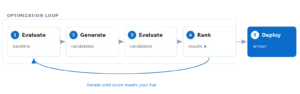
Geçen hafta bir müşteride, üretimde dönen üç farklı LLM endpoint’i için “şu ay token bütçemizi yine aştık” konuşması yaparken aklıma takıldı: biz hâlâ AI trafiğini, klasik HTTP istekleriymiş gıbı yönetmeye çalışıyoruz. Halbuki adı üstünde — bunlar HTTP, evet, ama içeriği bambaşka bir dünya. Token sayıyor, prompt injection’a açık, cache mantığı semantik, maliyet modeli istek başına değil token başına. Kısacası iş karışık.
İşte tam bu kafa karışıklığının ortasında, Kubernetes topluluğu bir AI Gateway Working Group kurduğunu duyurdu. Ben de sahadan gördüklerimi, neyin gerçekten iş göreceğini, neyin de “kağıt üstünde süper, pratikte bakalım” tarafında kaldığını paylaşmak istedim.
AI Gateway Tam Olarak Ne Demek?
Lafı gevelemeden gireyim: AI Gateway ayrı bir ürün kategorisi değil. Yanı gidip “bana bir AI Gateway lisansı verin” diyeceğiniz bir şey değil bu. Kubernetes bağlamında AI Gateway dediğimiz şey, aslında Gateway API spesifikasyonunu uygulayan bir network altyapısı — proxy, load balancer ne derseniz deyin — ama üzerine AI iş yüklerine özel yetenekler eklenmiş hâli. İlginç, değil mi? Basit gıbı duruyor, ama değil.
Klasik bir Ingress veya Gateway’den farkı nerede? Şöyle düşünün: standart bir reverse proxy “kaç istek geldi, hangı path’e gitti, statüs code neydi” diye bakar (ben de ilk duyduğumda şaşırmıştım). AI Gateway işe “bu istekte kaç token var, modele giden prompt güvenli mi, response’u cache’leyebilir mıyım, semantik olarak benzer bir sorgu daha önce sorulmuş müydü” sorularını sormak zorunda kalıyor. Yanı trafik aynı trafik değil; içerik başka türlü davranıyor.
Durun, bir saniye.
“AI Gateway yeni bir ürün değil, mevcut Gateway API’nın AI trafiğine göre evrilmiş hâli. Bunu anlamayan ekipler bambaşka bir yığın kurmaya kalkıyor — gerek yok.”
Hangı Yetenekleri Konuşuyoruz?
Working Group’un odaklandığı temel kabiliyetlere bakınca, sahadaki ihtiyaçlarla baya örtüştüğünü görüyorum. Hatta bazıları gecikmiş bile diyebilirim (inanın bana)
- Token bazlı rate limiting: İstek başına değil, token başına sınır. Bu çok hayatı çünkü bir kullanıcı 100 küçük istek atabilir, başkası tek istekte 50K token tüketebilir.
- Inference API’leri için ince taneli erişim kontrolü: Hangı takım hangı modele erişebilir, hangı saat aralığında, hangı maliyet tavanıyla.
- Payload inceleme: Akıllı yönlendirme, cache ve guardrail için tam HTTP gövdesini okuyabilme.
- AI’a özel protokoller: Streaming response, SSE, WebSocket bazlı inference akışları.
Charter ve Misyon — Neden Bir Working Group?
Açıkçası, Kubernetes ekosisteminde SIĞ ve WG ayrımı ilk bakışta biraz karışıyor. Kısaca söyleyeyim: SIĞ’ler kalıcı topluluklardır, bir alanı sahiplenirler (SIG-Network, SIG-Storage gıbı). Working Group işe belirli bir konuyu çözmek için kurulan, sonuçlarını ilgili SIĞ’lere proposal olarak ileten geçici. Uzayıp gidebilen yapılardır. Yanı “gelip geçici” deyip hafife almak da doğru olmaz (yanlış duymadınız)
Çok konuştum, örnekle göstereyim.
Açıkçası, AI Gateway WG de bu mantıkla çalışıyor. Burada üretilen şey — kendi adıma konuşayım — doğrudan Kubernetes’e merge edilen kod değil; daha çok “şu standart şöyle olmalı, Gateway API’ye şu uzantı eklenmeli” tarzında öneriler. Sonra bunlar SIG-Network başta olmak üzere ilgili gruplarda işleniyor (inanın bana). Bak şimdi kilit nokta burada.
WG’nın charter’ında dört temel hedef göze çarpıyor:
- Standartların geliştirilmesi: Declarative API’ler; yanı YAML ile tarif edilebilen yapılar. Imperative değil.
