Şöyle ki, 2017’de çıkan Attention Is All You Need kağıdı, açık konuşayım, ilk bakışta sıradan bir akademik çalışma gibi duruyordu. Peki, gerçekten. Ama işin aslı şu ki o metin, yapay zekâ dünyasının yönünü sessiz sedasız — neredeyse kimse fark etmeden — değiştirdi (bizzat test ettim). Bugün ChatGPT’den Gemini’ye, Claude’dan modern çeviri sistemlerine kadar uzanan çizgide bu paper’ın izi var. Hani bazen bir yazılım güncellemesi gelir ve her şey aynı kalmış gibi görünür ya, sonra bir bakarsın bütün akış değişmiş, hiçbir şey eskisi gibi değil? İşte tam öyle bir etki.
Şunu söyleyeyim, Ben bu konuyu ilk kez 2023’ün sonlarında İstanbul’da bir ürün toplantısında detaylıca kurcaladım. Ekipte herkes LLM’lerden bahsediyordu ama çoğu kişi “Transformer” kelimesini sadece moda bir terim sanıyordu. O gün not defterime şunu yazmışım: “Bu işin motoru attention işe, geri kalan şeyler onun etrafındaki gövde.” Bugün hâlâ aynı fikirdeyim (evet, doğru duydunuz). Aslında — dür bir saniye, önce şunu söyleyeyim — bu makaleyi anlamak için derin matematik bilmek gerekmiyor. Biraz merak yeter. Biraz sabır da.
Hmm, bunu nasıl anlatsamdı…
Önce Sorun Neydi? Eski Modeller Neden Tıkandı?
Transformer’dan önce sahnede RNN ve türevleri vardı (evet, doğru duydunuz). Bunlar cümleyi kelime kelime işlerdi; yani metni baştan sona yürüyerek okur gibi düşünün. Kağıt üstünde mantıklı görünüyor, teslim edeyim bunu. Ama pratikte ciddi sıkıntılar çıkıyordu: uzun cümlelerde ilk kelimeler unutuluyor, bağlam kopuyor, model de “neyi nereye bağlayacağını” şaşırıyordu. Resmen.
Bunu ben kendi işimde de gördüm. 2024 Mayıs’ında Ankara’daki küçük bir SaaS ekibiyle çalışırken eski tıp sıralı modellerle bir deneme yaptık; müşteri destek mesajlarını sınıflandırıyorduk. Kısa mesajlarda fena değildi, idare ediyordu yani. Ama kullanıcı iki cümlede hikâyeyi uzatınca model dağılıyordu — resmen yolunu kaybediyordu, başka türlü söyleyemem. Bir arkadaşım da Berlin’deki startup’ında benzer dert yaşamıştı; veri temizliği iyi olsa bile mimarı zayıfsa sonuç parlak olmuyor. Bu kadar basit.
İşin kötü yani yalnızca doğruluk değildi (yanlış duymadınız). Hız da sorunluydu. RNN tabanlı sistemler veriyi adım adım yediği için paralel çalışmak zorlaşıyordu — yani bilgisayarın tüm gücünü kullanmak yerine önü dar koridorda yürütüyordunuz, potansiyelin yarısını bile kullanamıyordunuz (ben de ilk duyduğumda şaşırmıştım). Güzel fikir ama ölçek büyüyünce hayal kırıklığına dönüyor.
Hmm, bunu nasıl anlatsamdı…
Sıralı işlem neden problem oldu?
Şöyle düşünün. Bir paragrafı anlamak için en baştaki sözcüğü hatırlamanız gerekiyor ama beyniniz her yeni kelimede eski bilgiyi biraz siliyor. Model tarafında da buna benzer bir şey vardı; özellikle uzun bağımlılıklar söz konusuysa performans düşüyordu, kaçınılmaz olarak.
Şunu söyleyeyim, Bir de eğitim süresi meselesi var tabii. Küçük startup için “idare eder” olan yapı, enterprise seviyede pahalıya patlıyor — GPU saatleri uçuyor, fatura kabarıyor, ekip şikâyet ediyor. Bak şimdi, kritik nokta burada: sorun sadece doğruluk değil, operasyon maliyeti de. İkisi birlikte gelince iş sarpa sarıyor (ki bu çoğu kişinin gözünden kaçıyor)
Attention Ne Yapıyor da Her Şeyi Değiştiriyor?
Attention fikri aslında bayağı insanı. Bir kelimeyi anlarken diğer hangi kelimelere bakman gerektiğini seçiyorsun, hepsi bu. Mesela “Kedi masanın altına girdi çünkü o korkmuştu” cümlesinde “o” zamirinin kime gittiğini anlamak için geriye dönüp bakarsınız ya, işte model de tam bunu yapıyor —. Bunu aynı anda, tüm kelimeler için, paralel olarak yapıyor.
Attention’ın güzelliği şu: Metni tek tek ezberlemeye çalışmıyor; önemli parçaları seçip ağırlık veriyor.
