Kendi deneyimimden konuşuyorum, “En hızlı sıralama algoritması hangisi?” diye sorunca çoğu kişi ezbere QuickSort der. Açık konuşayım, ben de yıllarca o refleksle yaşadım. Sonra iş gerçek dünyaya geldi; veri tipi değişti, CPU değişti, cache davranışı değişti. O parlak cevap bir anda yamuldu. İşin aslı şu ki, sıralama dediğimiz şey tek bir yarış değil… daha çok pist, arazi ve hava durumuna göre araç seçmek gibi — yanlış araçla doğru pistte bile kaybedebilirsin.
Geçen ay masamda tam da bu konuyu kurcaladım. İstanbul’da bir editör toplantısından sonra eve dönüp kendi test makinemde küçük dizilerden devasa integer listelerine kadar denemeler yaptım. Intel i9 sınıfı bir işlemci üzerinde sonuçlara bakınca insanın kafasındaki “en iyi algoritma” fikri bayağı çatlıyor. Bir yerde Insertion Sort beklenmedik şekilde öne çıkıyor, başka bir yerde Radix Sort resmen uçuyor. QuickSort işe bazen kahraman, bazen de yavaş ama nazlı bir karakter gibi davranıyor — tam tahmin edilemez bir tıp.
Evet, doğru duydunuz.
Şunu fark ettim: Şimdi gelelim meselenin özüne. Hız sadece Big-O değil. Veri düzeni var, önbellek var, dal tahmini var, dilin kendi uygulaması var… yani olay biraz çorba. Karmaşık bir çorba. Ve evet, o çorbanın içinde tek başına kaşık yetmiyor (buna dikkat edin)
Neden tek cevap yok?
Sıralama algoritmalarını anlatırken genelde ders kitabı dili baskın çıkıyor: O(n log n), O(n²), stabil mi değil mi… Tamam da sahada işler öyle yürümüyor (ben de ilk duyduğumda şaşırmıştım). Hiç yürümüyor. Bir yazılım ekibinde küçük JSON dizilerini sıralıyorsanız başka konuşuruz; milyonlarca kayıtlık log akışını ele alıyorsanız bambaşka bir hikâye. Ben bunu ilk kez 2023’te bir SaaS projesinde fark ettim — veri seti büyüdükçe “teoride iyi” olan çözümün maliyeti beklenmedik biçimde şişmişti, kimse anlayamamıştı neye uğradığını.
Ve işler burada ilginçleşiyor.
İşin garibi, Burada asıl mesele şu: işlemci boş durmuyor, ama aynı zamanda her şeyi aynı hızda da yapmıyor. Cache’e yakın veri şak diye geliyor, uzak veri daha ağırdan. QuickSort’un bazı durumlarda parlaması tam da bundan; veriyi bölüp yönetmesi cache dostu olabiliyor. Ama kötü pivot seçerseniz? İşte o zaman işler tatsızlaşıyor. Gerçekten tatsız.
Bak şimdi, Bir de işin dil tarafı var. Python’da sort çağırdığınızda aslında “ben kendim çözerim” diyen zeki bir mekanizma devreye giriyor; arka planda TimSort çalışıyor. Özellikle kısmen sıralı veride fena iş çıkarmıyor. Yani siz basit bir satır yazıyorsunuz ama sahnede epey dolu dolu bir koreografi dönüyor — habersizce.
Evet, doğru duydunuz.
Küçük dizi mi büyük dizi mi?
Küçük dizilerde sürpriz kazanan
Bakın, kendi deneyimimden konuşuyorum, Küçük dizilerde Insertion Sort’un öne çıkması ilk bakışta tuhaf görünüyor. “O(n²) olan algoritma nasıl kazanır?” diye insan ister istemez kaşını kaldırıyor — haklı bir tepki. Ama küçük veri söz konusuysa kurulum maliyeti neredeyse yoktur; recursion yok, ekstra bellek yok, büyük plan yok, karmaşık yapı yok… direkt hallediyor işi, sade ve hızlıca (yanlış duymadınız)
İnanın, Editör masasında bu haberi ilk gördüğümde hemen kendi testlerimi açtım. Şubat 2025’te evdeki Linux sistemimde 1.000 eleman civarı dizilerle oynarken aynı tabloyu ben de gördüm: QuickSort teoride güçlü olsa bile hazırlık süresi yüzünden geride kalabiliyor. Az veri varsa sade yöntem bazen daha çevik oluyor. Nokta.
Orta ölçekli veride klasiklerin alanı
Orta boyutlu dizilerde QuickSort hâlâ çok sağlam duruyor. Mesela median-of-three gibi pivot seçimleri devreye girince kötü senaryoların önü biraz kesiliyor; in-place çalışması sayesinde bellek tüketimi düşük kalıyor ve cache’i de bayağı çökertmiyor — dengeli bir profil bu.
