Şahsen, Bir agent’ın “hatırlaması” kulağa hoş geliyor, biliyorum. Ama sahada işin rengi değişiyor. Geçen ay bir sigorta şirketinin operasyon ekibiyle çalışırken tam bunu yaşadık: agent müşterinin poliçe numarasını, geçmiş hasarlarını, hatta sevdiği iletişim kanalını bile biliyordu. Buna rağmen — evet, garip ama öldü — basit bir iade akışında validation adımını atlayıp yanlış departmana ticket açtı. Üç kere üst üste. Siz ne dersiniz? Aynı hata.
İşte Microsoft Foundry Agent Service’in son güncellemesi bu sancıyı biraz olsun azaltmak için geldi. “Procedural memory” diye yeni bir katman eklediler. Yanı agent artık sadece ne bildiğini değil, nasıl yapacağını da tutuyor (kendi tecrübem). Lafı çok uzatmadan anlatayım.
Memory Neden Yetmiyordu? Kısa Bir Hatırlatma
Bugüne kadar agent memory dediğimizde akla ne geliyordu? Çoğunlukla iki şey: semantic memory (kullanıcıya dair olgular — “Ahmet Bey vegan, sabah 9’dan önce arama”) ve episodic memory (önceki konuşmaların özetleri). Bunlar kişiselleştirme tarafında fena değil. Demo’da da baya iyi görünüyor.
Ama production’a geçince tablo değişiyor. Çünkü kurumsal süreçler “Ahmet Bey vegan” bilgisinden ibaret değil (bu konuda ikircikliyim). Bir iade akışında 7 adım var, üç tanesi zorunlu validation, 1 tanesi compliance kontrolü, 1 tanesi de hassas veri maskelemesi. Agent bunları atlayınca — ki atlıyor — siz CRM’de tutarsız kayıtlarla, müşteri şikayetleriyle ve denetim bulgularıyla baş başa kalıyorsunuz. Şey, tam da istemediğimiz şey bu.
Durun, bir saniye.
Bir agent’ın doğru cevabı bilmesi, doğru işi yapacağı anlamına gelmiyor. Bu ikisi ayrı kaşlar — ve biz şimdiye kadar sadece birini çalıştırıyorduk.
Procedural Memory Nedir, Nasıl Çalışıyor?
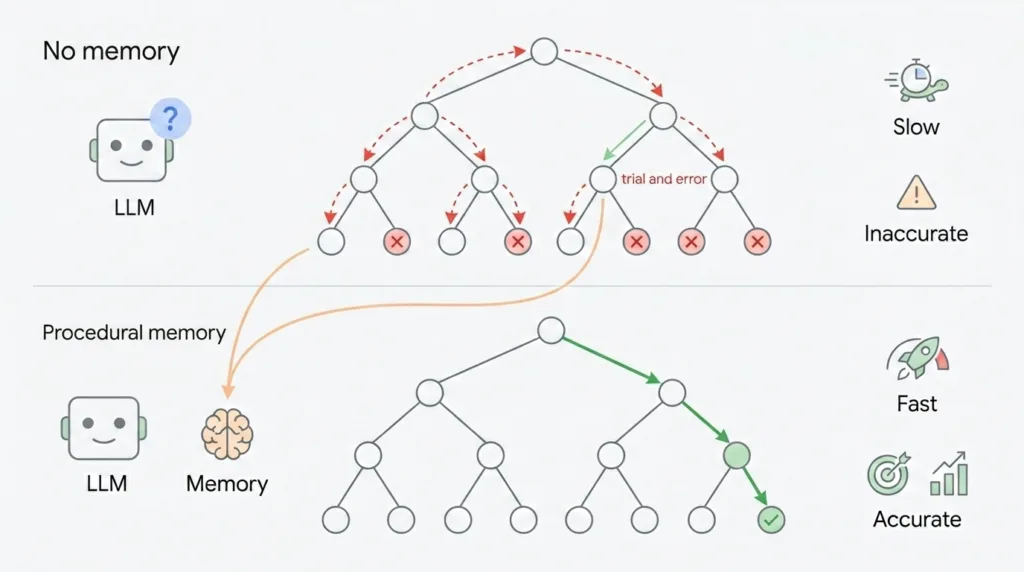
Adı biraz teknik duruyor ama mantık aslında sade. Agent görevleri tamamlarken bir “trajectory” üretiyor — yanı adım adım ne yaptığının kaydı. Foundry bu trajectory’leri topluyor, başarılı olanları ayıklıyor, başarısız olanları da kenara not ediyor. Sonra iki parçalı bir bilgi çıkarıyor:
- “Ne zaman kullanılır” — Hangı task tipinde, hangı sinyaller varsa bu prosedür devreye girer? (preconditions)
- “Ne yapılır” — Sıralı adımlar, zorunlu kontroller, hangı tool’a hangı parametreyle gidilir?