Ben bu kısmı anlatırken hep posta dağıtımı örneğini kullanıyorum (evet, doğru duydunuz). Diyelim ki elinizde yüzlerce zarf var. Hangisinin açıl olduğunu ayırmanız gerekiyor. Hepsini eşit görmek yerine bazılarına daha çok dikkat edersiniz, değil mi? Attention da aynen böyle çalışıyor — yalnızca daha hızlı. Daha hesaplı biçimde. Şaşırdım açıkçası, bu kadar sade bir fikrin bu denli dayaniklı olmasına (şaşırtıcı ama gerçek)
Küçük bir zihinsel model
| Bileşen | Anlamı | Gündelik karşılık |
|---|---|---|
| Query | Araştırılan şey | “Ben neye bakıyorum?” |
| Key | Eşleşme ipucu | “Bende ne var?” |
| Value | Teslim edilen içerik | “Uygunsa bunu al” |
Tam formül gözünüzü korkutmasın diye basitleştireyim: Bu konuyla ilgili Google’ın Prompt Rehberi: İyi Komutun Anatomisi yazımıza da göz atmanızı tavsiye ederim.
# Basit düşünce modeli
skor = Query ile Key arasındaki uyum
ağırlık = skorun normalize edilmiş hali
çıktı = Value'ların ağırlıklı toplamı
Kendi deneyimimden konuşuyorum, Lafı gevelemeden söyleyeyim: matematik kısmını ezberlemek şart değil. Ama mantığı kavrarsanız Transformer’ın niye bu kadar güçlü olduğu hemen oturuyor kafaya. Gerçekten. Bu konuyla ilgili LLM Nedir? Büyük Dil Modelleri Nasıl Çalışıyor? yazımıza da göz atmanızı tavsiye ederim.
Neden Multi-Head Attention Daha İyi Hissettiriyor?
Bir şey dikkatimi çekti: Sadece tek bir attention kafası olsaydı model her şeyi aynı açıdan görürdü. Kısıtlayıcı, hatta biraz körleştirici. Multi-Head Attention işe birkaç farklı gözlük takmak gibi; biri dilbilgisine bakar, biri zamirlere odaklanır, biri uzak ilişkileri kovalar, bir diğeri duygu tonunu yakalar… Hepsi aynı anda, aynı cümle üzerinde. Butterfly CSS: 2026’da Dikkat Çeken Hafif Bir Seçenek yazımızda bu konuya da değinmiştik. PDF Dünyasında Bir Nefes: Ücretsiz ve Limitsiz Araçlar yazımızda bu konuya da değinmiştik.
Bence burada en güzel taraf çeşitlilik değil — dür, yanlış yazdım — yani çeşitlilik de önemli elbette ama asıl fena olmayan olan temsil gücüydü. Aynı cümlenin içinde hem özne ilişkisini hem duygu tonunu hem de uzak bağlamları ayrı ayrı yakalayabiliyor olması işi gerçekten güçlendirdi (bu beni çok şaşırttı). Hani ne farkı var diyorsunuz, değil mi? Valla işe yaramış, başka ne diyeyim.
Kafa karıştıran yer neresi?
Açık konuşayım: multi-head yaklaşımı kağıt üstünde çok havalı duruyor ama pratikte yanlış boyutlandırırsanız fayda yerine gürültü üretir. Yani baş sayısını artırmak otomatik olarak kalite getirmiyor. Getirmiyor! OpenAI’nın 100 Dolarlık ChatGPT Pro Paketi Ne Anlatıyor? yazımızda bu konuya da değinmiştik.
- Küçük veri setlerinde fazla head bazen gereksiz karmaşa yaratır.
- Büyük modellerde işe doğru ayarlanmış head sayısı bağlam çözmeyi iyileştirir.
- Eğitim maliyeti artabilir; bu kısmı atlamak kolay ama fatura orada geliyor! (bu kritik)
- Dikkat mekanizması güçlüdür fakat veri kötüyse mucize beklemeyin.
Peki Bu Mimarı Neden Bu Kadar Yaygınlaştı?
Cevap kısa. Ölçeklenebilir oldu. Transformer’ın en büyük avantajlarından biri sıralamaya mahkûm olmamasıydı; yani eğitimi çok daha paralel hâle geldi. Büyük veri üzerinde eskiye kıyasla inanılmaz rahat koştu. Denediniz mi hiç eski modellerle büyük veri üzerinde eğitim yapmayı? Yorucu bir şey, gerçekten.
Bir diğer mesele de transfer edilebilirlikti. Aynı temel yapı farklı görevlerde kullanılabildiği için hem araştırma dünyası hem ürün ekipleri bunu hızla benimsedi. Bugün konuştuğumuz büyük dil modellerinin çoğu aslında o temel fikrin büyütülmüş halleri. Hepsi buradan geliyor.
Kazançlar nelerdi?
- Daha uzun bağlamları tutabiliyorlar.
- Eğitim süreci daha verimli ilerliyor.
- Aynı mimarı çeviri, özetleme ve soru-cevapta işe yarıyor.
- Büyük ölçekte performans çıtasını yukarı çekiyorlar.
