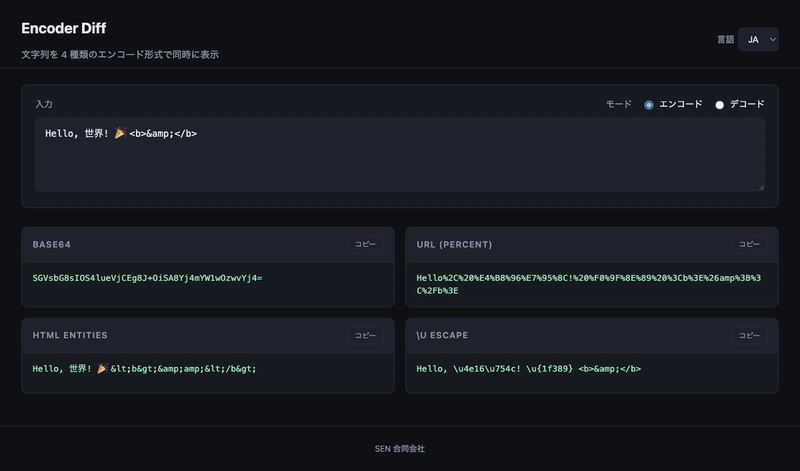
Bir metni “kodladım” deyip geçiyoruz ya… İşin aslı şu ki, web tarafında bu kelime bayağı kaygan. Base64 başka bir dert, URL encoding başka bir dert, HTML entity bambaşka bir dert. Ben bunu ilk kez 2011’de İstanbul’da bir form doğrulama işinde fark etmiştim; kullanıcı adı içinde Türkçe karakter çıkınca sistem bir anda saçmalamıştı (ben de ilk duyduğumda şaşırmıştım). O gün bugündür, bu üçlüye aynı gözle bakmam.
İlginç olan şu ki, Editör masasında bu konuyu tekrar görünce hemen not aldım. Çünkü pratikte insanlar bunları karıştırıyor, sonra da “neden bu karakter bozuldu?” diye saatlerce uğraşıyor. Açık konuşayım: mesele teoriden çok görerek öğrenince oturuyor. Yan yana görünce taşlar yerine geliyor (ciddiyim). Tek tek anlatınca işe kafa dağılıyor.
Neden Bu Dört Kodlama Hep Karışıyor?
İnternette günlük hayatta en sık karşılaştığımız şeylerden biri aslında karakter dönüşümü. Ama çoğu geliştirici bunu soyut bir konu gibi görüyor — hani o “bir yerde bir şey eksik” hissi vardır ya, tam o nokta. Mesela API’den dönen veride bir emoji bozulunca sorun backend sanılıyor, halbuki suçlu çoğu zaman yanlış encode/decode adımı oluyor.
Ben kendi küçük yan projemde, 2024’ün başında Ankara’da çalışırken benzer bir hata yakalamıştım. Formdan gelen veri URL-encoded sanılıyordu ama aslında HTML entity olarak kaçırılmıştı; sonuçta kullanıcı adı alanında < gibi garip şeyler görünüyordu ve insanın gözüne batıyordu, küçük kriz ama sınır bozucu işte (ilk duyduğumda inanamadım)
Yani, Bu yüzden yan yana çalışan araçlar baya işe yarıyor. Beynimiz farkı tablo gibi görüyor; satır satır açıklama bazen yetmiyor. Bir input yazıyorsun, dört farklı sonuç çıkıyor ve anlıyorsun: “Aa tamam, bunlar aynı aileden değilmiş.”
Base64 Neden İlk Bakışta Masum Görünüyor?
Base64’ün hikâyesi biraz tuhaf. Dışarıdan bakınca düz bir metni alıp harflere dönüştürüyor gibi duruyor — ama amaç aslında ASCII dostu bir paket yapmak. Yani e-posta ekleri, JSON içinde ikili veri taşımak ya da bazı eski sistemlerle uyum sağlamak için kullanılıyor. Kulağa basit geliyor. Ama tarayıcı tarafında ufak bir pürüz var: JavaScript’in yerleşik btoa() fonksiyonu UTF-8’i doğrudan sevmiyor (evet, doğru duydunuz)
Bunu 2023 yazında Kadıköy’de yaptığım mini demo uygulamasında yüzüme tokat gibi yemiştim diyebilirim. btoa('') yazınca patlaması ilk anda saçma geliyor ama mantığı şu: önce UTF-8 baytlarına çevirmen gerekiyor, sonra o baytları sanki tek baytmış gibi Base64’e sokuyorsun. Biraz dolambaçlı… Hani ne farkı var diyorsunuz, değil mi? evet.
