Şunu fark ettim: Bakın şimdi, açık konuşayım: Multi-cluster Kubernetes tarafında yıllardır aynı filmi farklı müşterilerde izliyoruz. Adamlar geliyor, “Aşkın, üç region’da AKS cluster’ımız var, birinden diğerine servis çağırmak için VPN, gateway, DNS, service mesh… bu kadar parça olmasın artık” diyor. Hak veriyorum tabi. Çünkü işin aslı, iki cluster’ı birbirine düzgünce konuşturmak bazen beklediğinizden daha yorucu oluyor.
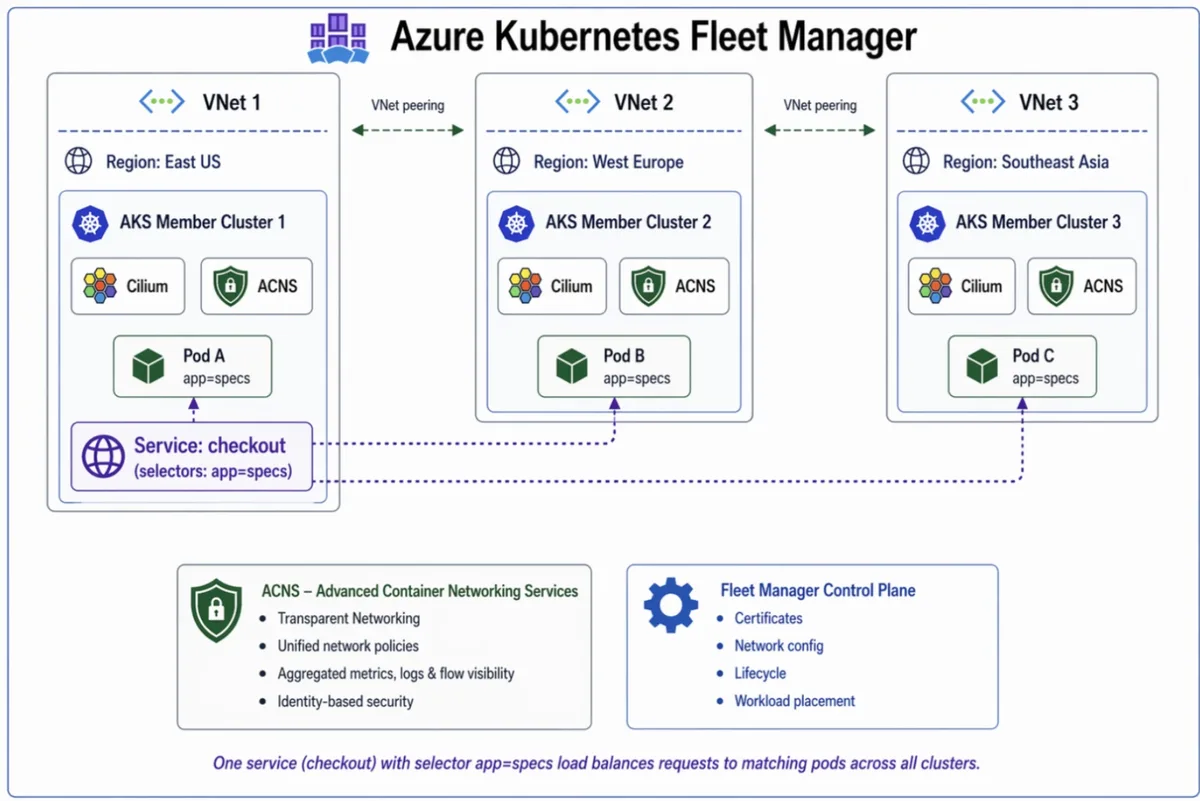
Geçen hafta Microsoft, Azure Kubernetes Fleet Manager için cross-cluster networking özelliğini public preview olarak duyurdu. Cilium tabanlı, Kubefleet ile orkestre edilen, fleet seviyesinde bir doğu-batı (E-W) ağ katmanı. Yani cluster’lar arası servis çağrıları artık local’miş gibi davranacak. Kulağa fena değil. Peki sahada gerçekten iş görüyor mu? Birkaç gündür kafamda evirip çevirdim, deneme ortamında ufak bir POC kurdum ve açıkçası bazı yerlerde şaşırdım. Bulduklarımı paylaşayım.