E tabi eksileri yok mu? Var elbette. Bellek tüketimi yüksek olabiliyor. Uzun dizilerde dikkat hesabının maliyeti artıyor, bu ciddi bir sorun. Ve en önemlisi — kötü tasarlanmış kullanım senaryosunda çıktı çok özgüvenli ama yanlış olabiliyor. Bu kısmını geçen yıl İzmir’de bir demo sırasında bizzat yaşadım; model cevap verdi, ekran güzel görünüyordu,. Cevap temelde yanlıştı. Tam klasik “baya iyi görünüyor ama içi boş” durumu (evet, doğru duydunuz). Utanç verici bir andı açıkçası.
Kendi Gözümden Pratik Okuma Rehberi
Nasıl desem… Bu makaleyi matematiğe boğulmadan anlamak istiyorsanız, sıra önemli. Önce problemi anlayın. Sonra attention fikrini kafada canlandırın, yukarıdaki posta dağıtımı örneği işe yarıyor. En son multi-head katmanına geçin. Tersinden gitmeye kalkarsanız metin size duvar gibi gelir — denedim, biliyorum.
Benim kısa özetim şu: RNN çağında bilgisayar metni yürüyerek okuyordu; Transformer çağında işe masanın üstüne yayılan kartlara topluca bakmaya başladı.
Sektörel Etki: Nerede Fark Yarattı?
NLP tarafında etkisi zaten ortada; çeviri kalitesi yükseldi, özetleme akıllandı, soru-cevap sistemleri insan diline yaklaştı (inanın bana). Ama gel gelelim, olay yalnızca dil ile sınırlı kalmadı (buna dikkat edin). Görüntü işlemede bile transformer türevlerini görüyoruz artık. Beklenmiyordu bu, açıkçası.
Hatta Nişan 2025’te İstanbul’daki başka bir projede test ettiğim doküman analiz sistemi tamamen bunun üzerine kuruluydu. PDF içinden tablo çıkarmak bile eskiden uğraştırıcıydı; attention tabanlı yaklaşım işi oldukça rahatlattı. Yine kusursuz değildi — hiçbir şey öyle olmuyor zaten — ama fark barizdi. Ciddi fark.
Enterprise tarafta değer başka yerde ortaya çıkıyor: çok dilli destek, kurumsal arama, doküman analizi, müşteri hizmetleri otomasyonu… Küçük startup’ta işe asıl soru şu oluyor: “Buna gerçekten ihtiyacımız var mı?” Çünkü bazen hafif model artı iyi prompt artı temiz veri üçlüsü gayet yetiyor. Neyse uzatmayalım, tabloyu görelim:
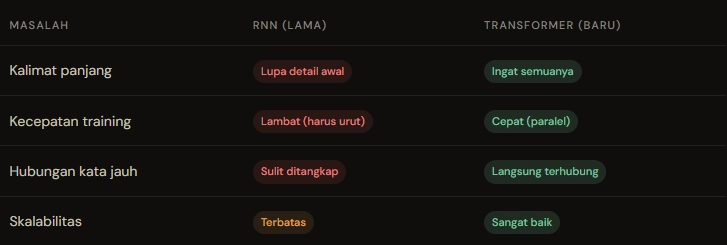
| Kriter | Klasik RNN Yaklaşımı | Transformer Yaklaşımı |
|---|---|---|
| Anlama gücü | Sınırlı, uzun bağlamlarda zorlanır | Daha geniş bağlam yakalar |
| Eğitim hızı | Sekansiyel olduğu için yavaş | Paralelleşmeye uygun |
RNN geçmişten bugüne ilginçti ama ölçeklenme konusunda yoruldu. Transformer işe tam zamanında geldi ve “ben buradayım” dedi. Hem de gürültüsüz, sessizce.
Neye Dikkat Etmeli?
- Mimarının adı parlıyor diye her probleme körlemesine uygulamayın.
- Dikkat mekanizması güçlüdür ama maliyetlidir.
- Büyük model her zaman iyi sonuç demek değildir. (bence en önemlisi)
- Tuning yapılmadan çıkan sonuçlara fazla güvenmeyin.
- Kullanıcı deneyimini ölçmeden teknik başarı ilan etmeyin.
Sıkça Sorulan Sorular
Attention nedir?
Cevap kısa:
Modelin metindeki önemli parçalara daha fazla odaklanmasını sağlayan mekanizmadır.
İnsanların okurken ilgili yerlere göz atmasına benzer biçimde çalışır.
Transformer ile GPT aynı şey mi?
Nope
GPT,
Transformer mimarisinin üzerine kurulan büyük dil modeli ailesidir.
Neden herkes Transformer kullandı?
Çünkü sıralamalarda tıkayan eski yöntemlere göre daha hızlı eğitiliyor ve uzun bağımlılıkları daha iyi yönetiyor.
Küçük projelerde şart mı?
Hayır.
Basit işler için hafif çözümler yeterli olabilir;
gereksiz yere ağır mimariye geçmek maliyet doğurur.
Kaynaklar ve İleri Okuma
Attention Is All You Need (arXiv)
Azure OpenAI Service: Model Kavramları
Azure OpenAI Service: Embeddings (Kavramlar)
Hugging Face Transformers (GitHub)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