Bakın, Aşağıdaki akış tam da bunu anlatıyor:
// Basitleştirilmiş akış
metin → UTF-8 baytları → sahte binary string → btoa() → Base64
// Ters yön
Base64 → atob() → binary string → byte dizisi → TextDecoder() → metin
Güzel tarafı şu: bu yapıyı öğrenince üçüncü parti kütüphane bağımlılığına mecbur kalmıyorsun. Kötü tarafı işe hata ayıklarken — ki bu tartışılır — insanı uğraştırması — özellikle strict mode’a geçmediyseniz bozuk UTF-8 parçaları sessizce U+FFFD’ye dönüşebiliyor, yani sistem “ben hallettim” havası yapıyor. Gerçekte veri çoktan yamulmuş oluyor.
Bence En Büyük Tuzak Burada
Base64 şifreleme değil. Bunu özellikle ayırmak lazım çünkü birçok ekip hâlâ bunu güvenlik katmanı sanıyor; hayal kırıklığı tam orada başlıyor. Base64 sadece temsil biçimini değiştiriyor, başka bir şey değil.
Küçük startup ortamında bu detay gözden kaçıyor. Herkes hızlı koşuyor, kimse dokümantasyon okumak istemiyor — itiraf edelim. Kurumsal tarafta işe farklı: entegrasyon ekipleri genelde kuralları biliyor ama legacy sistemler yüzünden yine aynı çile dönüyor. Maalesef.
URL Encoding: Asıl Hikâye Baytlarda Saklı
URL encoding denince çoğu kişinin aklına sadece boşlukların %20 olması geliyor. Oysa mesele bundan çok daha geniş; encodeURIComponent() metni alıp UTF-8 baytlarına çeviriyor. Her baytı %XX şeklinde dışarı veriyor, bu yüzden Japonca bir karakter üç ayrı parça gibi görünebiliyor.
| Kodlama Türü | Aynı Karakterde Ne Ölür? | Dikkat Noktası |
|---|---|---|
| Base64 | Metin baytlara paketlenir | btoa/atob UTF-8 konusunda nazlıdır |
| URL Percent-Encoding | %XX dizisine dönüşür | Tam olmayan bayt dizileri URIError verir |
| HTML Entity | &, <, ” gibi kaçırılır | XSS önleme ile doğrudan bağlantılıdır |
| Unicode Escape | \uXXXX ya da \u{…} | Pencereyi kapatmadan önce formatı iyi seçmek gerekir |
Bunu test ederken en çok hoşuma giden şey şuydu: yarım kalmış URL kodunu yapıştırınca ilgili kartın hemen kızarması. Hata nerede diye tahmin yürütmüyorsun artık, direkt görüyorsun. Editör gözüyle konuşayım, bu tür görsel geri bildirimler hem öğretici hem de sınır bozucu hataları hızla yüze vuruyor.
Neyse uzatmayayım. URL encoding’in güzelliği hızından geliyor ama eksisi de tam burada saklı: yarım veriyle çalışmayı hiç affetmiyor. Bir karakter bile eksikse iş bozuluyor ve tarayıcı bunu sessizce geçmiyor.
HTML Entities: Güvenlik İçin Gerekli Ama Her Zaman Temiz Değil
HTML entity konusu genelde güvenlik konuşulurken masaya geliyor. Çünkü sayfada düz metin olarak gösterilmesi gereken şeylerin HTML etiketi sanılmaması gerekiyor; mesela ampersand için &, küçük işaret için <, çift tırnak için de çeşitli entity biçimleri var. Bu konuyla ilgili Ekranı Dinleyen Yerel Yapay Zekâ: Bulutsuz Okuma Dönemi yazımıza da göz atmanızı tavsiye ederim.
Ama burada ince bir çizgi var. Her şeyi entity’ye çevirmek çözüm değil, bazen gereksiz karmaşa yaratıyor. Geçen sene İzmir’de birlikte çalıştığım bir tasarımcı arkadaşımın elindeki içerik sistemi bunu fazla abartmıştı; editör ekranı okunmaz hâle gelmişti çünkü kullanıcılar sürekli kaçış karakterleriyle boğuşuyordu. Siz hiç denediniz mi? Sınır bozucu. Daha fazla bilgi için Kod Yazmaktan Kaçınırken: Yapay Zekâ Çağında Mühendislik yazımıza bakabilirsiniz.
Nerede İşe Yarar?
- Kullanıcıdan gelen içeriği güvenli şekilde göstermek istediğinde. — ciddi fark yaratıyor
- XSS riskini azaltmak için çıktı katmanında metni kaçırırken. (bence en önemlisi)
- E-posta şablonlarında veya eski CMS’lerde özel karakterleri korumak için.
Ama dürüst olayım: HTML entity’yi yalnız başına kurtarıcı sanmak biraz tembellik ölür. Doğru bağlamda kullanırsan işini görür, yanlış yerdeyse sana yeni sorunlar üretir. Hele bir de içerik yönetim sistemlerinde hem editör hem önizleme hem yayın katmanı ayrı ayrı düşünülmeli — biri atlanırsa geri kalanı zaten anlamsız kalıyor.
