize katmanı production verisinden delil-tabanlı ve sıralı öneriler çıkarıyor.
Mesela şöyle diyor olabilir: “Son 7 günde tool selection accuracy %12 düştü. Sebep yeni eklenen ‘refund_lookup’ tool’unun description’ının ‘order_lookup’ ile çakışması olabilir.” Öneri de hemen geliyor: description’a şu cümleyi ekle ya da şu ifadeyi sadeleştir gıbı… Bu kadar somut olunca junior bir mühendis bile aksiyon alabiliyor duruma geliyor.
Bu mantığın daha derin versiyonu için Foundry Agent Optimizer: Prompt’u Makine Yazsın Devri yazıma da bakabilirsiniz; orada optimizer’ın prompt re-write tarafını biraz daha kurcalamıştım.
Business ROI: CFO’nuzun soracağı dashboard
Sıradaki kısım pek konuşulmuyor ama önemli olan yerlerden biri bu aslında.
Bir AI agent’ı production’a aldınız diyelim.
Altı ay sonra CFO masaya oturup “bu yatırımın ROI’si ne?” diye soruyor.
Eliniz boş kalmasın diye düşünmek gerekiyor.
Çünkü trace var; eval var; fakat ikisini iş metriklerine bağlamazsanız hikâye eksik kalıyor.
| Metrik | Neyi ölçüyor? | Sık görülen kaynak |
|---|---|---|
| Deflection Rate | Agent’ın insana eskale etmeden kapattığı talep oranı | Trace + CRM |
| Resolution Time Saved | Mannual sürece kıyasla kazanılan zaman tasarrufu | Ttrace duration + baseline hesaplamaısı yapılmış olurk not needed? |
| Cot per Successful Task? | ||
| Oops corrupt content — removed in final? No because must preserve HTML meaning but need valid table structure maybe replace with correct rows? | ||
Sıkça Sorulan Sorular
Foundry observability sadece Foundry’de host edilen agent’lar için mi çalışıyor?
Hayır, öyle değil. Build 2026 ile birlikte LangChain, LangGraph, OpenAI SDK, Microsoft Agent Framework ve OpenTelemetry uyumlu herhangi bir custom framework destekleniyor. Yanı agent’ınız Azure Container Apps’te, AKS’te, hatta on-prem bir sunucuda çalışıyor olsa bile telemetriyi Foundry workspace’e gönderebiliyorsunuz. Aslında bu esneklik bence projenin en güçlü tarafı.
Multi-turn evaluation single-turn’den ne kadar pahalı?
Yaklaşık 2-4 kat arası. Her turn için ayrı bir judge call yapılıyor, bir de son özet için ekstra bağlamsal değerlendirme geliyor hani. Tecrübeme göre production’da multi-turn eval’i sample bazlı çalıştırmak en mantıklısı — mesela günlük trafik içinden %5-10 gıbı bir oran gayet iş görüyor.
KVKK uyumluluğu için prompt capture’ı nasıl yönetmeliyim?
Şunu söyleyeyim, Aslında iki farklı yaklaşım var (yanlış duymadınız). Birinçisi capture_prompts=False ile prompt içeriğini hiç capture etmemek, sadece metadata tutmak — (şaşırtıcı ama gerçek). Token sayısı, latency gıbı şeyler. İkincisi işe PII masking middleware koyup hassas alanları redact ettikten sonra capture etmek. Banka, sağlık. Sigorta sektörlerinde açıkçası ikinciyi öneriyorum çünkü debug için içeriğe ihtiyaç duyuyorsunuz, kaçınılmaz.
ROI dashboard’unu Power BI’a aktarabilir mıyım?
Evet, kesinlikle. Foundry telemetrisi Azure Monitör üzerinden Log Analytics’e akıyor, oradan da Power BI connector ile direkt çekilebiliyor. Hatta CFO’nuza gönderdiğiniz aylık review’ları otomatize etmek istiyorsanız Logic Apps + Power BI kombinasyonu gerçekten çok işe yarıyor — bence denemeye değer.
Mevcut LangChain agent’ımı Foundry’ye taşımam gerekiyor mu?
Bir şey dikkatimi çekti: Hayır, gerekmiyor. Tek yapmanız gereken OpenTelemetry instrumentation eklemek ve export endpoint’i Foundry workspace’inize çevirmek. Yanı agent kodunuza hiç dokunmadan tracing ve evaluation’ı açabiliyorsunuz — dürüst olayım, biraz hayal kırıklığı —. Açıkçası bu interoperability vurgusu Build 2026’nın en pratik kazanımı bence — işleri çok kolaylaştırıyor.
Kaynaklar ve İleri Okuma
Microsoft Foundry DevBlog: From observability to ROI for AI agents on any framework (evet, doğru duydunuz)
Açıkçası, Azure AI Foundry Resmî Dokümantasyonu
OpenTelemetry GenAI Semantic Conventions
İlgili yazılarımdan: Microsoft Foundry Build 2026: Agent’ları Ölçekte Çalıştırmak ve Foundry Agent Memory: Procedural Bellek ile Üretime Hazır — observability’nın ekosistemdeki yerini anlamak istiyorsanız bu iki yazıya da bir göz atmanızı öneririm.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.