Önce Sorunu Doğru Koyalım: Multi-Cluster Neden Bu Kadar Zor?
Bir şey itiraf edeyim. 2021’de bir bankacılık projesinde, dört ayrı AKS cluster’ı arasında servis discovery işini çözmek için resmen üç ay gömdük. Üç ay! İki kişi full time uğraştık, yani öyle kenardan bakıp “ölür ya” denecek bir mesele değildi; her cluster’ın kendi CoreDNS’i vardı, service CIDR ayrıydı, üstüne Application Gateway’ler ve Private Link’ler de eklenince iş iyice dallanıp budaklandı.
Evet, doğru duydunuz.
Sonunda çalıştı mı? Çalıştı. Ama bakım tarafı baya sıkıntılı hâle geldi. Bir IP değişse, üç ekip aynı anda ayağa kalkıyor, neyin nereye bağlandığını yeniden kontrol ediyorduk. Evet. İşte asıl dert de buydu.
İşin aslı şu: geleneksel multi-cluster yaklaşımı beraberinde bir “networking tax” getiriyor, yani ağ vergisi diyebiliriz buna; Microsoft’un bloğunda da bu ifade geçiyor ve açık konuşayım, tam oturuyor. Çünkü bir yandan VPN ya da ExpressRoute peering kuruyorsun (latency artıyor, maliyet kabarıyor), diğer yandan service discovery için ya Istio gibi bir mesh’e yaslanıyorsun ya da custom bir çözüm yazmaya başlıyorsun.
- VPN ya da ExpressRoute peering kurman gerekiyor (latency + maliyet) — ciddi fark yaratıyor
- Service discovery için ya bir mesh (Istio, Linkerd) ya da custom çözüm yazıyorsun
- Cluster CIDR çakışmalarıyla uğraşıyorsun
- mTLS, kimlik, policy… her cluster için ayrı ayrı kurguluyorsun — ciddi fark yaratıyor
- Bir cluster’ı upgrade ederken diğerinin trafiğini elle yönlendiriyorsun — bunu es geçmeyin
Bunlar küçük ekipleri zaten yoruyor. Büyük tarafta işe iş biraz daha karışıyor; özellikle finans, telekom. Sağlık gibi regülasyona takılan alanlarda insanlar bilinçli olarak çoklu cluster mimarisine gidiyor ki blast radius küçük kalsın, ama sonra o rahatlık başka yerden geri dönüp operasyonu zorluyor. Hani güvenlik kazanıyorsun ama bedelini gece yarısı alarmıyla ödüyorsun gibi.
Çok konuştum, örnekle göstereyim.
Klasik trade-off bu. Peki neden hep böyle olmak zorunda?
Doğrusu, Neyse uzatmayalım, tam burada Azure Container Networking Interface Multicluster devreye giriyor ve hikâye biraz değişmeye başlıyor.
Fleet Manager’ın Yeni Numarası: Cilium + Kubefleet
Şimdi asıl yere gelelim. Fleet Manager bir süredir workload propagation işini zaten yapıyordu; — dürüst olayım, biraz hayal kırıklığı —. Bir Deployment’ı alıp 10 cluster’a aynı anda yayabiliyordunuz, üstüne staged upgrade tarafında da idare eder bir orchestration veriyordu. Ben birkaç müşteride denedim, açık konuşayım, kötü değildi. Ama networking kısmı biraz boş kalıyordu, işte o boşluğu şimdi kapatıyorlar.
Şunu söyleyeyim, Mimariyi kabaca böyle okuyabilirsiniz: Cilium dataplane tarafını üstleniyor (eBPF tabanlı, kernel seviyesinde çalışıyor,. Işi aşağıda çözüyor), Kubefleet işe fleet seviyesindeki orkestrasyonu yönetiyor. İkisi de CNCF projesi; bu detay küçük gibi duruyor ama değil. Çünkü vendor lock-in’den kaçmak isteyen müşteriye ilk sorduğum şey genelde şu oluyor: “Alttaki teknoloji kapalı mı?” Burada cevap net, hayır.