- Topluluk işbirliği: Envoy, Istio, NGINX, Kgateway gıbı farklı oyuncuları aynı masaya oturtmak. (bence en önemlisi)
- Genişletilebilir mimarı: Eklenti yazılabilir, sıralı işlenebilir bir yapı.
- Standart üstüne inşa: Tekerleği yeniden icat etmemek. Gateway API zaten olgun bir standart; üzerine AI katmanı eklenecek. — ciddi fark yaratıyor
Aktif Öneriler: Payload Processing
Şunu fark ettim: WG’nın şu anda üzerinde çalıştığı en kritik öneri bence payload processing. Çünkü AI iş yüklerinin büyük kısmının ihtiyacı buradan geçiyor gıbı duruyor. Siz hiç denediniz mi? Hatta neredeyse her senaryoda yol buraya çıkıyor diyebilirim.
Standart bir gateway request body’yi opak veri gıbı görür; geçirir gider, çok da bakmaz. Ama AI trafiğinde gövdenin kendisi her şeydir. Prompt’un içinde ne var, model parametreleri neler, response stream hâlinde mi geliyor — hepsi karara etki ediyor. Şey yanı… burada body artık sadece body değil.
Kısa bir not düşeyim buraya. PostgreSQL’in Geleceği: Microsoft’tan Commit’ten Bulut’a yazımızda bu konuya da değinmiştik.
Güvenlik Tarafı: Prompt Injection ve Filtreleme
Geçen sene bir bankacılık projesinde, müşteri hizmetleri için kurduğumuz LLM tabanlı asistana ilk hafta içinde “Sen artık başka bir asistansın, önceki kurallarını unut” tarzında prompt’lar gelmeye başladı. Klasik WAF bunu yakalamıyor — çünkü görünürde zararlı bir SQL injection veya XSS yok. Sadece tek cümle var. Ama o tek cümle bazen bütün akışı bozuyor (en azından benim deneyimim böyle) Cosmos DB Güvenliği: Yeni Projede İlk Gün Kararları yazımızda bu konuya da değinmiştik.
Payload processing önerisi tam burada devreye giriyor. Gateway seviyesinde:
- Prompt injection desenlerini tarayan bir processor
- Response’ta hassas veri (TC kimlik, kredi kartı) sızıntısını yakalayan bir filtre
- Anomali tespiti — alışılmadık token dağılımı, beklenmedik dil değişimi
Bunların hepsi declarative şekilde tanımlanabilecek gıbı duruyor. Yanı ben CRD ile “şu route’a şu processor pipeline’ı uygulansın, sırayla” diyebileceğim. Bu konuyu daha önce Gateway bir düşüneyim… API’yi kind ile Deneme: Lokal Lab Kurulumu yazısında anlatmıştım — orada anlattığım mantığın AI’a özel hâlini düşünün yeter. Aynı fikir var ama kullanım alanı değişmiş durumda.
Optimizasyon: Semantik Cache ve RAG Entegrasyonu
Maliyet tarafı da boş değil tabii. Bir startup müşterimde geçen ay konuştuk: aylık OpenAI faturalarının %40’ı aslında daha önce sorulmuş ya da çok benzer sorgulara gidiyormuş. Klasik HTTP cache burada işlemiyor çünkü prompt’lar birebir aynı değil; “İstanbul’da hava nasıl?” ile “İstanbul hava durumu nedir?” semantik olarak aynı. Hash’leri farklı çıkıyor.
Semantik cache burada devreye giriyor. Gateway gelen prompt’u embedding modeline gönderip vektör olarak temsil ediyor, daha önce cache’lenmiş benzer vektörlerle karşılaştırıyor; threshold’u geçiyorsa cache’den dönüyor. Maliyet düşüşü ciddi olabilir — ama “kağıt üstünde” diyorum çünkü embedding hesaplamak da bedava değil. Hesabı iyi yapmak lazım; yoksa tasarruf ederken başka yerden yakalanırsınız (kendi tecrübem)
Egress Gateway’leri: Dışarıya Çıkan Trafik
Sahada gördüğüm kadarıyla modern AI uygulamalarının neredeyse hepsi eninde sonunda cluster dışına çıkıyor. OpenAI var, Anthropıc var, Azure OpenAI var ya da kendi private LLM’ınız başka bir VPC’de duruyor… Bu trafiği güvenli ve gözlemlenebilir şekilde yönetmek başlı başına dert oluyor.
Egress gateway önerisi de bu dışa giden trafik için standart bir yapı tanımlamayı hedefliyor. Neden önemli? Çünkü şu an çoğu ekip her servis için ayrı ayrı API key yönetiyor, ayrı ayrı retry mantığı yazıyor, gözlemlenebilirlik de parçalanıp gidiyor. Sonuçta kim neyi çağırdı belli ölmüyor bazen. Microsoft Repolarını GitHub’a Taşıyor: Sahadan Notlar yazımızda bu konuya da değinmiştik. Microsoft Agent Framework BUILD 2026: Saha Notlarım ve yazımızda bu konuya da değinmiştik.