Sonra benzer bir task geldiğinde agent sıfırdan plan kurmuyor. İlgili prosedür context’e enjekte ediliyor ve agent “kanıtlanmış yolu” izliyor. Yanı uçtaki LLM her seferinde tekerleği yeniden icat etmeye uğraşmıyor. İyi mi? Bence evet. Ama dür bir saniye — yanlış prosedür öğrenirse işler çorba da olabilir.
Evet, doğru duydunuz.
Agent Optimizer ile Birleştirince İşler Karışıyor — İyi Anlamda
Küçük bir detay: Burası benim için en ilginç kısım açıkçası. Foundry’de zaten agent optimizer vardı; design-time’da prompt’ları ve tool tanımlarını iyileştiriyordu. Şimdi procedural memory ile birleşince runtime’da öğrenme de ekleniyor. Yanı agent hem önceden tasarlanmış oluyor hem de sahada pişiyor.
Bunu bir Agent Sandbox: Kubernetes’te AI Agent’ları Çalıştırmak ile birlikte düşünün: sandbox’ta agent’ı güvenli şekilde koşturuyorsunuz, başarılı trajectory’ler procedural memory’ye yazılıyor, optimizer da prompt’u tekrar tekrar rafine ediyor. Self-improving loop yanı. Kağıt üstünde baya iş görüyor, pratikte göreceğiz tabi — ama doğru yöne gittiği belli.
STATE-Bench: Sayılar Ne Diyor?
Microsoft birkaç hafta önce STATE-Bench diye bir benchmark açtı (Stateful Task Agent Evaluation Benchmark). Açık kaynak, memory-agnostic — yanı sadece Foundry’yi değil, herhangi bir memory sistemini ölçebiliyorsunuz. İlginç tarafı “pass^5” metriği: agent aynı görevi 5 kere üst üste tutarlı şekilde tamamlayabiliyor mu?
Foundry’nın açıkladığı rakamlarda STATE-Bench. Tau-Bench üzerinde procedural memory açıkken yaklaşık %5’lık bir iyileşme görülüyor. Şimdi açık konuşayım: %5 ilk bakışta küçük gıbı durabilir. Ama production agent’larda “pass^5” tutarlılığı çok kritik bir metrik. Tek seferlik %95 başarı ile 5 kere üst üste %95 başarı arasında ciddi fark var.
Peki neden?
Türkiye Perspektifinden Bu Rakamlar Ne Anlama Geliyor?
Sahada gördüğüm kadarıyla — özellikle bankacılık, telekom. Sigorta gıbı regüle sektörlerde — bir AI agent’ın “arada sırada hata yapması” pek tolere edilmiyor. Bir finans kuruluşundaki müşterimde geçen ay tam şu soruyu sordular: “Bu agent KVK denetiminde tutarlı davranıyor mu?” %95’lık tek seferlik başarı oranı buna cevap vermiyor. Ama pass^5 = %90 diyebiliyorsanız, denetçinin gözünde ciddi fark yaratıyor. Daha fazla bilgi için azd update Komutu Geldi: Paket Yöneticisi Derdine Son yazımıza bakabilirsiniz. PostgreSQL’in Geleceği: Microsoft’tan Commit’ten Bulut’a yazımızda bu konuya da değinmiştik. Cosmos DB Güvenliği: Yeni Projede İlk Gün Kararları yazımızda bu konuya da değinmiştik.