Cross-cluster networking’in en rahat tarafı şu: Geliştirici hiçbir şeyi kurcalamıyor. Servisini Service olarak yazıyor, ClusterIP ile çağırıyor. O servis hangi cluster’da koşuyor, hangi region’da duruyor, bunları tek tek düşünmüyor. Platform ekibi açısından işe kontrol tek yerde toplanıyor.
Peki “Local’miş Gibi” Ne Demek?
Bak şimdi, teknik kısım aslında şöyle ilerliyor: Cilium cluster mesh modunda çalışırken her cluster’ın endpoint bilgisini diğer cluster’lardaki Cilium agent’larına yayıyor. Yani my-service.production.svc.cluster.local dediğiniz anda Cilium sadece — ki bu tartışılır — bu cluster’a bakmıyor; fleet içindeki diğer cluster’larda o servisin nerede yaşadığını da görüyor ve trafiği ona göre yönlendiriyor. Load balancing var, failover var, locality-aware routing var — yani önce kendi region’undakine bakıyor, yoksa diğerine kayıyor.
Bu arada bu yaklaşım servis mesh’lerden biraz farklı yerde duruyor (ki bu çoğu kişinin gözünden kaçıyor). Mesh tarafı L7’de çalışıyor, sidecar inject ediyor, hâliyle biraz daha ağır geliyor; Cilium’un cluster mesh’i işe L3/L4 seviyesinde eBPF ile kernel içinde çözmeye çalışıyor ve overhead’i aşağı çekiyor. Az önce “daha sade” dedim ama aslında mesele sadece sade olmak değil; bazen daha az parça daha az baş ağrısı demek oluyor. Tabi observability ve ince policy kontrolü istiyorsanız Istio ya da Linkerd’i yanina koyabilirsiniz. Birbirini dışlamıyorlar.
Türkiye’deki Şirketler İçin Bu Ne Anlama Geliyor?
Açık konuşayım, Türkiye’de multi-cluster ihtiyacı son 2-3 yılda baya arttı. Neden mi? Birkaç sebep var, ama işin aslı tek bir cümleye sığmıyor; KVKK baskısı, regülasyonlar, maliyet hesabı ve bazen de ekiplerin “tek cluster yetiyor mu acaba?” diye kendi kendine sorması bu işi öne çekti.
- KVKK ve veri ikamet zorunlulukları: Bazı verilerin Türkiye’deki region’da kalması gerekiyor, bazı global servisler işe West Europe veya North Europe’da duruyor. Bu tabloyu yan yana koyunca, olay otomatik olarak çoklu cluster tarafına kayıyor; yani tek kümeyle yürümek bazen idare eder ama her zaman değil. (bu kritik)
- BDDK ve finansal düzenlemeler: Banka müşterilerimde DR cluster’ı çoğu zaman zorunluluk gibi geliyor. Aktif-aktif kurulumlar var tabii, ama açık söyleyeyim, aktif-pasif yapılar hâlâ daha sık karşımıza çıkıyor ve bazen bu tercih teknikten çok operasyonel rahatlık yüzünden oluyor.
- Maliyet optimizasyonu: Bazı workload’ları daha ucuz region’a kaydırmak için fleet yaklaşımı düşünmek gerekiyor. Hani ilk bakışta “bu kadar uğraşa değer mi?” diyorsun, sonra faturayı görünce fikir değişiyor; özellikle sabit yükü olan servislerde bu model fena iş görmüyor. — ciddi fark yaratıyor
Şimdi kurumsal tarafta gördüğüm şey şu: Türkiye’de bu teknolojinin benimsenmesi biraz kıvrımlı ilerleyecek. Çünkü pek çok şirket hâlâ tek cluster içinde namespace izolasyonuyla yol alıyor, bu da kötü değil aslında. Cross-cluster networking konuşmaya başlamadan önce “neden multi-cluster?” sorusuna net cevap vermek şart. Aksi hâlde sırf yeni bir özellik var diye karmaşıklığı büyütmenin pek anlamı kalmıyor.
Çok konuştum, örnekle göstereyim.
Eh, Bir de şu detay var: Türkiye’de Azure region’ı henüz GA değil (bu yazıyı yazdığım sırada hâlâ planlama aşamasında). Yani şu an cross-cluster senaryosu büyük ihtimalle West Europe + North Europe ya da West Europe + Germany West Central gibi kombinasyonlara dayanacak. Latency hesabını buna göre yapmak lazım; düşük single-digit milisaniyeleri beklemeyin, genelde 15-25 ms civarı dolaşıyor, bazen biraz aşağı iner. Çok da hayal kurmamak lazım.