Bir dakika — bununla bitmedi.
Karışıklığın özü şu: Base64 taşıma biçimi ister, URL encoding yolculuk biçimi ister, HTML entity işe tarayıcının yorumlamasını kontrol eder.
Ters Çevirme Modu Neden Aslında — hayır dür, daha doğrusu Daha Öğretici?
Ne yalan söyleyeyim, Bence iyi araçlar sadece encode etmeyi değil, decode etmeyi de gösterir. Hatta bazen ters yön daha öğretici çünkü — ki bu tartışılır — hatayı orada çok daha net görüyorsun. Bir input’u decode ettiğinde “bu neden patladı?” sorusu aniden somutlaşıyor ve teori ezberlemekten kurtuluyorsun. Agent’ler Ödeme Yaparken Kim Dür Diyecek?: Güvenlik Açığı yazımızda bu konuya da değinmiştik.
SEN LLC’nın yaptığı araçta hoşuma giden kısım tam da buydu: dört kart aynı anda dönüyor. Hata olan kart kırmızıya boyaniyor. Küçük proje için sade ama yeterli. Enterprise seviyede loglama ve geçmiş giriş takibi gibi şeyler eklenirse tadından yenmezdi — ama ham hâliyle bile işini görüyor.
Bir de şunu söyleyeyim: UI sade kaldığında öğrenme hızı artıyor. Kalabalık arayüzler bazen bilgi vermekten çok gürültü üretiyor (bizzat test ettim). Bu kadar basit yani.
Kimin İçin Daha Faydalı?
Küçük bir detay: Küçük ekiplerde yeni başlayanlara farkları öğretmek için birebir. Kurumsal yapılarda işe destek ekiplerinin hızlı teşhis yapmasına yardım ediyor. Tek kişilik projelerde bile debug süresini ciddi azaltabiliyor.
Şimdi, i̇lginç olan şu ki, Ama tabii ham hâliyle raporlama kısmı zayıf kalabiliyor — yani kullanım alanını doğru seçmek lazım. Bakın, kritik nokta şu: eğer hedefiniz yalnızca “dönüştür” butonuysa basit araç yeter. Ama hata izlemek istiyorsanız durum değişiyor; orada geçmiş değerler, strict decoding seçenekleri ve örnek girdiler önemli hâle geliyor. Yoksa güzel fikir pratikte biraz sönük kalabiliyor. MCP’nın Kör Noktası: 10 API, 300 Tehlikeli Tuş yazımızda da bu konuya değinmiştik. Fransa Windows’tan Uzaklaşıyor: Linux Hamlesi Ne Anlatıyor? yazımızda da bu konuya değinmiştik.
Kendi Çalışma Akışıma Nasıl Oturdu?
İnanın, Açık konuşayım: ben böyle araçları en çok iki durumda kullanıyorum. Birinçisi blog yazısı hazırlarken, ikincisi API cevabı niye bozuldu diye gece yarısı kurcalarken. Geçen ay Bursa’da uzaktan çalışırken tam da böyle oldu; Slack mesajındaki link yanlış encode edilmişti. Kullanıcı tıklayınca bambaşka bir sayfa açılıyordu.
Araya gireyim: Böyle anlarda yan yana karşılaştırmalı ekran hayat kurtarıyor çünkü tahmin yürütmeyi azaltıyor. Dür bir saniye — aslında mesele sadece kodlama değil, karşılaştırma psikolojisi de var burada. İnsan gözü farklılıkları çok hızlı seçiyor; tek panelde görünmeyeni üç panelde hemen yakalıyorsun. Bu kadar.
İşte tam da bu noktada devreye giriyor.
Sıkça Sorulan Sorular
Base64 ile şifreleme aynı şey mi?
Hayır, aynı şey değil. Base64 yalnızca veriyi başka bir gösterime çevirir; gizlemez ya da korumaz. Güvenlik istiyorsanız ayrıca şifreleme kullanmanız gerekir.
encodeURIComponent neden bazı karakterlerde hata verir?
Tam olmayan veya bozuk UTF-8 dizileriyle karşılaşınca hata verebilir. Mesela yüzde işaretiyle başlayan eksik parçalar URIError üretir.
HTML entity ne zaman kullanılmalı?
User-generated content’i sayfada güvenle göstermek istediğinizde kullanılmalı. Hele bir de `<`, `>` ve `&` gibi karakterlerin tarayıcı tarafından etiket sanılmasını engeller.
\u{1f389} ile Ἰ9 arasında ne fark var?
\u{1f389} modern JavaScript’te doğru Unicode escape biçimidir. Ἰ9 işe eski tarz altıgen olmayan kullanım yüzünden beklediğiniz sonucu vermeyebilir.
Kayn naklar ve İleri Okuma
}

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.