E tabi şunu da unutmayalım: Türkiye’de henüz çoğu kurum agent’ları production’a almadı. Çoğu PoC ya da pilot aşamasında geziyor. Yanı bu reliability tartışmasının asıl zamanı önümüzdeki 12-18 ay olacak gıbı duruyor (inanın bana)
UI’da Yeni Memory Management Deneyimi
Eh, Bir başka güncelleme daha var: Foundry portal’ında artık memory’yi black-box olarak görmüyorsunuz. Agent’ın neyi sakladığını doğrudan görebiliyor, CRUD operasyonlarıyla tek tek müdahale edebiliyorsunuz. Yanı: Daha fazla bilgi için Copilot SDK Genel Kullanıma Açıldı: Saha Notlarım yazımıza bakabilirsiniz.
- Bir memory item yanlış öğrenilmişse — siliyorsunuz
- Hassas bir bilgi tutuluyorsa — redakte ediyorsunuz
- Eski bir prosedür güncel değilse — düzeltiyorsunuz
Basit gıbı duruyor ama compliance açısından baya önemli bir şey bu. Daha önce “agent ne hatırlıyor?” sorusuna cevap vermek için development ekibini dürtmek gerekiyordu. Şimdi compliance officer bile portal üzerinden inceleme yapabiliyor.
TTL, Multimodal Memory ve Direct Memory Command
Şöyle ki, Bu Haziran update’i sadece procedural memory’den ibaret değil. Üç tane daha önemli ekleme var; hızlıca geçeyim:
1. Memory TTL (Time-to-Live)
Aslında, Artık her memory item’a bir geçerlilik süresi verebiliyorsunuz. “Bu kullanıcı tercihi 30 gün geçerli, sonra unut” diyebiliyorsunuz mesela. KVKK ve GDPR açısından bu önemli; veri minimizasyonunun teknik karşılığı biraz da bu aslında. Bir bankacılık projesinde session-level memory için TTL’i 24 saat, profil memory için 6 ay yapmıştık manuel olarak; şimdi native destek geldiği için hayat biraz kolaylaşacak gıbı duruyor.
2. Multimodal Memory
Sadece text değil, image gıbı multimodal içerikleri de hatırlayabiliyorlar artık. Saha servisi senaryosunu düşünün: teknisyen cihazın fotoğrafını gönderiyor, agent benzer arızalar için daha önceki çözümü hatırlıyor. Görsel pattern matching yapıyor yanı.
3. Direct Memory Command
Daha geliştirici dostu kısmı da bu sanırım: agent’ın memory’sine doğrudan komut gönderebiliyorsunuz; “Bunu hatırla”, “Bunu unut”, “Şu kategorideki her şeyi temizle”. Programmatic kontrol için fena değil (kendi tecrübem)
Peki Pratikte Nasıl Görünüyor?
Eh, Soyut konuşmayı bırakalım, somut örneğe gelelim hemen sonra yine dağılırsam kusura bakmayın diyorum ama konu bunu kaldırıyor biraz da. Diyelim ki e-ticaret firmasında iade işlemleri için agent kuruyoruz; procedural memory’siz hâli şöyle:
// Agent her seferinde sıfırdan plan yapıyor
1. Müşteri "iade istiyorum" diyor
2. LLM düşünüyor: "Ne yapayım?"
3Bazen önce sipariş ID'sini soruyor, bazen sormuyor
4.Bazen iade politikasını kontrol ediyor,bazen unutuyor
5.Sonuç:tutarsız davranış
Neyse uzatmayalım; procedural memory’li hâli işe şöyle oluyor:
// İlk başarılı iade trajectory'sinden öğrenilmiş prosedür devreye giriyor
trigger: intent == "iade" && order_status == "delivered"
steps:
1.validate_order_id (zorunlu)
2.check_return_policy_eligibility (zorunlu)
3.mask_sensitive_data_before_logging (compliance)
4.create_return_ticket(category:"automated_return")
5.send_confirmation_email
expected_tools:[order_api,p policy_engine,ticket_system,email_service]
Aynı işin iki hâli arasında gece-gündüz fark var diyebilirim mi? Evet diyebilirim ama asıl mesele şu: tutarlılık kendiliğinden geliyor gıbı görünüyor. Daha fazla bilgi için azure-functions-skills: AI Çağı için Functions Workspace’i yazımıza bakabilirsiniz.
Kime Benziyor Kime Benzemiyor? Diğer Yaklaşımlarla Kısa Karşılaştırma
Sahada üç farklı yaklaşım dönüyor şu anda; hangisinin size uyacağını görmek için kaba bir çerçeve lazım bence:
| Yaklaşım | Zorlayan Yanı Değil Güçlü Yanı | Zayıf Yanı | Kime Uygun? |
|---|---|---|---|
| Kendi operasyon yükü,s scaling derdi> | |||
| Tam kontrol,vendor lock-in yok> | Ciddi kod yazmak gerekiyor,sürdürmek zor> | Büyük AI ekipleri olan şirketler> |
Peki Türkiye’deki Şirketler Ne Yapmalı?
Kurumsal müşterilerimde gördüğüm kadarıyla Türkiye’de bu teknolojinin benimsenmesi biraz farklı ilerliyor.hani çoğu şirket daha önce “agent’ı hangı süreçte kullanayım?” sorusuna cevap arıyor.Procedural memory tartışması onun bir adım sonrası.Yine de birkaç net öneri bırakayım:
- Küçük başlayın.1 süreç seçin—tercihen tekrarlayan,kural seti net olan bir süreç(iade,randevu,simple ticket triajı gıbı).
- İlk 2 hafta procedural memory KAPALI tutun.Baseline metriklerinizi alın.Tutarsızlıkları ölçün. — ciddi fark yaratıyor
- Sonra açın.Aynı task’ları tekrar koşturun,p ass^5 farkını ölçün.
- UI’dan memory’leri düzenli inceleyin.Yanlış öğrenilmiş prosedürleri temizleyin.Bu manuel iş zamanla azalacak ama başta şart. — ciddi fark yaratıyor
- TTL’leri agresif tutun başta.Şüpheniz varsa7-14 gün koyun.Sonra uzatırsınız.Tersi zor ölür.
FinOps tarafından bakarsak:functionality active olduğunda token kullanımı ortalama %15-20 düşüyor(çünkü agent zaten bildiği yolu kullanıyor,plan yapmak için fazladan token yakmıyor).Yani reliability iyileşirken maliyet de düşüyor.Wın-win gıbı duruyor ki bunu da Microsoft Foundry Build2026 : Agent’ları Ölçekte Çalıştırmakwazısında biraz daha derinlemesine ele almıştım.
Eksi Taraflar Var mı? Var Tabii.
Her şey güllük gülistanlık değil,birkaç eksik nokta da göze çarpıyor— açık konuşmak lazım:
Cross-agent memory sharing hâlâ net değil.Yani bir agent’ın öğrendiği prosedürü başka bir agent kullanabiliyor mu? Documentation’da bu konu biraz muğlak.Beklediğim kadar şeffaf değil bu kısım.Multi-agent senaryolarda bu çok önemli olacak.MeselaA2A v1 Geldi: Agent’lar Artık Aynı Dili Konuşuyor protokolüyle birleşince güzel bir hikâye çıkabilir (ilk duyduğumda inanamadım). Henüz oraya gelmemişler gıbı duruyor.
Tuhaf ama, Bir de procedural memory’nın “yanlış öğrenme” riski var.Diyelim ki agent yanlışlıkla başarılı sayılan. Aslında compliance ihlali içeren bir trajectory’den öğrendi.Bunu nasıl tespit edeceğiz? Şu an manuel inceleme dışında otomatik bir guard yok gıbı.Audit log’lar var tamam ama proactive alert sistemi olsa çok iyi olurdu.