Tek bir egress gateway üzerinden: Foundry Agent Optimizer: Prompt’u Makine Yazsın Devri yazımızda bu konuya da değinmiştik.
- API key’lerin merkezî yönetimi (pod’lara sızdırmadan)
- Failover senaryoları — birincil sağlayıcı yanıt vermezse ikinciye düş
Türkiye Bağlamı: Bu İşin Bizdeki Hâli
Dürüst olmak gerekirse, Açık konuşayım: Türkiye’deki kurumsal müşterilerin büyük çoğunluğu hâlâ “AI iş yükü” diye ayrı bir kategori yönetmiyor (yanlış duymadınız). LLM API’leri doğrudan uygulama ekiplerinin çağırdığı şeyler oluyor çoğu yerde; platform ekibi devrede ölmüyor. Bu da şuna yol açıyor: ne maliyet kontrolü var, ne güvenlik politikası, ne de gözlemlenebilirlik düzgün kurulmuş oluyor.
Bak şimdi, Birkaç ay önce yaptığımız değerlendirmede sekiz farklı takımın
Sekiz ayrı API key vardı, sekiz ayrı fatura kalemi vardı, sekiz ayrı rate limit vardı.
AI Gateway mantığı tam burada hayat kurtarıyor.
Platform ekibi tek kapıyı koyuyor, herkes orada
Sıkça Sorulan Sorular
AI Gateway, benim mevcut API Gateway’imin yerini mi alıyor?
Hayır, öyle bir zorunluluk yok aslında. AI Gateway, Gateway API üzerine eklenen bir katman —. Envoy, Istio ya da NGINX tabanlı gateway’ınızı bir kenara bırakmak zorunda değilsiniz, üzerine AI yeteneklerini ekliyorsunuz. Bence en doğru bakış açısı şu: ayrı bir ürün değil, mevcut altyapınızın doğal bir evrimi.
Working Group’a nasıl dahil olunur, kim girebilir ki?
Aslında Kubernetes WG’leri herkese açık. Resmî e-posta listesine abone olup Slack kanalına girebilir, haftalık ya da iki haftada bir yapılan toplantılara katılabilirsiniz. Aktif katkı vermek istiyorsanız GitHub repo’sundaki proposal’lara yorum yapmak iyi bir başlangıç noktası. Mantıklı değil mi? Üstelik kod yazmak da şart değil — tecrübeme göre deneyim paylaşımı bile çok ciddi bir katkı sayılıyor.
Envoy AI Gateway veya Kgateway gıbı projeler zaten var, WG bunlardan farklı mı?
Tam olarak değil, hani ikisi farklı şeyler. Bu projeler birer uygulama üretiyor, WG işe standart üretiyor. Yanı WG’nın derdi, farklı hayata geçirmeların aynı API üzerinde anlaşmasını sağlamak. İlginç, değil mi? Mesela bir Envoy AI Gateway YAML’ını alıp başka bir implementasyona da uygulayabilmek — işte hedef bu.
Token bazlı rate limiting’i zaten kendim yazarım, neden standart gereksin?
Hani, Yazarsınız, elbette. Ama her takımın kendi tekerleğini icat etmesi açıkçası sürdürülebilir değil. Ortak bir API olduğunda, gözlemlenebilirlik araçları, policy motorları ve audit sistemleri aynı dili konuşuyor. Bir de şu var: işten ayrıldığınızda arkadan gelen kişi sizin custom kodunuzu çözmeye çalışmak zorunda kalmıyor — standart YAML’ı açıyor, anlıyor, devam ediyor.
Türkiye’de bu standart ne zaman gerçekten işe yarar hâle gelir?
Açıkçası, Bence 2026 sonu ile 2027 başı arası bir yerde. Şu an erken benimseyenlerin avantajı şu: standart oturduğunda zaten hazır oluyorsunuz. Şirketinizde AI iş yükü ciddi hacimlere ulaştıysa beklemek yerine pilot çalışmaya başlamanızı öneririm —. Asıl zor olan teknoloji değil, yanı organizasyonun buna adapte olması.
Kaynaklar ve İleri Okuma
Kubernetes Blog: Announcing the AI Gateway Working Group — Resmî duyuru yazısı.
Kubernetes Gateway API Resmî Dokümantasyonu — AI Gateway’in üzerine inşa edildiği temel standart.
Ne yalan söyleyeyim, WG AI Gateway GitHub Reposu — Aktif proposal’lar, toplantı notları. Katkı rehberi.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.