Hangi Senaryoda Gerçekten Işe Yarar?
Her şeyi cilalamadan önce, su soruyu net koymak lazım: hangi durumda is görüyor? Çünkü her takım için aynı tarif değil bu, bazen tam cuk oturuyor, bazen de sadece ekstra uğraş oluyor. Daha fazla bilgi için .NET MAUI Artık CoreCLR’da: Mono Devri Kapanıyor yazımıza bakabilirsiniz.
| Senaryo | Uygun mu? | Yorum |
|---|---|---|
| Tek cluster, namespace izolasyonu yetiyor | ❌ | Karmaşıklık eklemeyin |
| 2 region, aktif-pasif DR | ✅ | Failover senaryosu için ideal |
| 3+ cluster, aktif-aktif, region bazlı trafik | ✅✅ | En çok faydayı burada görürsünüz |
| Hybrid (on-prem + Azure) | ⚠️ | Preview’da AKS odaklı, on-prem için Arc gerek |
| Dev/test/prod ayrı cluster’larda | ⚠️ | Aşırı mühendislik olabilir |
| Shared services (Redis, Kafka) merkezî cluster’da | ✅ | Klasik hub-spoke deseni için biçilmis kaftan, hele servisler birbiriyle sürekli konuşuyorsa bayağı iş görüyor. |
Evet. Bu konuyla ilgili saha konusundaki yazımız yazımıza da göz atmanızı tavsiye ederim.
Geçen ay bir e-ticaret musterimizle bunu konuşurken aklıma ilk gelen şey su oldu: bunların derdi aslında tabloyun son satırına cuk diye oturuyordu. Merkezî bir shared services cluster var; Redis cache orada, message broker orada, observability stack de orada (yani her şey tek yerde toplanmış), diğer 6 cluster da durmadan buraya dokunuyor. Şimdi Private Endpoint ile idare ediyorlar ama açık söyleyeyim, bakım tarafı biraz yorucu (bu beni çok şaşırttı). Cross-cluster networking’e gecebilirlerse servis discovery ve routing işleri hafifler; hesap-kitap kısmını da önümüzdeki ay birlikte netlestirecegiz (şaşırtıcı ama gerçek)
İşte tam da bu noktada devreye giriyor. Bu konuyla ilgili .NET ve .NET Framework Mayıs 2026 Güncellemeleri: Saha yazımıza da göz atmanızı tavsiye ederim.
Küçük Ekip vs Enterprise: Farklı Yaklaşımlar
Aslında, Küçük bir startup’sanız ve elinizde 2 cluster varsa, hani çok dolandirmaya gerek yok — büyük ihtimalle buna ihtiyacınız yok. Application Gateway ya da düz bir Front Door kurulumu işi çoğu zaman götürüyor; cross-cluster networking işe bazen faydadan çok operasyon yükü bindiriyor, sahiden.
Yani, Ama enterprise tarafındaysanız, 10+ cluster yönetiyorsanız ve platform ekibi Fleet Manager’i zaten ceviriyorsa — bak şimdi — denemeye değer. Çünkü burada kazanç tek tek özelliklerden gelmiyor; asıl olay bütünleşik bir platform, biraz garip gelebilir. Mesele tam olarak bu. Workload propagation ile update orchestration’u cross-cluster networking’e ekleyince, ortaya “fleet as a single unit” hissi çıkıyor. Parçaları tek tek değil de topluca oynatabiliyorsunuz. Bu konuyla ilgili GA4’ü Bırakıp Next.js + Supabase’e Geçmek: Neden? yazımıza da göz atmanızı tavsiye ederim.
Kısa bir not düşeyim buraya.
Tam da öyle. Bu konuyla ilgili Docker İmajını Küçültmek: 1,58 GB’dan 186 MB’a yazımıza da göz atmanızı tavsiye ederim.
Neyse uzatmayalım, özetle konu şu: az cluster’la çalışıyorsanız sade kalmak daha mantıklı olabilir. Yapı büyüdükçe bu yaklaşım baya yerini buluyor. Siz ne dersiniz?