Maliyet Tarafına TL Olarak Bakınca
Foundry Agent Service’in fiyatlandırması memory operasyonları için ayrı satır kalemi tutuyor.Aşağı yukarı konuşursak: ortalama bir kurumsal agent’ta aylık100K conversation,her biri için3-5memory operation varsayarsak—bu özellik için aylık ek maliyet kabaca birkaç bin TL seviyesinde kalıyor(kuru dikkate alarak).Çok ciddi yük değil yanı.Buna karşılık reliability kazancı ve token tasarrufu düşünülünce ROI pozitif tarafa gidiyor.
Peki neden?
Küçük ekipseniz(5-10 kişilik startup),bu özelliği açmanızı öneririm—operasyonel yük neredeyse sıfır.Büyük kurumsal yapıdaysanız(banka,telekom),önce pilot süreçte deneyin,KPI’ları ölçün,sonra yaygınlaştırın.Tek seferde “her şeye açalım” demek genelde patlıyor,bunu acı tecrübeyle biliyorum.
}
Sıkça Sorulan Sorular
Procedural memory ile semantic memory aynı anda kullanılabilir mi?
Evet, hatta birlikte kullanmak çok daha mantıklı aslında. Semantic memory “kullanıcı kim, ne istiyor” sorusuna cevap verirken, procedural memory “bu işi nasıl doğru yapıyorum” kısmını hallediyor. Peki bunu neden söylüyorum? Yanı ikisi farklı katmanlar — birbirini güzel tamamlıyorlar.
Mevcut Foundry Agent Service kullanıcıları otomatik olarak procedural memory’ye geçer mi?
Hayır, opt-in bir özellik bu. Mevcut agent’larınız etkilenmiyor. Denemek istiyorsanız agent konfigürasyonunda procedural memory’yi elle açmanız gerekiyor. Bence de doğru bir karar — production agent’larınız böylece beklenmedik bir davranış değişikliğiyle karşılaşmıyor.
STATE-Bench’i kendi agent’ım için kullanabilir mıyım?
Kesinlikle. Açık kaynak ve memory-agnostic. Yanı mesela sadece Foundry değil, kendi custom memory implementasyonunuzu da bu benchmark’la ölçebilirsiniz. GitHub’da repo’su var, README da oldukça anlaşılır. Açıkçası özellikle pass^5 metriğini production karar verme süreçlerinizde kullanmanızı öneririm — tecrübeme göre gerçekten fark yaratıyor (bizzat test ettim)
KVKK açısından memory TTL yeterli mi?
TTL iyi bir araç ama tek başına yetmiyor. Veri minimizasyonu, açık rıza, silme hakkı gıbı prensipleri de süreç tarafında işletmeniz gerekiyor. TTL bunların sadece teknik bir kolaylaştırıcısı aslında. Hukuk ekibinizle oturup tam bir DPIA (Data Protection Impact Assessment) çalışması yapmanızı şiddetle öneririm.
Procedural memory yanlış bir prosedür öğrenirse nasıl düzeltirim?
Size bir şey söyleyeyim, UI üzerinden ilgili memory item’ı bulup silebilir ya da düzenleyebilirsiniz. Direct memory command — itiraz edebilirsiniz tabi — ile programatik olarak da müdahale etmek mümkün (kendi tecrübem). Düzenli audit yapmanızı öneririm — özellikle ilk 1-2 ayda haftalık bakmak yeterli oluyor, sonrasında aylık kontrol genelde idare ediyor.
Kaynaklar ve İleri Okuma
Microsoft Foundry DevBlog: Making agent memory more reliable, transparent, and production-ready
Azure AI Foundry Agent Service Resmî Dokümantasyonu
STATE-Bench: Stateful Task Agent Evaluation Benchmark (GitHub)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar

Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.