Ama gel gelelim burada da mutlak galip ilan etmek doğru değil. Veri neredeyse sıralıysa ya da tekrar eden değerler fazlaysa performans çizgisi kıvırmaya başlıyor. QuickSort’u Ferrari gibi düşünmek güzel; düz yolda nefis gidiyor, ama şehir içi dar sokakta bazen fazla gösterişli kalıyor. Biraz öyle bir karakter.
Büyük dizilerde bambaşka oyun
Vallahi, Büyük integer listelerinde Radix Sort’un öne çıkması beni açıkçası şaşırtmadı ama yine de etkiledi. Karşılaştırmalı sıralama yapmıyor; rakamları basamak basamak işliyor ve bu sayede devasa hacimde ciddi avantaj sağlıyor. En çok da 32-bit tamsayılar için birkaç geçişle işi bitirebilmesi gerçekten fena olmayan — teorik değil, gözle görülür bir fark bu. Bu konuyla ilgili Vercel Faturası Gelince: Startuplar Neyi Geç Fark Ediyor? yazımıza da göz atmanızı tavsiye ederim.
Bedeli yok mu? Var tabii. Her şeyden önce yalnızca belirli veri tiplerinde anlamlı oluyor; string ya da genel nesne sıralamasında aynı rahatlığı vermiyor. Bir de stabiliteyi düzgün kurmanız gerekiyor… aksi hâlde kâğıt üstündeki güzellik pratikte dağılabiliyor. Dağılıyor da.
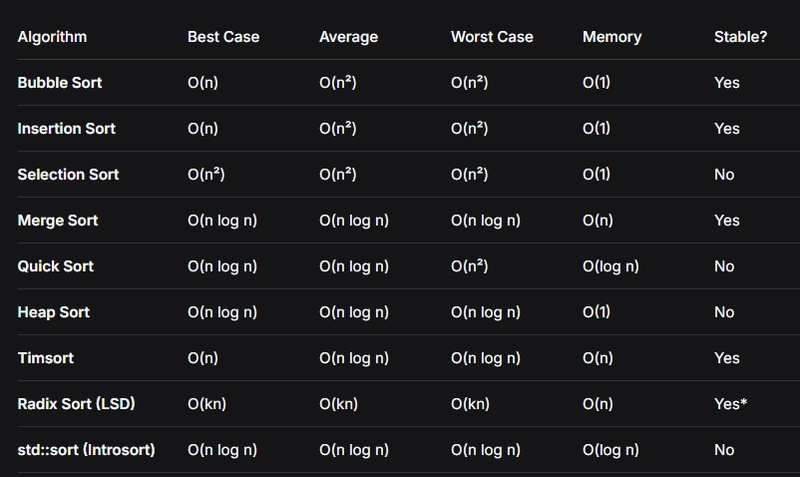
| Dizi Boyutu | Öne Çıkan Algoritma | Neden? |
|---|---|---|
| < 1.000 | Insertion Sort | Düşük overhead, az kurulum maliyeti |
| 1.000 — 100.000 | QuickSort / std::sort | Dengeli bölme ve iyi cache davranışı |
| > 1 milyon integer | Radix Sort | Karşılaştırmasız yapı ve sabit geçiş sayısı |
| Kısmen sıralı veri | TimSort | Melez yapı ve doğal koşullara uyum |
TimSort neden bu kadar seviliyor?
Pek çok kişi Python’un sort fonksiyonunu hafife alıyor çünkü dışarıdan bakınca tek satırlık sihir gibi duruyor: (yanlış duymadınız)
my_list.sort()Bi saniye — Ama işin altında TimSort var (bizzat test ettim). Bu algoritma kısmen sıralı veriyi görünce adeta göz kırpıyor — bir liste zaten yarı düzenliyse, o doğal blokları yakalayıp hızlıca toparlayabiliyor, fazla mesai yapmadan. Bu yüzden “Python yavaştır” cümlesi burada biraz eksik kalıyor; yavaş olan dil değil, bazen bizim kullandığımız yaklaşım oluyor. Fark önemli. Specification-First Agentic Development: AI ile Kod Yazmanın Daha Temiz Yolu yazımızda bu konuya da değinmiştik.
Bir arkadaşım Mart 2024’te Ankara’daki finans ekibinde buna benzer bir şey yaşamıştı. Gün sonu raporlarında gelen kayıtlar çoğunlukla kronolojik sıradaydı,. Klasik yaklaşımı bırakıp TimSort mantığına yaslanınca süreler bayağı düşmüş. Azıcık akıllıca seçilmiş algoritma, bayağı fark yaratıyor yani. Bazen inanılmaz basit.
Neyse, uzatmayalım: TimSort’un gücü teoriyle pratiğin ortasında durmasında yatıyor. Hem stabil, hem uyumlu, hem de gerçek hayattaki “neredeyse sıralı” veriye ters bakmıyor. Bana sorarsanız en sevdiğim tarafı tam da bu — süslü görünmeden iş yapması. Gösteriş yok, sonuç var. Bu konuyla ilgili 4 GB GPU’da Sesle Çalışan Yerel Yapay Zekâ: Sınırlar, Hileler, Gerçekler yazımıza da göz atmanızı tavsiye ederim. Yerel OSINT ajanı kurmak: Bulut yok, veri sızıntısı da yok yazımızda da bu konuya değinmiştik. Express.js Güvenlik Testinde Dört Araç Birbirini Nasıl Doğruladı? yazımızda da bu konuya değinmiştik.