Sahada Başlamak: Pratik İlk Adımlar
Tamam, ikna oldunuz diyelim. Peki sonra? Ben kendi POC’ta işi şöyle çevirdim, biraz da mecbur kaldım açıkçası: (ki bu çoğu kişinin gözünden kaçıyor)
- Önce Fleet Manager’ı kurun: Eğer daha kurmadıysanız, iş tek bir
az fleet createkomutuyla başlıyor. Hub cluster opsiyonel, ben açık bıraktım çünkü Kubefleet tarafında merkez fikri var ya, onsuz biraz havada kalıyor. - Member cluster’ları join edin: Mevcut AKS cluster’larınızı fleet’e ekliyorsunuz. Burada küçük ama önemli bir detay var: Cilium dataplane’i destekleyen cluster’lar lazım. Yeni kurulumda Azure CNI Powered by Cilium seçmek baya iş görüyor.
- Advanced Container Networking Services’i etkinleştirin: Cross-cluster tarafı bunun üstüne oturuyor. Add-on olarak geliyor, yani ayrıca başka bir yerden icat etmiyorsunuz.
- CIDR planlamasını ciddiye alın: Bence en hayatı kısım bu. Cluster pod CIDR’ları çakışırsa işler karışıyor, hatta dümdüz kilitleniyor. Önceden oturup plan yapmak şart.
- Service export/import primitive’lerini öğrenin: Hangi servisin fleet seviyesinde görünür olacağına siz karar veriyorsunuz. Her servis otomatik export edilmiyor, iyi ki de edilmiyor; yoksa ortalık gereksiz kalabalık olurdu. (bence en önemlisi)
Örnek bir service export tanımı aşağı yukarı şöyle duruyor:
apiVersion: networking.fleet.azure.com/v1alpha1
kind: ServiceExport
metadata:
name: payment-api
namespace: production
spec:
# Bu servisi fleet'teki diğer cluster'lara aç
type: ClusterSetIP
Şöyle ki, Diğer cluster’dan bu servise payment-api.production.svc.clusterset.local gibi bir isimle ulaşıyorsunuz. Yani klasik cluster.local‘ın yanina yeni bir DNS suffix geliyor, olay bu kadar basit ama ilk bakışta insanı bir an durduruyor.
Eksik ya da Endişe Verici Bulduklarım
Şimdi işin biraz can sıkan tarafına gelelim. Her şey güllük gülistanlık değil, yani preview kısmında bazı parçalar hâlâ tam yerine oturmamış duruyor.
Birinçisi, observability tarafı henüz biraz ham. Cilium Hubble entegrasyonu var, evet, ama fleet seviyesinde “hangi cluster’dan hangi cluster’a ne kadar trafik akıyor” sorusuna net cevap almak için ekstra ayar yapmanız gerekiyor; bu da production’a geçerken insanın moralini azıcık bozuyor, çünkü bakıyorsunuz özellik var gibi duruyor ama pratikte birkaç adım daha istiyor.
Bi saniye — İkincisi, policy yönetimi. Cluster’lar arası NetworkPolicy uygulaması hâlâ deneme gibi davranıyor. Tek cluster içinde policy yazmak tamam, alıştık buna. Ama “X cluster’ından gelen trafiği sadece Y namespace’inden gelirse kabul et” gibi kuralları yazmaya kalkınca iş bir anda sertleşiyor; Kubernetes v1.36: Silinemeyen Admission Politikaları Dönemi yazımda bahsettiğim ValidatingAdmissionPolicy benzeri yeni mekanizmaların fleet seviyesinde nasıl davranacağı da açıkçası ayrı bir soru işareti olarak duruyor.
Üçüncüsü, maliyet şeffaflığı. Public preview’da fiyat konusu hâlâ netleşmiş değil. Advanced Container Networking Services’in standart bir bedeli var, tamam. Cross-cluster özelliği için ayrıca bir kalem çıkar mı, çıkarsa nasıl hesaplanır — işte burada biraz beklemek gerekiyor, çünkü GA’ya kadar bunun berraklaşmasını görmek istiyorum. Müşteriye “hadi deneyelim” derken bütçe tarafını da omzuma almak zorundayım.
Evet.
Alternatifler: Tek Yol Bu Değil
Yani, Adil olmak lazım, cross-cluster networking işini tek bir yolla çözmüyorsunuz. Hangisi size uyar, biraz da senaryoya bağlı; yani bazen sade olan yetiyor, bazen de “yok abi burada daha başka bir şey lazım” deyip farklı tarafa dönüyorsunuz.
- Istio multi-cluster mesh: L7 tarafında epey şey yapıyor, ama sidecar overhead’i de var. Olgun bir teknoloji, önü da teslim etmek lazım.
- Linkerd multi-cluster: Daha hafif gidiyor, konfigürasyonu da daha az yoruyor. mTLS zaten varsayılan açık, bu kısım fena değil.
- Submariner: CNCF projesi, multi-cluster connectivity için açık kaynak bir seçenek. Cluster mesh’e alternatif olarak düşünebilirsiniz.
- Azure Front Door + Private Endpoint: Eğer L7 routing işinizi görüyorsa ve E-W trafik ihtiyacı düşükse, bu kombinasyon gayet yeterli olabilir. Hani her probleme mesh şart değil ya, işte o durum.
Araya gireyim: Bence Fleet Manager + Cilium tarafının asıl artısı şu: ayrı ayrı parçalarla uğraşmak yerine Azure-native bir paket veriyor. Eğer zaten Azure ekosistemindeyseniz ve Fleet Manager kullanıyorsanız, bu baya doğal bir devam gibi duruyor; hatta ilk bakışta “tamam, bu oturur” dedirtiyor. Ama dür bir saniye — eğer multi-cloud bir yapınız varsa, native Cilium cluster mesh’i kendiniz kurmak daha esnek de olabilir. Trade-off bu, net.
Sıkça Sorulan Sorular
Cross-cluster networking için Cilium şart mı?
Şu an public preview’da kısaca evet, dataplane Cilium tabanlı çalışıyor. Yani Azure CNI Powered by Cilium ile cluster oluşturmanız gerekiyor (bizzat test ettim). Kube-proxy’siz modu tercih edin, aslında performans farkı orada oldukça belirgin.
Mevcut AKS cluster’ımı Fleet Manager’a ekleyebilir mıyım?
Evet, member cluster olarak join edebilirsiniz (ki bu çoğu kişinin gözünden kaçıyor). Ama cross-cluster networking özelliği için cluster’ın Cilium dataplane’ını desteklemesi lazım. Eski kubenet veya standart Azure CNI kullananları muhtemelen migrate etmeniz gerekecek — açıkçası bu biraz can sıkıcı bir adım.
Pod CIDR çakışmalarını nasıl yönetiyor?
Cluster mesh modunda her cluster’ın benzersiz pod CIDR’ları olması şart. Çakışma varsa routing direkt bozuluyor. Bence fleet kurmaya başlamadan önce IP planlamasını merkezî yapın — hani Excel’de bile olsa bir CIDR allocation tablosu tutun, sonradan çok işe yarıyor.
Service mesh’e (mesela Istio) hâlâ gerek var mı?
Duruma göre değişiyor. Sadece L3/L4 connectivity ve servis discovery yeterliyse cross-cluster networking tek başına iş görüyor. Ama fine-grained traffic management, retry/timeout policy’leri, distributed tracing veya detaylı authz gerekiyorsa mesh hâlâ değerini koruyor. Tecrübeme göre ikisini birlikte kullanmak da gayet mümkün.
Production’a alabilir mıyım?
Size bir şey söyleyeyim, Public preview olduğu için Microsoft kritik production workload’ları önermez, ben de önermem açıkçası. Önce DR cluster’ı veya internal tooling gibi düşük riskli senaryolarda deneyin. GA’yı bekleyip fiyatlandırma netleştikten sonra production’a almak çok daha sağlıklı ölür.
Kaynaklar ve İleri Okuma
Microsoft Azure Blog — Cross-cluster networking duyurusu
Dürüst olmak gerekirse, Azure Kubernetes Fleet Manager Resmî Dokümantasyonu
Açıkçası, Cilium Cluster Mesh Dokümantasyonu (en azından benim deneyimim böyle)
Kendi deneyimimden konuşuyorum, Kubefleet GitHub Reposu

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