Ha bu arada, TimSort her derde deva değil. Veri tamamen rastgele işe veya çok özel tiplerde çalışıyorsanız, Radix tarzı yöntemlerin yanina yaklaşamaz. Sadece şunu söylüyor: “Ben günlük hayatın adamıyım.” Ve bunu iyi yapıyor.
Düzgün benchmark nasıl yapılır?
Kötü benchmark kadar insan yaniltan başka şey azdır. Bunu geçen yıl Ekim ayında kendi laboratuvar ortamımda tekrar gördüm: testi ilk başta sıcak çalışan sistemde koşturunca sonuçlar saçmaladı. Gerçekten saçmaladı. Sonra biraz disiplin koyup warm-up yaptım, CPU affinity ayarladım, donanımı sabitledim. Ancak ondan sonra tablo anlam kazandı.
İşin püf noktası şu: listeleri tek tür üretmeyin. Random data tamam, ama nearly sorted ve reverse sorted senaryolarını atlamak büyük hata ölür. Mesela veritabanlarından çıkan kayıtların çoğu tamamen karma karışık değildir; bazen yüzde doksanbeşi dümdüz gider, sadece birkaç kayıt oynar. Bu detay yazılım dünyasında minik gibi görünür, ama performansı altüst eder — deneyimleyince anlıyorsunuz.
Bir de ölçüm aracınızı dikkatli seçmeniz lazım. CPU cycle, cache miss veya branch misprediction görmek istiyorsanız yalnızca duvar saati süresine bakmak yetmez. Biraz ham veriye inmeyi bilmek gerekiyor; aksi hâlde “bu hızlıymış” deyip geçersiniz, biraz sonra prod ortamda suratınıza tokat gibi döner. Döndüğünde de geç olmuş ölür.
Küçük startup ile enterprise tarafında ayrım burada iyice belirginleşiyor. Küçük ekipte belki tek kritik metrik toplam süre ölür; kendi işini görsün yeter. Daha büyük organizasyonda işe tutarlılık önemli hâle geliyor çünkü aynı kod farklı makinelerde farklı sürprizler çıkarabiliyor. Ciddi sürprizler.
En hızlı algoritma diye tek bir bayrak dikmek çoğu zaman yanlış oluyor; doğru soru şudur: Hangi veri tipi, hangi boyut ve hangi donanım üzerinde çalışıyorum?
Peki pratikte ne yapmalı?
- Küçük diziler için basitliği küçümsemeyin; insertion yaklaşımı çoğu zaman yeterli oluyor. — bunu es geçmeyin
- Tamsayı ağırlıklı dev setlerde Radix Sort’u mutlaka düşünün. — ciddi fark yaratıyor
- Kısmen sıralı verilere TimSort veya benzeri melez çözümler çok yakışıyor. — ciddi fark yaratıyor
- Kötü pivot ihtimali varsa QuickSort’u körlemesine kullanmayın.
- Sadece süreyi değil, cache miss ve branch tahmin hatalarını da izleyin.
Ekip seviyesine göre seçim yapmak
Küçük startup’ta hedef genelde hızla ürün çıkarmak oluyor, o yüzden bakım yükü düşük çözümler daha değerli olabiliyor. Kurumsal tarafta işe standartlaşma, sevk güvenliği ve ölçümlerin tekrarlanabilir olması öne çıkıyor. Yani aynı problem iki yerde iki farklı cevap doğuruyor — garip değil aslında, baya normal. Hatta beklenmeli.
Ben kendi projelerimde önce en sade çözümü tercih ediyorum. Sonra ölçüyorum. Eğer dar boğaz varsa optimize ediyorum (ciddiyim). Bu sırayı bozunca insan kendini erken optimizasyon bataklığında buluyor ki orası hiç keyifli değil — sorma gitsin.
Bir de dürüst olayım: bazen en iyi karar “algoritmayı değiştirmemek” oluyor. Verinin boyutu küçükse ya da kullanıcı deneyimine etkisi hissedilmiyorsa, mühendislik egosunu kenara bırakıp devam etmek daha akıllıca olabiliyor. Neredeyse her zaman değil ama çoğu zaman.
Sıkça Sorulan Sorular
En hızlı sıralama algoritması hangisi?<`final to=commentary code`
Kaynaklar ve İleri Okuma
.NET List<T>.Sort (sıralama davranışı)
.NET Array.Sort (uygulama detayları ve performans ipuçları)
CPython: list sort uygulaması (TimSort kaynak kodu)
TimSort nedir? (genel açıklama ve sezgisel örnekler)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.